K-Means属于非监督分类,在数据聚类中是相对容易也是非常经典的算法。通常用在大量数据需要进行分类的时候。K表示要把数据分类K类。
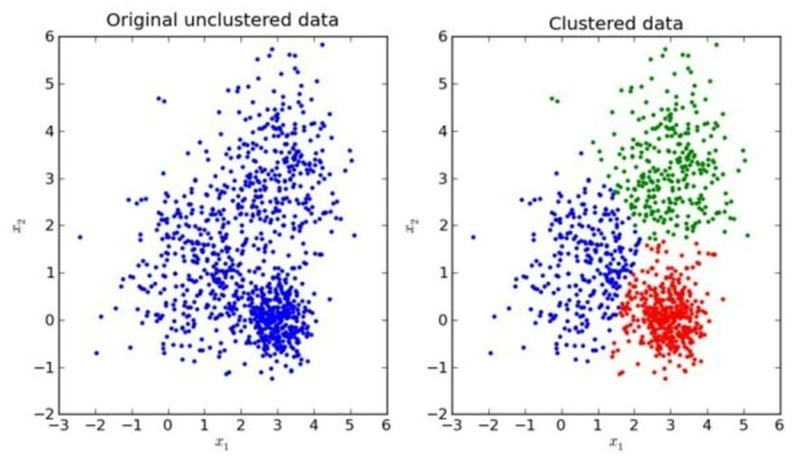
其计算步骤为(以K=3为例):
1、随机在数据当中抽取3个样本,当做三个类别的中心点(绿、红、蓝)。
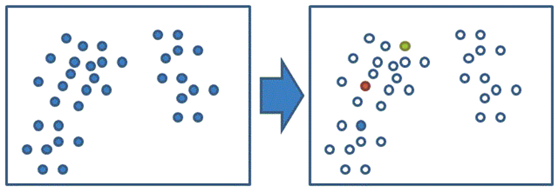
2、其次,计算其余的点分别到这三个中心点的距离,这样每一个样本都会有三个距离,从中选出距离(欧式距离)最近的一个点最为自己的标记,形成三个族群。
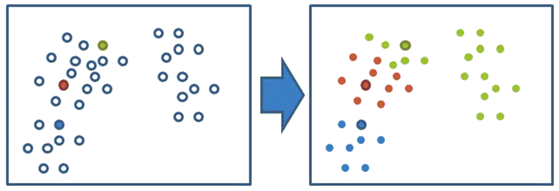
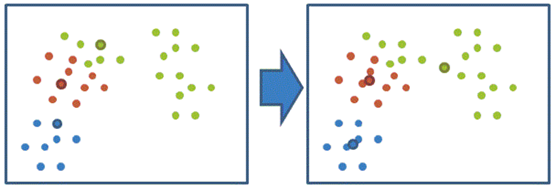
3、然后,分别计算这三个族群的平均值,例如:A(x1,y1),B(x2,y2)两个点的平均值为((x1+x2)/2, (y1+y2)/2)。把三个平均值与之前的三个旧中心点比较,如果都相同,那么久结束聚类;如果不相同,把这三个平均值当做新的中心店,重复第二步。
API: sklearn.cluster.KMeans

评估标准:轮廓系数



API:

以python官方自带的数据集为例:
from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score from sklearn.datasets import load_digits def kmeans(): """ 手写数字聚类过程 :return: None """ ld = load_digits() print(ld.target[:20]) #进行聚类 km = KMeans(n_clusters= 8) km.fit_transform(ld.data) print(km.labels_[:20]) print('轮廓系数为:', silhouette_score(ld.data, km.labels_)) return None if __name__ == "__main__": kmeans()

最后轮廓系数大于0,应该算是不错的效果。
K-Means聚类方法的缺点应该比较明显,就是有一个超参数K,有时候在进行聚类时往往不知道K的值。