1、LIMIT 语句
表数据,千万

分页查询
SELECT * from tb_cus_fenrunglist limit 2000000,10
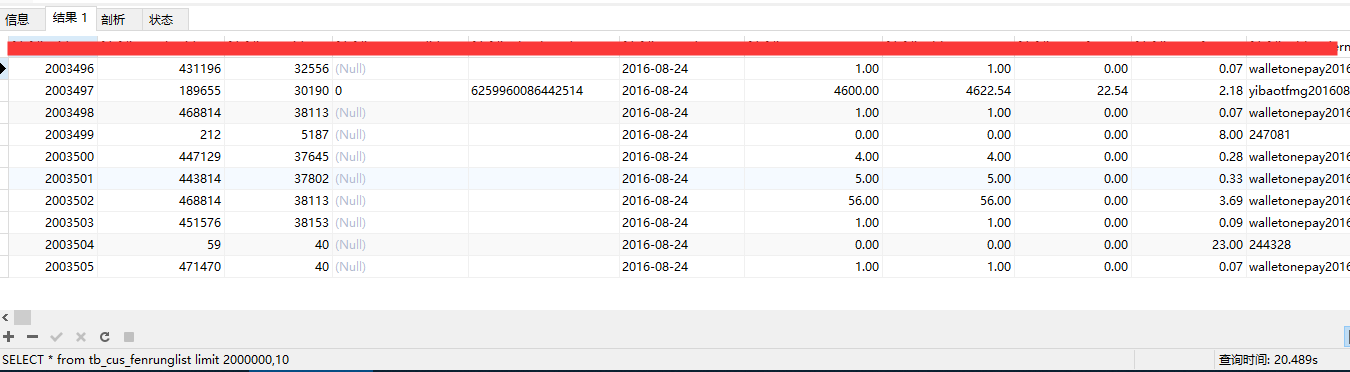
但当 LIMIT 子句变成 “LIMIT 2000000,10” 时,既然要使用20秒。
要知道数据库也并不知道第2000000条记录从什么地方开始,即使有索引也需要从头计算一次。出现这种性能问题,多数情形下是程序员偷懒了。
在我面试的时候,很多小伙伴都是说把上一页的数据,记录id或者时间,然后where去查询。而已我这边测试,这个方法并不可取。结果如下:
索引:
SELECT * from tb_cus_fenrunglist where fd_frlist_paydate > '2016-08-24' limit 2000000,10

如上图并不能解决,分页查询的问题
解决的方案:我之前分享过的一篇文章《mysql分页查询优化》
2、隐式转换
SQL语句中查询变量和字段定义类型不匹配是另一个常见的错误。例如
字段: 
索引:

其中字段 fd_frlist_paycardid 的定义为 varchar(200),MySQL 的策略是将字符串转换为数字之后再比较。函数作用于表字段,索引失效。
上述情况可能是应用程序框架自动填入的参数,而不是程序员的原意。现在应用框架很多很繁杂,使用方便的同时也小心它可能给自己挖坑。
3、混合排序
MySQL 不能利用索引进行混合排序。但在某些场景,还是有机会使用特殊方法提升性能的。
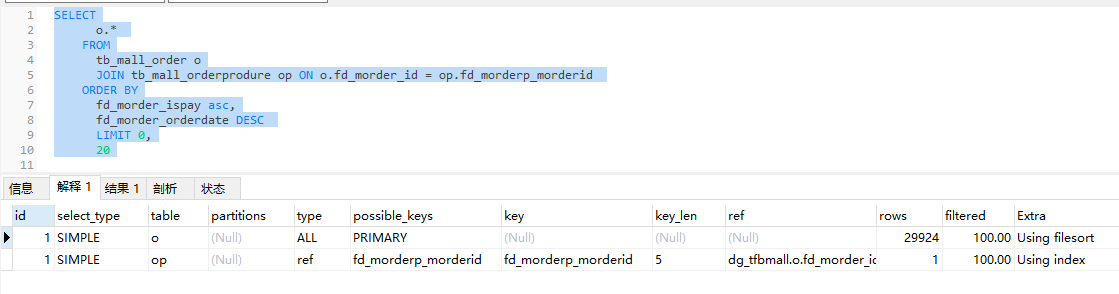
执行计划显示为全表扫描.
由于 fd_morder_ispay 只有0和1两种状态,我们按照下面的方法重写后。索引用上了。因表数据太少,效率的提升不太明显 从0.095秒 到 0.007秒

4、提前缩小范围(没索引的情况)
先上初始 SQL 语句:
SELECT o.*, a.* FROM tb_mall_order o JOIN tb_mall_orderprodure op ON o.fd_morder_id = op.fd_morderp_morderid LEFT JOIN tb_author a ON a.fd_author_id = o.fd_morder_authorid where fd_morder_ispay =1 ORDER BY fd_morder_ispaytime DESC LIMIT 0, 15

该SQL语句原意是:先做一系列的左连接,然后排序取前15条记录。从执行计划也可以看出,最后一步估算排序记录数为71万,时间消耗: 8.000s。
由于最后 WHERE 条件以及排序均针对最左主表,因此可以先对 tb_mall_order 排序提前缩小数据量再做左连接。SQL 重写后如下,执行时间缩小为1毫秒左右。
SELECT o.*, a.* FROM ( SELECT o.* FROM tb_mall_order o where fd_morder_ispay =1 ORDER BY fd_morder_ispaytime DESC LIMIT 0, 15 ) o JOIN tb_mall_orderprodure op ON o.fd_morder_id = op.fd_morderp_morderid LEFT JOIN tb_author a ON a.fd_author_id = o.fd_morder_authorid
再检查执行计划:子查询物化后(select_type=DERIVED)参与 JOIN。虽然估算行扫描仍然为71万,但是利用了索引以及 LIMIT 子句后,实际执行时间变得很小。

总结
数据库编译器产生执行计划,决定着SQL的实际执行方式。但是编译器只是尽力服务,所有数据库的编译器都不是尽善尽美的。
上述提到的多数场景,在其它数据库中也存在性能问题。了解数据库编译器的特性,才能避规其短处,写出高性能的SQL语句。
程序员在设计数据模型以及编写SQL语句时,要把算法的思想或意识带进来。
编写复杂SQL语句要养成使用 WITH 语句的习惯。简洁且思路清晰的SQL语句也能减小数据库的负担 。
