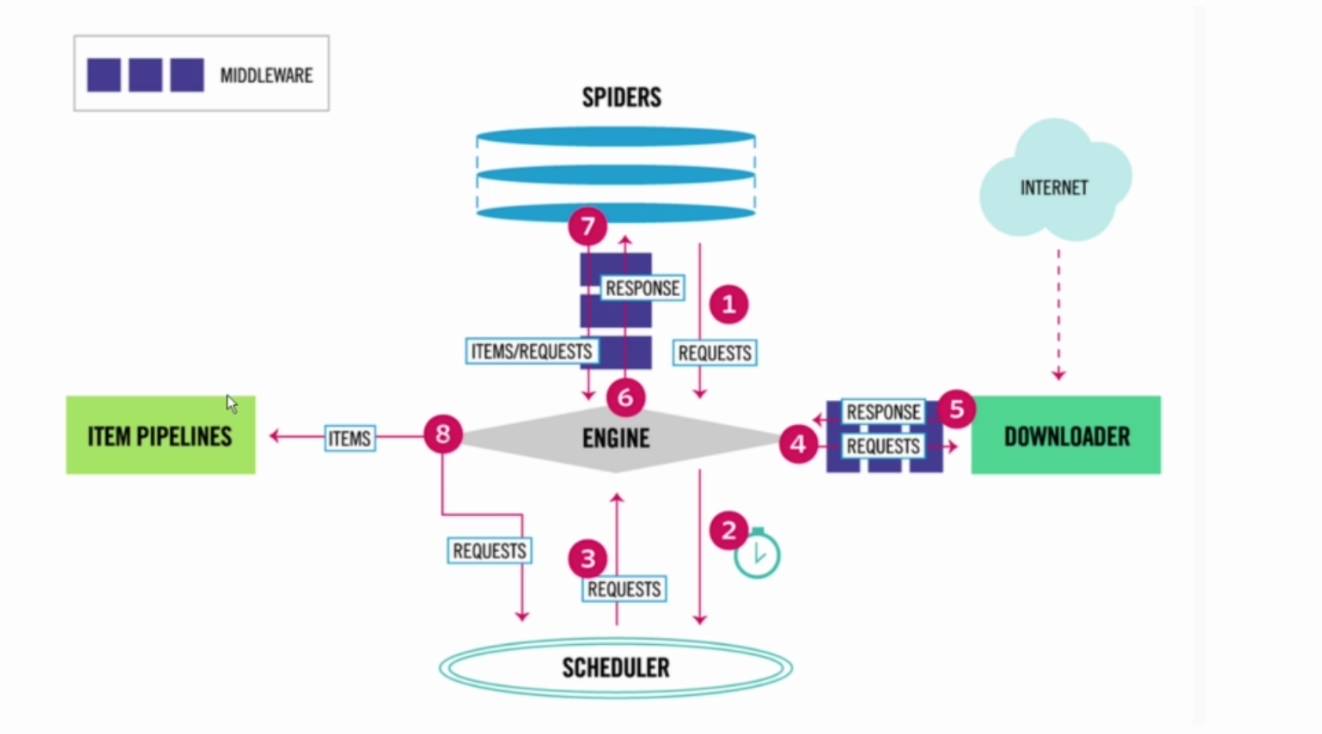
1.创建scrapy项目


scrapy startproject 项目名 cd 项目名 scrapy genspider chouti chouti.com 创建一个爬取抽屉的爬虫 scrapy genspider -t crawl cnblogs cnblogs.com 创建一个爬取博客的爬虫 scrapy crawl chouti 编写完成之后启动项目
2.项目中各个文件的作用介绍
项目名称 项目名称/ - spiders # 爬虫文件 - chouti.py - cnblgos.py .... - items.py # 持久化 - pipelines # 持久化 - middlewares.py # 中间件 - settings.py # 配置文件(爬虫) scrapy.cfg # 配置文件(部署)
3.项目实战地址,内有包含步骤说明和注释
https://github.com/yangyu57587720/qsbk_spider