Stream 流可以说是 Java8 新特性中用起来最爽的一个功能了,有了它,从此操作集合告别繁琐的for循环。与IO流不是一个概念。
Java8 Stream 使用的是函数式编程模式,如同它的名字一样,它可以被用来对集合进行链状流式的操作。
循环遍历的弊端:
for循环的语法就是“怎么做”
for循环的循环体才是“做什么”
为什么使用循环?
因为要进行遍历,但循环是变量的唯一方式吗?遍历是指每一个元素逐一进行处理,而并不是从第一个到最后一个顺次处理的循环。前者是目的,后者是方式。
import java.util.ArrayList;
import java.util.List;
public class Demo01List {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
// 对list集合中的元素进行过滤,只要以张开头的元素,存储到一个新的集合中
List<String> listA = new ArrayList<>();
for (String s : list) {
if (s.startsWith("张")) {
listA.add(s);
}
}
// 对listA集合进行过滤,只要姓名长度为3的人,存储到一个新集合中
List<String> listB = new ArrayList<>();
for (String s : listA) {
if (s.length() == 3) {
listB.add(s);
}
}
// 遍历listB集合
for (String s : listB) {
System.out.println(s);
}
}
}
这段代码含有三个循环,每一个作用不同:
(1)首先循环所有姓张的人;
(2)然后筛选名字有三个字的人;
(3)最后进行对结果打印输出。
每当我们需要对集合中的元素进行操作的时候,总是需要进行循环,循环,再循环。这是理所当然的吗?不是,循环是做事情的方式,而不是目的。另一方面,使用线性循环就意味着只能遍历一次。如果希望再次遍历,只能再使用另一个循环从头开始。
使用Stream流的方式,遍历集合,对集合中的数据进行过滤,Stream流是JDK1.8之后出现的,关注的是做什么,而不是怎么做。
import java.util.ArrayList;
import java.util.List;
public class Demo02Stream {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.stream()
.filter(name -> name.startsWith("张"))
.filter(name -> name.length() == 3)
.forEach(System.out::println);
}
}
1.Stream流是如何工作的
流表示包含着一系列元素的集合,我们可以对其做不同类型的操作,用来对这些元素执行计算。
Stream流其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值)
Stream流是一个来自数据源的元素队列
- 元素是特定类型的对象,形成一个队列。Java中的Stream并不会存储元素,而是按需计算
- 数据源 流的来源,可以是集合,数组等。
package com.company.service;
import java.util.Arrays;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> myList = Arrays.asList("a1", "a2", "b1", "c2", "c1");
myList
.stream() // 创建流
.filter(s -> s.startsWith("c")) // 执行过滤,过滤出以c为前缀的字符串
.map(String::toUpperCase) // 转换成大写
.sorted() // 排序
.forEach(System.out::println); // for循环打印
}
}
运行结果:
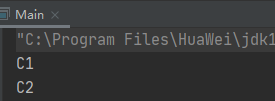
我们可以对流进行中间操作或者终端操作。
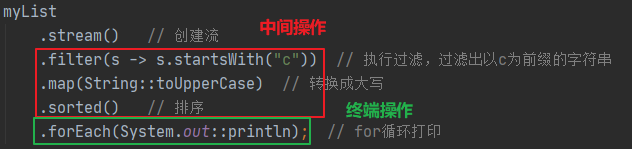
- 中间操作会再次返回一个流,所以,我们可以链接多个中间操作,注意这里是不用加分号的。上图中的filter过滤,map对象转换,sorted排序,就属于中间操作。
- 终端操作是对流操作的一个结束动作,一般返回void或者一个非流的结果。上图中的forEach循环就是一个终止操作。
看完上面的操作,感觉是不是很像一个流水线式操作呢。
实际上,大部分流操作都支持 lambda 表达式作为参数,正确理解,应该说是接受一个函数式接口的实现作为参数。
当使用一个流的时候,通常包括三个步骤:获取一个数据源(source)---> 数据转换 ---> 执行操作获取想要的结果,每次转换原有的Stream对象不改变,返回一个新的Stream对象(可以有多次转换),这允许对其操作可以像链条一样排列,变成一个管道。
2.不同类型的Stream流
我们可以从各种数据源中创建 Stream 流,其中以 Collection 集合最为常见。如
List 和 Set 均支持 stream() 方法来创建顺序流或者是并行流。- 顺序流
原始类型流
Arrays.asList("a1", "a2", "a3")
.stream() // 创建流
.findFirst() // 找到第一个元素
.ifPresent(System.out::println); // 如果存在,即输出
// a1
在集合上调用stream()方法会返回一个普通的 Stream 流。但是, 您大可不必刻意地创建一个集合,再通过集合来获取 Stream 流,您还可以通过如下这种方式:
常规对象流
Stream.of("a1", "a2", "a3")
.findFirst()
.ifPresent(System.out::println); // a1
例如上面这样,我们可以通过 Stream.of() 从一堆对象中创建 Stream 流(对象流)。
除了常规对象流之外,Java 8还附带了一些特殊类型的流,用于处理原始数据类型int,long以及double。说道这里,你可能已经猜到了它们就是IntStream,LongStream还有DoubleStream。
其中,IntStreams.range()方法还可以被用来取代常规的 for 循环, 如下所示:
IntStream.range(1, 4)
.forEach(System.out::println); // 相当于 for (int i = 1; i < 4; i++) {}
// 1
// 2
// 3
上面这些原始类型流的工作方式与常规对象流基本是一样的,但还是略微存在一些区别:
-
原始类型流使用其独有的函数式接口,例如
IntFunction代替Function,IntPredicate代替Predicate。 -
原始类型流支持额外的终端聚合操作,
sum()以及average(),如下所示:
Arrays.stream(new int[] {1, 2, 3})
.map(n -> 2 * n + 1) // 对数值中的每个对象执行 2*n + 1 操作
.average() // 求平均值
.ifPresent(System.out::println); // 如果值不为空,则输出
// 5.0
但是,偶尔我们也有这种需求,需要将常规对象流转换为原始类型流,这个时候,中间操作 mapToInt(),mapToLong() 以及mapToDouble就派上用场了:
Stream.of("a1", "a2", "a3")
.map(s -> s.substring(1)) // 对每个字符串元素从下标1位置开始截取
.mapToInt(Integer::parseInt) // 转成 int 基础类型类型流
.max() // 取最大值
.ifPresent(System.out::println); // 不为空则输出
// 3
如果说,您需要将原始类型流装换成对象流,您可以使用 mapToObj()来达到目的:
IntStream.range(1, 4)
.mapToObj(i -> "a" + i) // for 循环 1->4, 拼接前缀 a
.forEach(System.out::println); // for 循环打印
// a1
// a2
// a3
下面是一个组合示例,我们将双精度流首先转换成 int 类型流,然后再将其装换成对象流:
Stream.of(1.0, 2.0, 3.0)
.mapToInt(Double::intValue) // double 类型转 int
.mapToObj(i -> "a" + i) // 对值拼接前缀 a
.forEach(System.out::println); // for 循环打印
// a1
// a2
// a3
Stream流获取的两种方式:
- 所有的Collection集合都可以通过Stream默认方法获取流
default Stream<E> stream()
- Stream接口的静态方法of可以获取数组对应的流
static <T> Stream<T> of(T...values)
参数是一个可变参数,那么我们就可以传递一个数组
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.stream.Stream;
public class Demo02GetStream {
public static void main(String[] args) {
// 把集合转换为Stream流
List<String> list = new ArrayList<>();
Stream<String> stream1 = list.stream();
Set<String> set = new HashSet<String>();
Stream<String> stream2 = set.stream();
Map<String, String> map = new HashMap<>();
// 获取键,存储到一个Set集合中
Set<String> keySet = map.keySet();
Stream<String> stream3 = keySet.stream();
// 获取值,存储到一个Collection集合中
Collection<String> values = map.values();
Stream<String> stream4 = values.stream();
// 获取键值对(键与值的映射关系 entrySet)
Set<Map.Entry<String, String>> entries = map.entrySet();
Stream<Map.Entry<String, String>> stream5 = entries.stream();
// 把数组转换为Stream流
Stream<Integer> stream6 = Stream.of(1, 2, 3, 4, 5);
// 可变参数可以传递数组
Integer[] arr = {1, 2, 3, 4, 5};
Stream<Integer> stream7 = Stream.of(arr);
String[] arr2 = {"a", "bb", "v"};
Stream<String> stream8 = Stream.of(arr2);
}
}
3.流处理顺序
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return true;
});
执行此代码段时,您可能会认为,将依次打印 "d2", "a2", "b1", "b3", "c" 元素。然而当你实际去执行的时候,它不会打印任何内容。
为什么呢?
原因是:当且仅当存在终端操作时,中间操作操作才会被执行。
是不是不信?接下来,对上面的代码添加 forEach终端操作:
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return true;
})
.forEach(s -> System.out.println("forEach: " + s));
再次执行,我们会看到输出如下:
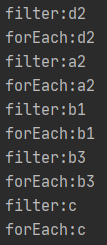
输出的顺序可能会让你很惊讶!你脑海里肯定会想,应该是先将所有 filter 前缀的字符串打印出来,接着才会打印 forEach 前缀的字符串。
事实上,输出的结果却是随着链条垂直移动的。比如说,当 Stream 开始处理 d2 元素时,它实际上会在执行完 filter 操作后,再执行 forEach 操作,接着才会处理第二个元素。
是不是很神奇?为什么要设计成这样呢?
原因是出于性能的考虑。这样设计可以减少对每个元素的实际操作数,看完下面代码你就明白了:
Stream.of("d2", "a2", "b1", "b3", "c")
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase(); // 转大写
})
.anyMatch(s -> {
System.out.println("anyMatch: " + s);
return s.startsWith("A"); // 过滤出以 A 为前缀的元素
});
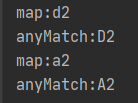
终端操作 anyMatch()表示任何一个元素以 A 为前缀,返回为 true,就停止循环。所以它会从 d2 开始匹配,接着循环到 a2 的时候,返回为 true ,于是停止循环。
由于数据流的链式调用是垂直执行的,map这里只需要执行两次。相对于水平执行来说,map会执行尽可能少的次数,而不是把所有元素都 map 转换一遍。
4.中间顺序操作这么重要?
Stream.of("d2", "a2", "b1", "b3", "c")
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase(); // 转大写
})
.filter(s -> {
System.out.println("filter: " + s);
return s.startsWith("A"); // 过滤出以 A 为前缀的元素
})
.forEach(s -> System.out.println("forEach: " + s)); // for 循环输出
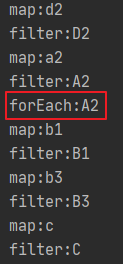
map和filter会对集合中的每个字符串调用五次,而forEach却只会调用一次,因为只有 "a2" 满足过滤条件。
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return s.startsWith("a"); // 过滤出以 a 为前缀的元素
})
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase(); // 转大写
})
.forEach(s -> System.out.println("forEach: " + s)); // for 循环输出
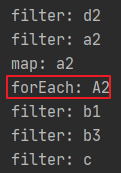
现在,map仅仅只需调用一次,性能得到了提升,这种小技巧对于流中存在大量元素来说,是非常很有用的。
5.高级操作
Streams 支持的操作很丰富,除了上面介绍的这些比较常用的中间操作,如filter或map外。还有一些更复杂的操作,如collect,flatMap以及reduce
5.1 Collect
collect 是一个非常有用的终端操作,它可以将流中的元素转变成另外一个不同的对象,例如一个List,Set或Map。collect 接受入参为Collector(收集器),它由四个不同的操作组成:供应器(supplier)、累加器(accumulator)、组合器(combiner)和终止器(finisher)。
这些都是个啥?别慌,看上去非常复杂的样子,但好在大多数情况下,您并不需要自己去实现收集器。因为 Java 8通过Collectors类内置了各种常用的收集器,你直接拿来用就行了。
下面这个例子介绍怎么从流中构造一个list
package com.company.service;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return name;
}
public static void main(String[] args) {
// 构建一个Person集合
List<Person> persons =
Arrays.asList(
new Person("Max", 18),
new Person("Peter", 23),
new Person("Pamela", 23),
new Person("Max", 12)
);
// 从流中构造一个List
List<Person> filtered =
persons.stream()
.filter(p -> p.name.startsWith("P"))
.collect(Collectors.toList());
System.out.println(filtered);
}
}

可以看到从流中构造一个 List 异常简单。如果说你需要构造一个 Set 集合,只需要使用Collectors.toSet()就可以了。
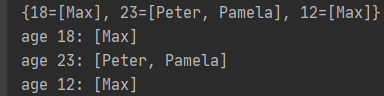
// 按年龄对所有人进行分组
Map<Integer, List<Person>> personByAge = persons.stream().collect(Collectors.groupingBy(p -> p.age));
System.out.println(personByAge);
// 遍历map
personByAge.forEach((age, p) -> System.out.format("age %s: %s
", age, p));
(2)flatMap
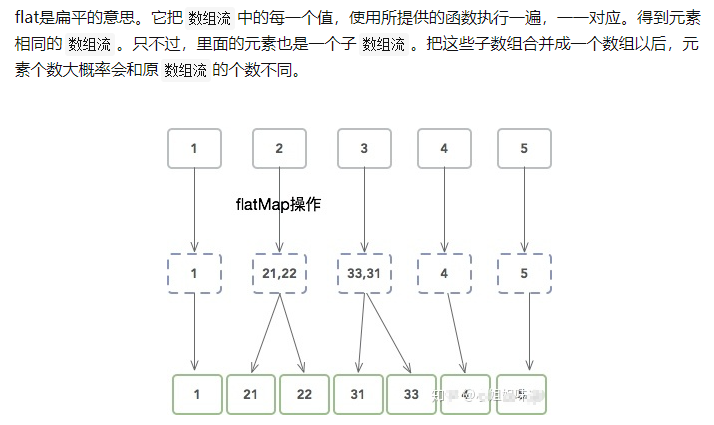
7.Stream流中常用方法

流模型的操作很丰富,可以分成两种:
- 延迟方法:返回值类型仍然是Stream接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方法均为延迟方法)
- 终结方法:返回值类型不再是Stream接口自身类型的方法,因此不再支持StringBuilder那样的链式调用。终结方法包括count 和 forEach方法
(1)逐一处理:forEach
void forEach(Consumer<? super T> action);
该方法接收一个Consumer接口函数,会将每一个流元素交给该函数进行处理
Consumer接口是一个消费型的函数式接口,可以传递lambda表达式,消费数据
简单记:
forEach方法,用来遍历流中的数据
是一个终结方法,遍历之后,就不能继续调用Stream流中的其他方法
import java.util.stream.Stream;
public class Demo02Stream_forEach {
public static void main(String[] args) {
// 获取一个Stream流
Stream<String> stream = Stream.of("张三", "李四", "王五", "赵六", "田七");
// 使用Stream流中的方法forEach对Stream流中的数据进行遍历
stream.forEach(name -> System.out.println(name));
}
}
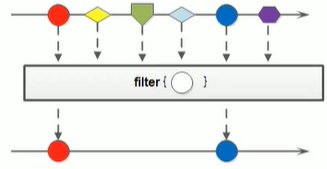
(2)过滤:filter
可以通过filter方法将一个流转换成另一个子集流,用于对Stream流中的数据进行过滤
Stream<T> filter(Predicate<? super T> predicate);
filter 方法的参数Predicate是一个函数式接口,所以可以传递lambda表达式,对数据进行过滤
Predicate中的抽象方法:
boolean test(T t);
import java.util.stream.Stream;
public class Demo03Stream_filter {
public static void main(String[] args) {
// 创建一个Stream流
Stream<String> stream = Stream.of("张三丰", "张翠山", "赵敏", "周芷若", "张无忌");
// 对Stream流中的元素进行过滤,只要姓张的
// Stream<String> stream1 = stream.filter(name -> name.startsWith("张"));
Stream<String> stream1 = stream.filter((name) -> {return name.startsWith("张");});
// 遍历Stream1流
stream1.forEach(name -> System.out.println(name));
}
}
(3)Stream流的特点
Stream流属于管道流,只能被消费(使用)一次,第一个Stream流调用完毕方法,数据就会流转到下一个Stream上,而这时第一个Stream流已经使用完毕,就会关闭了。所以第一个Stream流就不能再调用方法了。

(4)映射:map
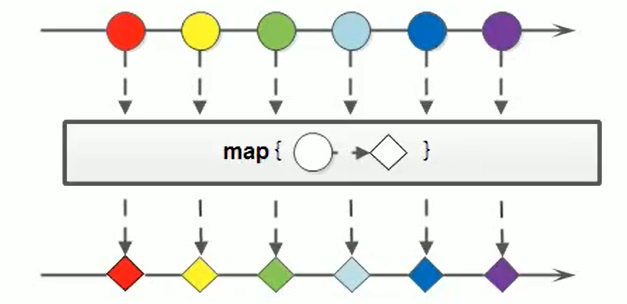
如果需要将流中的元素映射到另一个流中,可以使用map方法
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
该接口需要一个Function函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流
Function中的抽象方法:
R apply(T, t)
import java.util.stream.Stream;
public class Demo04Stream_map {
public static void main(String[] args) {
// 获取String类型的Stream流
Stream<String> stringStream = Stream.of("1", "2", "3", "4");
// 使用map方法把字符类型的整数,转换(映射)为Integer类型的整数
Stream<Integer> integerStream = stringStream.map((String s) -> {
return Integer.parseInt(s);
});
// 遍历
integerStream.forEach((Integer s) -> {
System.out.println(s);
});
}
}
(5)统计个数:count
用于统计Stream流中元素的个数
long count();
count方法是一个终结方法,返回值是一个long类型的整数
所以不能再继续调用Stream流中的其他方法了
import java.util.ArrayList;
import java.util.stream.Stream;
public class Demo05Stream_count {
public static void main(String[] args) {
// 获取一个Stream流
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
list.add(6);
Stream<Integer> stream = list.stream();
long count = stream.count();
System.out.println(count);
}
}
(6)取用前几个:limit
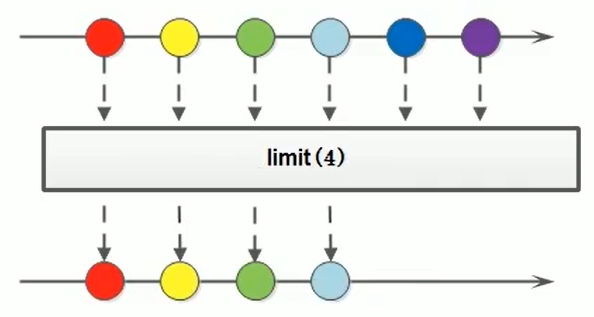
用于截取流中的元素
limit方法可以对流进行截取,只取用前n个。
方法签名:
Stream<T> limit(long maxsize);
参数是一个long型,如果集合当前长度大于参数则进行截取,否则不进行操作
limit方法是一个延迟方法,只是对流中的元素进行截取,返回的是一个新的流,所以可以继续调用Stream流中的其他方法
import java.util.stream.Stream;
public class Demo06Stream_limit {
public static void main(String[] args) {
// 获取一个Stream流
String[] arr = {"美羊羊", "喜羊羊", "懒羊羊", "灰太狼"};
Stream<String> stream = Stream.of(arr);
// 使用limit方法对Stream流中的元素进行截取,只要前3个元素
Stream<String> stream2 = stream.limit(3);
// 遍历
stream2.forEach(name -> {
System.out.println(name);
});
}
}
(7)跳过前几个:skip
skip:用于跳过元素
如果希望跳过前几个元素,可以使用skip方法获取一个截取之后的新流
Stream<T> skip(long n);
如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流
import java.util.stream.Stream;
public class Demo07Stream_skip {
public static void main(String[] args) {
// 获取一个Stream流
String[] arr = {"美羊羊", "喜羊羊", "懒羊羊", "灰太狼"};
Stream<String> stream1 = Stream.of(arr);
// 使用skip跳过前3个元素
Stream<String> stream2 = stream1.skip(3);
// 遍历
stream2.forEach(name -> {
System.out.println(name);
});
}
}
(8)组合:concat
concat用于把流组合到一起
如果有两个流,希望合并成为一个流,那么可以使用Stream接口的静态方法concat
static <T> Stream<T> concat(Stream<? extends T> a , Stream<? extends T> b)
import java.util.stream.Stream;
public class Demo08Stream_concat {
public static void main(String[] args) {
// 获取String类型的Stream流
Stream<String> stringStream = Stream.of("1", "2", "3", "4");
// 获取一个Stream流
String[] arr = {"美羊羊", "喜羊羊", "懒羊羊", "灰太狼"};
Stream<String> stream1 = Stream.of(arr);
// 把以上两个流合并为一个流
Stream<String> concat = Stream.concat(stringStream, stream1);
// 遍历
concat.forEach(name -> {
System.out.println(name);
});
}
}