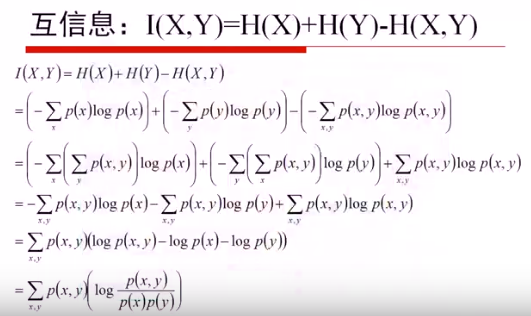1. 对数损失函数:
对数损失, 即对数似然损失(Log-likelihood Loss), 也称逻辑斯谛回归损失(Logistic Loss)或交叉熵损失(cross-entropy Loss), 是在概率估计上定义的.它常用于(multi-nominal, 多项)逻辑斯谛回归和神经网络,以及一些期望极大算法的变体. 可用于评估分类器的概率输出.
对数损失通过惩罚错误的分类,实现对分类器的准确度(Accuracy)的量化. 最小化对数损失基本等价于最大化分类器的准确度.为了计算对数损失, 分类器必须提供对输入的所属的每个类别的概率值, 不只是最可能的类别. 对数损失函数的计算公式如下:
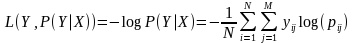
其中, Y 为输出变量, X为输入变量, L 为损失函数. N为输入样本量, M为可能的类别数, yij 是一个二值指标, 表示类别 j 是否是输入实例 xi 的真实类别. pij 为模型或分类器预测输入实例 xi 属于类别 j 的概率.
如果只有两类 {0, 1}, 则对数损失函数的公式简化为
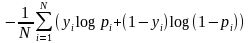
这时, yi 为输入实例 xi 的真实类别, pi 为预测输入实例 xi 属于类别 1 的概率. 对所有样本的对数损失表 示对每个样本的对数损失的平均值, 对于完美的分类器, 对数损失为 0 .
ref: https://www.cnblogs.com/klchang/p/9217551.html
2. 信息熵:
概率p越大,不确定越小,1/p越小,信息熵实质上是对log(1/p)取期望,因此有不确定性越小,信息熵越小。即信息熵越大,不确定越大。
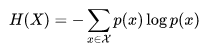
3. 感知机模型收敛性证明
4. KNN算法的缺陷
ref https://www.cnblogs.com/21207-iHome/p/6084670.html
观察下面的例子,我们看到对于样本X,通过KNN算法,我们显然可以得到X应属于红点,但对于样本Y,通过KNN算法我们似乎得到了Y应属于蓝点的结论,而这个结论直观来看并没有说服力。

由上面的例子可见:该算法在分类时有个重要的不足是,当样本不平衡时,即:一个类的样本容量很大,而其他类样本数量很小时,很有可能导致当输入一个未知样本时,该样本的K个邻居中大数量类的样本占多数。 但是这类样本并不接近目标样本,而数量小的这类样本很靠近目标样本。这个时候,我们有理由认为该位置样本属于数量小的样本所属的一类,但是,KNN却不关心这个问题,它只关心哪类样本的数量最多,而不去把距离远近考虑在内,因此,我们可以采用权值的方法来改进。和该样本距离小的邻居权值大,和该样本距离大的邻居权值则相对较小,由此,将距离远近的因素也考虑在内,避免因一个样本过大导致误判的情况。
从算法实现的过程可以发现,该算法存两个严重的问题,第一个是需要存储全部的训练样本,第二个是计算量较大,因为对每一个待分类的样本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。KNN算法的改进方法之一是分组快速搜索近邻法。其基本思想是:将样本集按近邻关系分解成组,给出每组质心的位置,以质心作为代表点,和未知样本计算距离,选出距离最近的一个或若干个组,再在组的范围内应用一般的KNN算法。由于并不是将未知样本与所有样本计算距离,故该改进算法可以减少计算量,但并不能减少存储量。
5. 似然与极大似然估计
http://fangs.in/post/thinkstats/likelihood/
似然与概率
在统计学中,似然函数(likelihood function,通常简写为likelihood,似然)是一个非常重要的内容,在非正式场合似然和概率(Probability)几乎是一对同义词,但是在统计学中似然和概率却是两个不同的概念。
概率是在特定环境下某件事情发生的可能性,也就是结果没有产生之前依据环境所对应的参数来预测某件事情发生的可能性,比如抛硬币,抛之前我们不知道最后是哪一面朝上,但是根据硬币的性质我们可以推测任何一面朝上的可能性均为50%,这个概率只有在抛硬币之前才是有意义的,抛完硬币后的结果便是确定的;
而似然刚好相反,是在确定的结果下去推测产生这个结果的可能环境(参数),还是抛硬币的例子,假设我们随机抛掷一枚硬币1,000次,结果500次人头朝上,500次数字朝上(实际情况一般不会这么理想,这里只是举个例子),我们很容易判断这是一枚标准的硬币,两面朝上的概率均为50%(由实际例子推断出来的),这个过程就是我们运用出现的结果来判断这个事情本身的性质(参数),也就是似然。
总结:概率是由性质去预测结果,似然是由结果去推测参数(性质)。

6. 条件熵

熵相关公式: