UDF:
一、编写udf类,在其中定义udf函数
package spark._sql.UDF
import org.apache.spark.sql.functions._
/**
* AUTHOR Guozy
* DATE 2019/7/18-9:41
**/
object udfs {
def len(str: String): Int = str.length
def ageThan(age: Int, small: Int): Boolean = age > small
val ageThaner = udf((age: Int, bigger: Int) => age < bigger)
}
二、在主方法中进行调用
package spark._sql
import org.apache.log4j.Logger
import org.apache.spark.sql
import spark._sql.UDF.udfs._
import org.apache.spark.sql.functions._
/**
* AUTHOR Guozy
* DATE 2019/7/18-9:42
**/
object UDFMain {
val log = Logger.getLogger("UDFMain")
def main(args: Array[String]): Unit = {
val ssc = new sql.SparkSession.Builder()
.master("local[2]")
.appName(this.getClass.getSimpleName)
.enableHiveSupport()
.getOrCreate()
ssc.sparkContext.setLogLevel("warn")
val df = ssc.createDataFrame(Seq((22, 1), (24, 1), (11, 2), (15, 2))).toDF("age", "class_id")
df.createOrReplaceTempView("table")
ssc.udf.register("len", len _)
ssc.sql("select age,len(age) as len from table").show(20, false)
println("=====================================")
ssc.udf.register("ageThan", ageThan _)
ssc.sql("select age from table where ageThan(age,15)").show()
println("=====================================")
import ssc.implicits._
val r = ssc.sql("select * from table")
r.filter(ageThaner($"age", lit(20))).show()
println("=====================================")
ssc.stop()
}
}
运行结果:
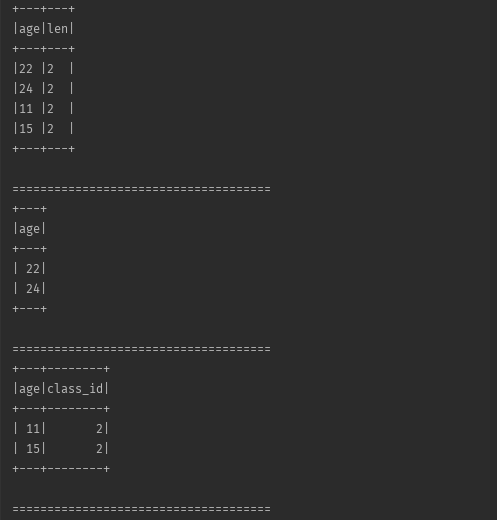
可以看到,以上代码中一共定义了三个不同的udf函数,分别对三个函数进行说明:
-
len(str: String):该函数使用用来获取传入字段的长度,str 即为所需要传入的字段
- 在使用的时候,需要现将其进行注册并赋予其函数名:ssc.udf.register("len", len _),调用的时候直接在sql语句中通过函数名来进行调用
-
ageThan(age: Int, small: Int):该函数式用来比较传入的age与已有的small大小,返回一个boolean值,该函数需要是用在where条件语句中用来进行过滤使用
- 在使用的时候,需要现将其进行注册并赋予其函数名:ssc.udf.register("ageThan", ageThan _),调用的时候直接在sql语句中通过函数名来进行调用
-
ageThaner:该函数跟上面两个不同,所谓的不同指的是:
- 定义方式不同:通过使用org.apache.spark.sql.functions._ 中的udf函数在定义的时候就将其注册好
- 使用场景不同:使用在dataframe中,用来进行select,filter操作中
- 对于该函数的第二列来说,如果是常量的话,需要使用org.apache.spark.sql.function._ 中的lit进行包装,不能将常量直接传入,否则,程序不认识该常量会报错,如果是列名的话,则没问题,使用($"colName")方式即可。
UDAF(弱类型):
UDAF相对于udf来说稍微麻烦一下,且需要完全理解当中每个函数的含义才可以轻而易举的写出符合自己预期的UDAF函数,
UDAF需要继承 UserDefinedAggregateFunction ,并且复写当中的方法
方法含义说明:
def inputSchema: StructType =
StructType(Array(StructField("value", IntegerType)))
inputSchema用来定义,输入的字段的类型,字段名可以随便定义,这里定义为value,也可以是其他的,不重要,关键是字段类型一定要与所要传入计算的字段进行对应,且必须使用org.apche.spark.sql.type. _ 中的类型
def bufferSchema: StructType = StructType(Array(
StructField("count", IntegerType), StructField("ages", DoubleType)))
bufferSchema用来定义生成中间数据的结果类型,例如在求和的时候,要求a+b+c,相加顺序为a+b=ab,ab+c=abc ,ab即为中间结果。
def dataType: DataType = DoubleType
dataType为函数返回值的类型,例子中,该UDAF最终返回的结果为double类型,这里的类型不能写成double,要写成org.apache.spark.sql.type._支持的类型DoubleType.
def deterministic: Boolean = true
daterministic 为代表结果是否为确定性的,也就是说,相同的输入是否有相同的输出。
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0
buffer(1) = 0.0
}
initalize 初始化中间结果,即count和ages的初始值。
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getInt(0) + 1 //更新计数器
buffer(1) = buffer.getDouble(1) + input.getInt(0) //更新值
}
update用来更新中间结果,input为dataframe中的一行,将要合并到buffer中的数据,buffer则为已经进行合并后的中间结果。
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getInt(0) + buffer2.getInt(0)
buffer1(1) = buffer1.getDouble(1) + buffer2.getDouble(1)
}
merge 合并所有分片的结果,buffer2是一个分片的中间结果,buffer1是整个合并过程中的结果。
def evaluate(buffer: Row): Any = {
buffer.getDouble(1) / buffer.getInt(0)
}
evaluate 函数式真正进行计算的函数,计算返回函数的结果,buffer是merge合并后的结果
案例需求:求分组中age的平均数
先上代码:
一、定义UDAF函数
package spark._sql.UDAF
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
/**
* AUTHOR Guozy
* DATE 2019/7/18-14:47
**/
class udafs() extends UserDefinedAggregateFunction {
def inputSchema: StructType =
StructType(Array(StructField("value", IntegerType)))
def bufferSchema: StructType = StructType(Array(
StructField("count", IntegerType), StructField("ages", DoubleType)))
def dataType: DataType = DoubleType
def deterministic: Boolean = true
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0
buffer(1) = 0.0
}
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getInt(0) + 1 //更新计数器
buffer(1) = buffer.getDouble(1) + input.getInt(0) //更新值
}
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getInt(0) + buffer2.getInt(0)
buffer1(1) = buffer1.getDouble(1) + buffer2.getDouble(1)
}
def evaluate(buffer: Row): Any = {
buffer.getDouble(1) / buffer.getInt(0)
}
}
二、主函数引用:
package spark._sql.UDF
import org.apache.spark.sql
import org.apache.spark.sql.functions._
import spark._sql.UDAF.udafs
/**
* AUTHOR Guozy
* DATE 2019/7/19-16:04
**/
object UDAFMain {
def main(args: Array[String]): Unit = {
val ssc = new sql.SparkSession.Builder()
.master("local[2]")
.appName(this.getClass.getSimpleName)
.enableHiveSupport()
.getOrCreate()
ssc.sparkContext.setLogLevel("warn")
val ageDF = ssc.createDataFrame(Seq((22, 1), (24, 1), (11, 2), (15, 2))).toDF("age", "class_id")
ssc.udf.register("avgage", new udafs)
ageDF.createOrReplaceTempView("table")
ssc.sql("select avgage(age) from table group by class_id").show()
ssc.stop()
}
}
运行结果:

UDAF(强类型)
关于UDAF函数,一种是关于上面所描述的弱类型聚合函数,弱类型聚合函数只能是在sql数据中进行使用,在使用的过程中,对于传入的值的类型,如果有问题,只有在程序运行的时候才能进行发现。这样的话,灵活性不是很高。如果能够在编译的时候就对传入的类型进行限定,并且输入类型以及输出类型都是可以有我们自己定义,这样的相对来说就灵活许多了,而且在生产中使用的也是比较多的。这就是接下来要说的强类型的UDAF,但是有一点需要注意的是,强类型的UDAF不能在sql语句中使用,只能在DLS语句中使用
自定义强类型的UDFA需要继承 Aggregator 这个类,与弱类型聚合函数有点区别
接下来看一下该类中有哪些方法:
abstract class Aggregator[-IN, BUF, OUT] extends Serializable {
/**
* A zero value for this aggregation. Should satisfy the property that any b + zero = b.
* @since 1.6.0
* 初始化缓冲区中的对象
*/
def zero: BUF
/**
* Combine two values to produce a new value. For performance, the function may modify `b` and
* return it instead of constructing new object for b.
* 更新缓冲区中的数据
* @since 1.6.0
*/
def reduce(b: BUF, a: IN): BUF
/**
* Merge two intermediate values.
* 合并缓冲区
* @since 1.6.0
*/
def merge(b1: BUF, b2: BUF): BUF
/**
* Transform the output of the reduction.
* 实现真正的计算
* @since 1.6.0
*/
def finish(reduction: BUF): OUT
/**
* Specifies the `Encoder` for the intermediate value type.
* 缓冲区编码方式,如果是自定义类型,就是用 Encoders.product
* @since 2.0.0
*/
def bufferEncoder: Encoder[BUF]
/**
* Specifies the `Encoder` for the final output value type.
* 最终结果的编码方式,如果是原生的类型,就用原生的类型,比如Encoders.scalaDouble,等等
* @since 2.0.0
*/
def outputEncoder: Encoder[OUT]
/**
* Returns this `Aggregator` as a `TypedColumn` that can be used in `Dataset`.
* operations.
* @since 1.6.0
*/
def toColumn: TypedColumn[IN, OUT] = {
implicit val bEncoder = bufferEncoder
implicit val cEncoder = outputEncoder
val expr =
AggregateExpression(
TypedAggregateExpression(this),
Complete,
isDistinct = false)
new TypedColumn[IN, OUT](expr, encoderFor[OUT])
}
}
编码实现:
需求:实现求平均年龄,并返回一个自定义的类型
步骤:
一、自定义UDAF类
import org.apache.spark.sql.expressions.Aggregator
case class user(name: String, age: Int)
case class avgAggBuffer(var sum: Long, var count: Int)
// 自定义聚合函数,强类型,这里的返回值,我们可以自定义,不一定非要是Double,也可以是自定义封装类型
class aggerageUDAF extends Aggregator[user, avgAggBuffer, Double] {
import org.apache.spark.sql.{Encoder, Encoders}
// 初始化缓冲区的对象
override def zero: avgAggBuffer = {
avgAggBuffer(0, 0)
}
// 更新缓冲区的数据
override def reduce(b: avgAggBuffer, a: user): avgAggBuffer = {
b.sum = b.sum + a.age
b.count = b.count + 1
b
}
// 合并不同的缓冲区
override def merge(b1: avgAggBuffer, b2: avgAggBuffer): avgAggBuffer = {
b1.sum = b1.sum + b2.sum
b1.count = b1.count + b2.count
b1
}
// 完成计算
override def finish(reduction: avgAggBuffer): Double = {
reduction.sum.toDouble / reduction.count
}
// 如果是自定义的类型则用该方式进行转码,基本固定
override def bufferEncoder: Encoder[avgAggBuffer] = Encoders.product
// 转码,如果是原生类型,则直接进行转码
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
二、主类调用
object customeUDAF {
def main(args: Array[String]): Unit = {
val ssc = SparkSession
.builder()
.master("local[2]")
.appName(this.getClass.getSimpleName)
.enableHiveSupport()
.getOrCreate()
val sc = ssc.sparkContext
sc.setLogLevel("error")
import org.apache.spark.sql.{Dataset, TypedColumn}
import ssc.implicits._
val rdd1 = sc.parallelize(List(("xl",20),("xh",30),("xw",40))).toDF("name","age")
val dataset: Dataset[user] = rdd1.as[user]
// 注册聚合函数
val aggUDF = new aggerageUDAF
// 将聚合函数转换为查询列
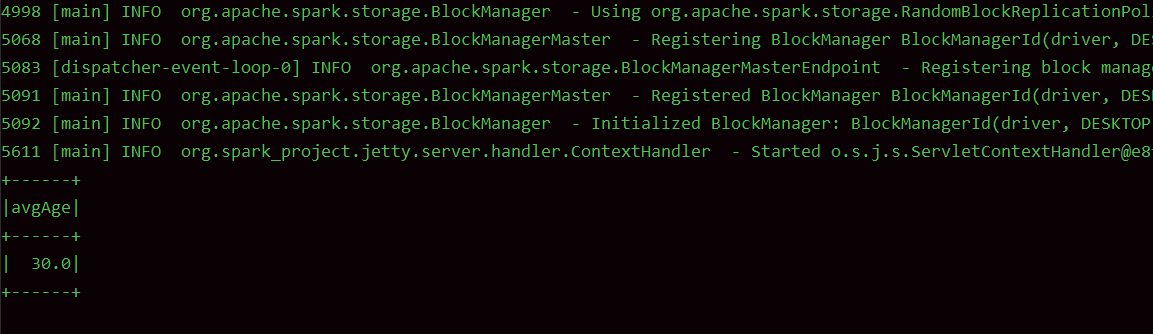
val cols: TypedColumn[user, Double] = aggUDF.toColumn.name("avgAge")
// 只能通过DSL语句进行使用
dataset.select(cols).show()
ssc.stop()
}
}
运行结果