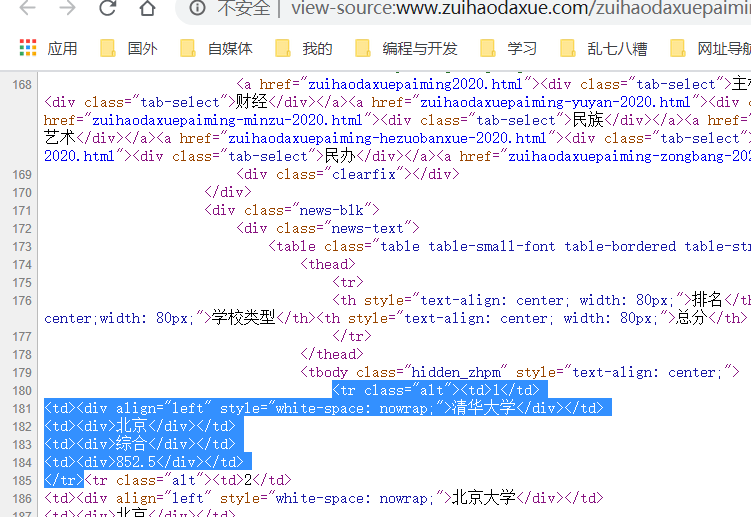
http://www.zuihaodaxue.com/zuihaodaxuepaiming-zongbang-2020.html






代码:
import requests from bs4 import BeautifulSoup import bs4 def getHTMLtext(url):#获取URL信息 try: r=requests.get(url,timeout=30) r.raise_for_status()#异常判断 r.encoding=r.apparent_encoding#转换编码 return r.text except: return"" def fillUnivList(ulist,html):#将HTML信息放在列表中 soup=BeautifulSoup(html,"html.parser") for tr in soup.find('tbody').children: if isinstance(tr,bs4.element.Tag):#判断类型 tds=tr('td') ulist.append([tds[0].string,tds[1].string,tds[2].string,tds[3].string,tds[4].string])#大学排名、大学名称、大学。。 def printUnivList(ulist,num):#打印出来 print("{:^10} {:^6} {:^10} {:^6} {:^10}".format("排名","学校名称","省市","学校类型","总分")) for i in range(num): u=ulist[i] print("{:^10} {:^6} {:^10} {:^6} {:^10}".format(u[0],u[1],u[2],u[3],u[4])) def main(): uinfo=[] url="http://www.zuihaodaxue.com/zuihaodaxuepaiming-zongbang-2020.html" html=getHTMLtext(url) fillUnivList(uinfo,html) printUnivList(uinfo,20)#列举20所学校 main()
效果

我们发现会有对不齐的现象
优化


代码:
import requests from bs4 import BeautifulSoup import bs4 def getHTMLtext(url):#获取URL信息 try: r=requests.get(url,timeout=30) r.raise_for_status()#异常判断 r.encoding=r.apparent_encoding#转换编码 return r.text except: return"" def fillUnivList(ulist,html):#将HTML信息放在列表中 soup=BeautifulSoup(html,"html.parser") for tr in soup.find('tbody').children: if isinstance(tr,bs4.element.Tag):#判断类型 tds=tr('td') ulist.append([tds[0].string,tds[1].string,tds[2].string,tds[3].string,tds[4].string])#大学排名、大学名称、大学。。 def printUnivList(ulist,num):#打印出来 tplt="{0:^10} {1:{5}^10} {2:^6} {3:^6} {4:^6}" print(tplt.format("排名","学校名称","省市","学校类型","总分",chr(12288))) for i in range(num): u=ulist[i] print(tplt.format(u[0],u[1],u[2],u[3],u[4],chr(12288))) def main(): uinfo=[] url="http://www.zuihaodaxue.com/zuihaodaxuepaiming-zongbang-2020.html" html=getHTMLtext(url) fillUnivList(uinfo,html) printUnivList(uinfo,20)#列举20所学校 main()
效果

是不是美观了不少?