前期准备工作:
此配置参照大牛给力星进行配置,并做修改!!!
注意:如下命令如果权限不够,请在命令前面加sudo;以下配置所有的cqb-Lenovo-B40请换成自己的主机名或localhost!!!
打开终端:
Ctrl+Alt+T
安装vim:
sudo apt-get install vim
安装SSH、配置SSH无密码登陆:
sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码,这样就登陆到本机了.
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
退出刚才的ssh localhost:
exit
若没有该目录,请先执行一次ssh localhost:
cd ~/.ssh/
会有提示,都按回车就可以:
ssh-keygen -t rsa
加入授权:
cat ./id_rsa.pub >> ./authorized_keys
此时再用ssh locahost命令,无需输入密码就可以直接登录了。
安装java环境:
安装Hadoop:
打开终端:
Ctrl+Alt+T
下载Hadoop:
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.1/hadoop-2.8.1.tar.gz
创建Hadoop的安装目录:
mkdir -p /data/service/
解压到/data/service/目录中:
tar -zxvf hadoop-2.8.1.tar.gz -C /data/service/
进入/data/service/目录中:
cd /data/service/
将文件名该为hadoop:
mv hadoop-2.8.1.tar.gz/ hadoop
给hadoop修改文件权限:
chown -R 用户名 hadoop/
进入hadoop目录:
cd /data/service/hadoop/
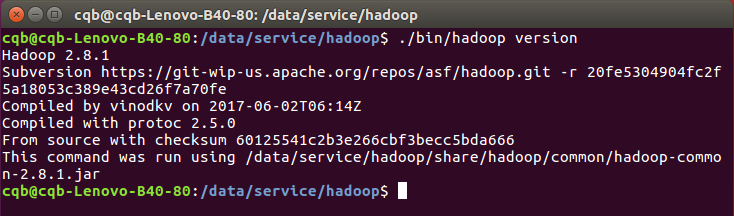
检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
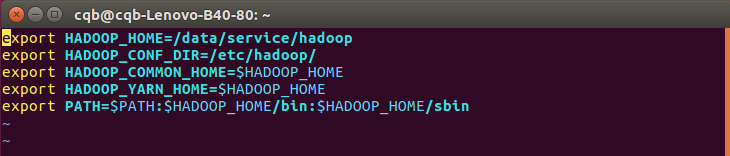
配置hadoop环境:
vim /etc/profile.d/hdfs-env.sh
执行hadoop环境,让其生效:
source /etc/profile.d/hdfs-env.sh
Hadoop伪分布式配置:
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的 文件。
Hadoop 的配置文件位于 /data/lservice/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每 个配置以声明 property 的 name 和 value 的方式来实现。
因为如果在/data/lservice/hadoop/etc/hadoop/里面的配置文件进行配置,如果下次我们下载了Hadoop更新的版本又要重新配置,为了只需配置一次,我们把
/data/lservice/hadoop/etc/下的hadoop目录复制到/etc/下面:
cp -a /data/service/hadoop/etc/hadoop/ /etc/
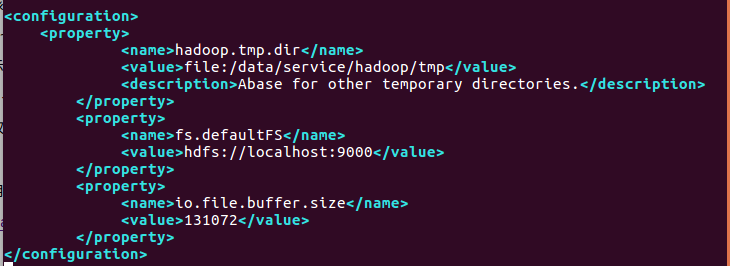
修改配置文件 core-site.xml (vim /etc/hadoop/core-site.xml),将当中的

修改为下面配置:
修改配置文件hdfs-site.xml之前创建好name目录和data目录:
mkdir -p /data/service/hadoop/dfs/name/
mkdir -p /data/service/hadoop/dfs/data/
修改配置文件 hdfs-site.xml( vim /etc/hadoop/hdfs-site.xml),将当中的
修改为下面配置:
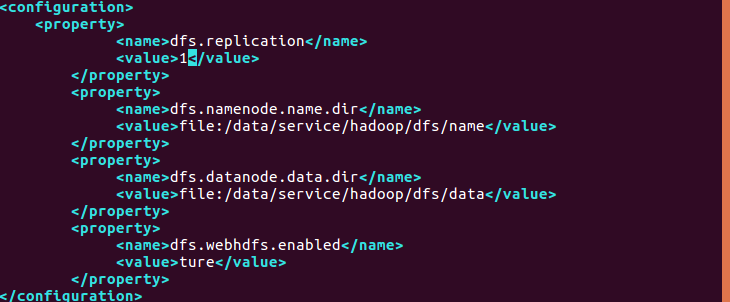
配置完成后,执行NameNode的格式化:
./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
如果在这一步时提示 Error: JAVA_HOME is not set and could not be found. 的错误,则说明之前设置 JAVA_HOME 环境变量那边就没设置好,请按教 程先设置好 JAVA_HOME 变量,否则后面的过程都是进行不下去的。
开启 NameNode 和 DataNode 守护进程:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
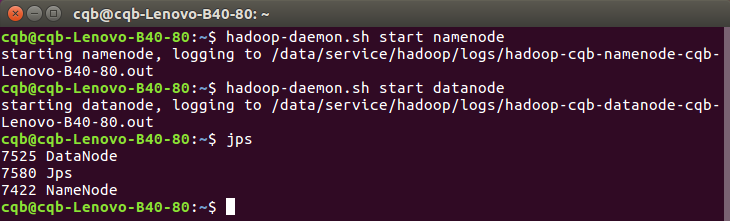
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 。如果没有 NameNode 或 DataNode ,那 就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
如通过jps没有NameNoda,可通过查看启动日志查看异常:

按Ctrl+c可退出异常命令。
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件:

关闭NameNode和DataNode守护进程:
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop datanode

关闭成功后就没有NameNode进程和DataNode进程了。
启动YARN:
上述启动 Hadoop,仅仅是启动了 MapReduce 环境,我们可以启动 YARN ,让 YARN 来负责资源管理与任务调度。
首先修改配置文件 mapred-site.xml,因为/etc/hadoop/下没有mapred-site.xml配置文件,所以需要先进行复制mapred-site.xml.template进行重命名:
mv /etc/hadoop/mapred-site.xml.template /etc/hadoop/mapred-site.xml
然后再进行编辑( vim /etc/hadoop/mapred-site.xml),将当中的
修改为下面配置:

接着修改配置文件 yarn-site.xml(vim /etc/hadoop/yarn-site.xml),将当中的
修改为下面配置:

配置完成后就可以启动 YARN 了:
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager;

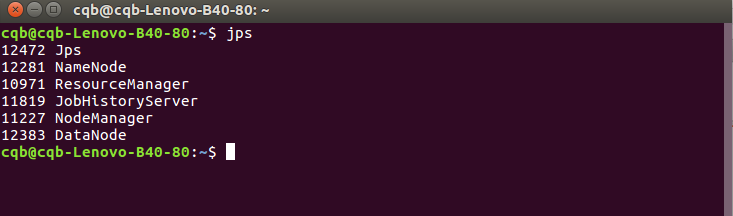
启动成功就会出现ResoureManager和NodeManager进程了。
我们还要开启历史服务器,才能在Web中查看任务运行情况:
mr-jobhistory-daemon.sh start historyserver;
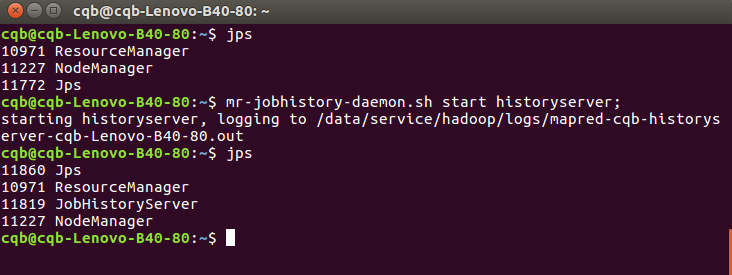
启动成功就会出现JobHistoryServer进程了。
启动 YARN 之后,运行实例的方法还是一样的,仅仅是资源管理方式、任务调度不同。观察日志信息可以发现,不启用 YARN 时,是 “mapred.LocalJobRunner” 在 跑任务,启用 YARN 之后,是 “mapred.YARNRunner” 在跑任务。启动 YARN 有个好处是可以通过 Web 界面查看任务的运行情况:
http://localhost:8088/cluster,如下图所 示。
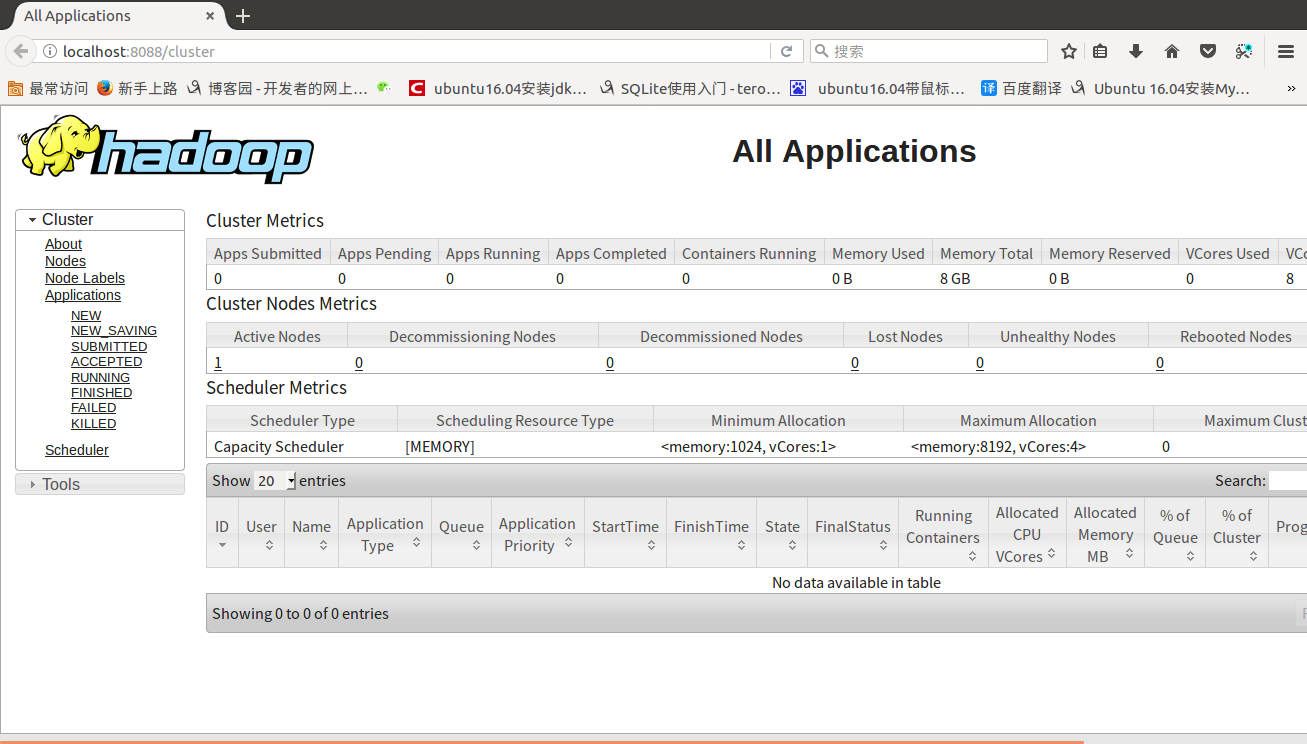
同样的,关闭 YARN 的进程如下:
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop nodemanager
mr-jobhistory-daemon.sh stop historyserver
自此,你已经掌握 Hadoop 的配置和基本使用了。