面向对象的特点 和 自己的感悟
1._init_是构造函数,给实例变量(静态变量赋值,属性)赋值
2.self 代表是把实例传进去,谁调用就把谁传进去
3.构造函数 中的实例变量,存在实例的内存空间里
4.类中的方法,类的变量。存在类的内存空间里
5.类的变量,对所有实例(对象)都是有用的,但同名的时候首先以实例变量为准,在内存中只创建一次,节省开销
6.实例变量可以 添加(对象.添加的属性=值),修改(对象.属性名=值),删除 (del 对象.属性)
7.在对象里修改 类变量,只会对当前的对象有效果。其他对象中的类变量不变。原因是 类变量是属于类的,属于所有对象的。在当前对象之所以改变,相当于给 实例 新增了一个 和类变量同名的属性。所以虽然同名,但读取的却不是 类变量了。
8.如果 类变量是列表 或者是 元组 字典 集合 等数据结构,在不同的对象里增加元素 或者其他操作,都会使 列表改变。因为他 既不存在类里,也不存在实例里。其他函数,对这种数据结构效果也是一样的。
9.析构函数 用于收尾的 操作 会在内存被回收时调用,默认也就是程序结束时。也可以主动删除这个 del对象,那么他将会在,这个对象所有的操作完成之后执行。
def __del__( self ):
pass
私有属性。方法。在前面加上两个_。只能在类内部进行访问,外部不可直接读取。这样就避免了,有人直接通过类,或者对象。获得或修改数据。数据变得更加安全。
私有属性无法访问的根本原因 在于它的名称发生了变化
变成了_类名__变量名

继承
重构父类方法
子类新添加一个属性

另一种方式调用父类 super

关于实例变量的两种查找策略
例子:A分别被 B C继承,D继承 B C
A
B(A) C(A)
D(B,C)
广度优先 顺序 D>B>C>A
深度优先 顺序 D>B>A>C


例子
#父类1
class people(object):
def __init__(self,name,age):
self.name=name
self.age=age
def eta(self):
print("%s在吃苦瓜"%self.name)
#父类2
class Work(object):
def papa(self):
print("%s在敲代码"%self.name)
#继承两个父类
class houzi(people,Work):
#添加一个新属性city
def __init__(self,name,age,city):
people.__init__(self,name,age)
self.city=city
def chengshi(self):
print("%s在%s生活"%(self.name,self.city))
def eta(self):
'''重构父类方法'''
print("%s该拔智齿了"%self.name)
people.eta(self)
#创建一个实例
h1=houzi("大锤","23","北京")
h1.eta()
h1.papa()
h1.chengshi()
输出
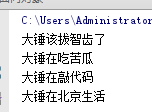
多态
同一接口,多种实现