为想学Python或正在进阶的小伙伴提供一种轻松的入门方式,小编会由浅入深的详解爬虫技术。
介绍
什么是爬虫?
先看看百度百科的定义:





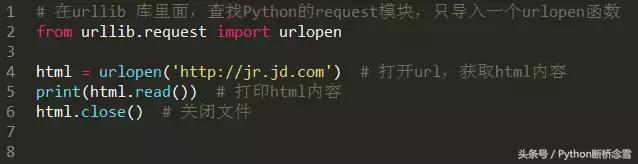
把这段代码保存为get_html.py,然后运行,看看输出了什么:



定位到的html代码:

有了这些信息,就可以用BeautifulSoup提取数据了。升级一下代码:
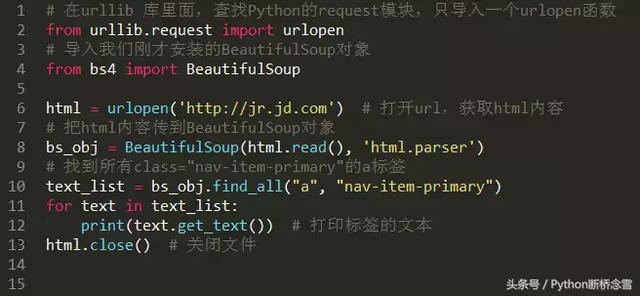
把这段代码保存为get_data.py,然后运行,看看输出了什么:

没错,得到了我们想要的数据!
BeautifulSoup提供一些简单的、Python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。怎么样,是不是觉得只要复制粘贴就可以写爬虫了?简单的爬虫确实是可以的!
一个迷你爬虫
我们先定一个小目标:爬取网易云音乐播放数大于500万的歌单。
打开歌单的url: http://music.163.com/#/discover/playlist,然后用BeautifulSoup提取播放数<span class=”nb”>3715</span>。结果表明,我们什么也没提取到。难道我们打开了一个假的网页?


Selenium:是一个强大的网络数据采集工具,其最初是为网站自动化测试而开发的。近几年,它还被广泛用于获取精确的网站快照,因为它们可以直接运行在浏览器上。Selenium 库是一个在WebDriver 上调用的API。WebDriver 有点儿像可以加载网站的浏览器,但是它也可以像BeautifulSoup对象一样用来查找页面元素,与页面上的元素进行交互(发送文本、点击等),以及执行其他动作来运行网络爬虫。安装方式与其他Python第三方库一样。
$pip install Selenium
验证一下:
Selenium 自己不带浏览器,它需要与第三方浏览器结合在一起使用。例如,如果你在Firefox 上运行Selenium,可以直接看到一个Firefox 窗口被打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但不适用于我们的爬虫程序,爬一页就打开一页效率太低,所以我们用一个叫PhantomJS的工具代替真实的浏览器。
PhantomJS:是一个“无头”(headless)浏览器。它会把网站加载到内存并执行页面上的JavaScript,但是它不会向用户展示网页的图形界面。把Selenium和PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,可以处理cookie、JavaScript、header,以及任何你需要做的事情。
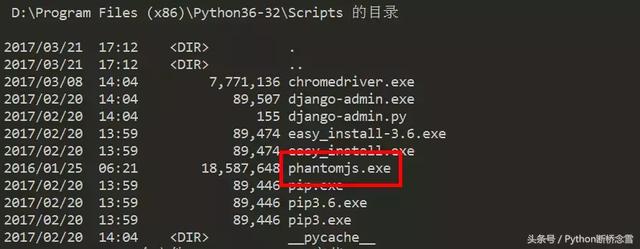
PhantomJS并不是Python的第三方库,不能用pip安装。它是一个完善的浏览器,所以你需要去它的官方网站下载,然后把可执行文件拷贝到Python安装目录的Scripts文件夹,像这样:
开始干活!
打开歌单的第一页:
http://music.163.com/#/discover/playlist/?order=hot&cat=%E5%85%A8%E9%83%A8&limit=35&offset=0
用Chrome的“开发者工具”F12先分析一下,很容易就看穿了一切。
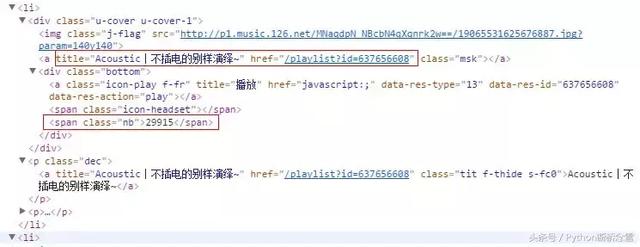
播放数nb (number broadcast):29915
封面 msk (mask):有标题和url
同理,可以找到“下一页”的url,最后一页的url是“javascript:void(0)”。
最后,用18行代码即可完成我们的工作。
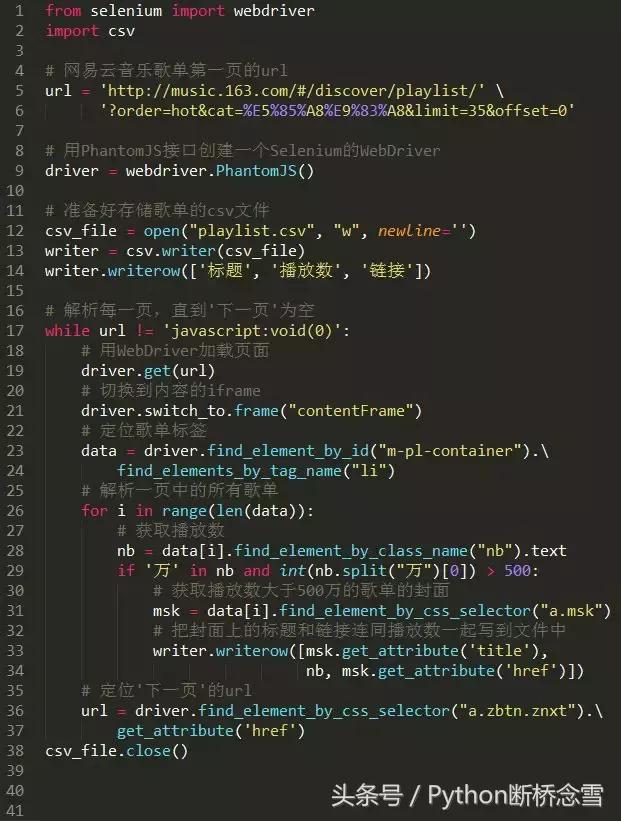
把这段代码保存为get_data.py,然后运行。运行结束后,在程序的目录里生成了一个playlist.csv文件。
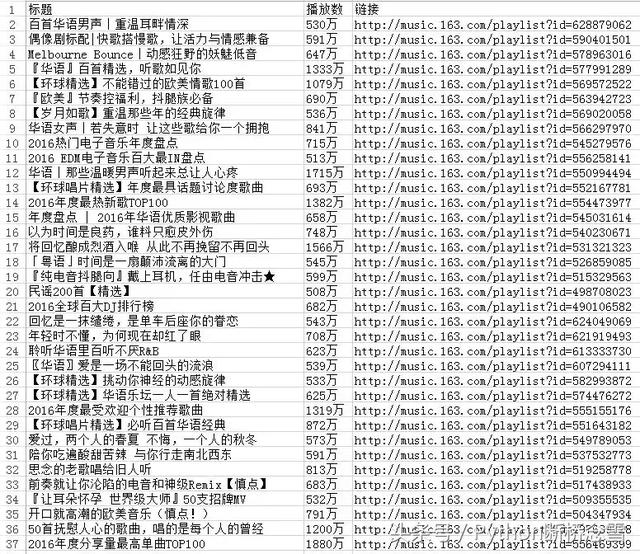
看到成果后是不是很有成就感?如果你感兴趣,那就按照这个思路,找找评论数最多的单曲,再也不用担心没歌听了!