zoukankan
html css js c++ java
http://www.bugku.com:Bugku——jsfuckWEB5(http://120.24.86.145:8002/web5/index.php)
今天又做了bugku上面的一道题。使用到了jsfuck,它是什么捏?
它是Javascript原子化的一种简易表达方式,用[]()!+就可以表示所有的Javascript字符,不依赖于浏览器。
https://github.com/aemkei/jsfuck/blob/master/jsfuck.js
上述是所有它对字符的指代情况。
祭题。
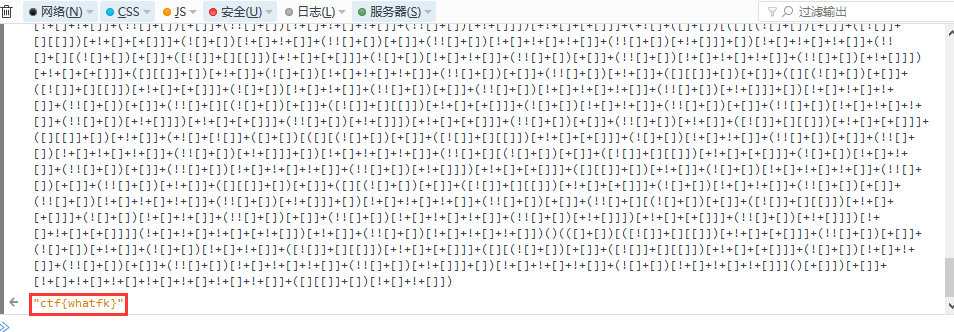
看见没,一大堆,嗯嗯,它就是jsfuck。它可以在控制台中被识别执行哦。
复制过来执行,出来结果。如下图所示
愉快地结束-。-
查看全文
相关阅读:
今天一个人跑了趟香山
周六钻胡同
(转)C#中protected用法详解
C# base和this
error BK1506 : cannot open file '.\Debug\ex73View.sbr': No such file or directory
error PRJ0003 : Error spawning 'cmd.exe'
VS2008卸载时遇到“加载安装组件时遇到问题,取消安装” 在卸载或者升级VS2008的时候,遇到“加载安装组件时遇到问题,取消安装”的情况
我们在建立Win32工程的时候,要选择是Win32控制台应用程序还是Win32项目,那么两者到底有什么区别呢?
开发板重新烧写时出现ERROR: Checksum failure (expected=0x3D67E6F computed=0x3E0E0CA)
把PC上的代码移植到WINCE上
原文地址:https://www.cnblogs.com/HYWZ36/p/10295912.html
最新文章
遍历系统目录下的所有文件
SQL求差:在table1但不在table2中
2010,我从零开始
HDOJ_ACM_Sudoku Killer
BFS
Estimating Ngram Probabilities
HDOJ_ACM_Prime Ring Problem
HDOJ_ACM_非常可乐
HDOJ_ACM_N皇后问题
HDOJ_ACM_Escape
热门文章
HDOJ_ACM_Tempter of the Bone
Ngrams
回北京
Yahoo!的Crack Day
阴冷的白杨沟,正宗的阳坊涮肉
第二次上东方红
幻影7周年
xkungfoo
女排黄金一代告别
为firefox实现innerText属性
Copyright © 2011-2022 走看看