> 目 录 <
- Dynamic programming
- Policy Evaluation (Prediction)
- Policy Improvement
- Policy Iteration
- Value Iteration
- Asynchronous Dynamic Programming
- Generalized Policy Iteration
> 笔 记 <
定义:a collection of algorithms that can be used to compute optimal policies given a perfect model of the environment as a Markov decision process (MDP).
经典的DP算法处理RL problem的能力有限的原因:(1) 假设a perfect model with complete knowledge;(2) 巨大的计算开销
Policy Evaluation (Prediction)
policy evaluation: the iterative computation of the state-value function $v_{pi}$ for a given policy $pi$.

用迭代=的方法实现评估: 旧的value = expected immediate rewards + 从后继states获得的values
这种更新操作叫做expected update,因为它基于所有可能的后继states的期望,而非单个next state sample。
存储方式:有two-array version(同时存储old和new value) 和 in-place algorithm(只存储new value)两种,通常采用后者,收敛的更快。

我们计算policy的价值函数的目的是希望能够帮助我们找到更好的policy。
Policy improvement theorem:
两个确定的策略$pi$和$pi'$,如果满足:
那么策略$pi'$一定比$pi$好or跟它一样好。因此,策略$pi'$可以在所有state上得到更多or相等的expected return:
证明如下:
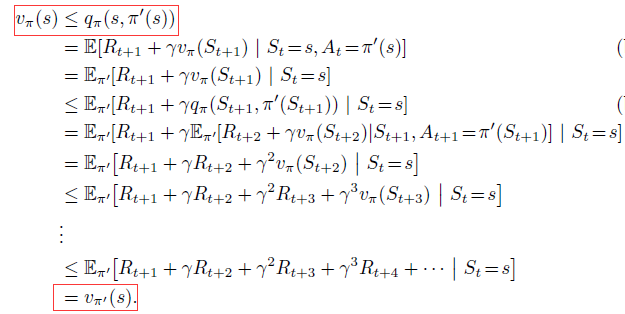
Policy improvement:
定义: Policy improvement refers to the computation of an improved policy given the value function for that policy.
相比原始策略$pi$,如果我们在所有states上采用贪心算法来选择action,那么得到的新策略如下:
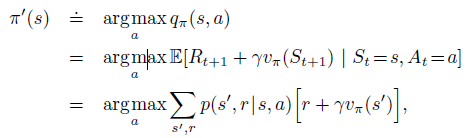
因为其满足policy improvement theorem的条件,所以新的greedy policy $pi'$要比old policy更好。我们可以根据这一性质,不断地对policy进行改进,直到new policy和old policy一样好,即$v_{pi}=v_{pi'}$,此时对所有的states满足:
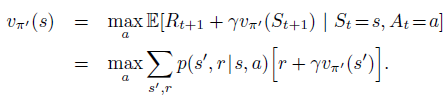
该式子正是Bellman optimality equation,因此$v_{pi'}$一定是$v_{*}$, 策略$pi$和$pi‘’$一定是最优策略。
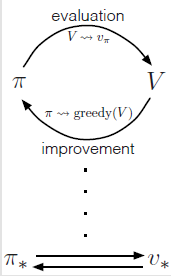
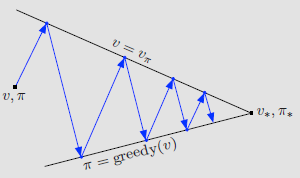
定义: 一种把policy evaluation和policy improvement结合在一起的常见的DP方法。
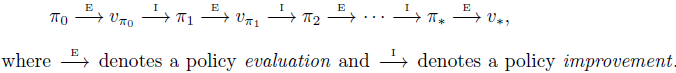
因为finite MDP只有有限数量的策略,因此最终总会在有限步数内收敛到一个optimal policy和optimal value function。

policy iteration的缺点:每一轮迭代都需要执行policy evaluation,而policy evaluation需要对state set扫描多次并且$v_{pi}$最终很久才能收敛。
改进方法:可否让policy evaluation早一些停止?value iteration不再等policy evaluation收敛,而是只对所有state扫描一次就停止。将policy evaluation和policy improvement的步骤同时进行:

Asynchronous Dynamic Programming
之前讨论的DP方法的缺点在于:需要对MDP中所有states进行扫描、操作,导致效率低下。
Asynchronous DP algorithms: 是in-place iterative DP algorithms,这类算法可以按照任意顺序更新state的value,并且不管其他states当前的value是何时更新的。
需要注意的是,avoiding state sweeps并不意味着我们可以减少计算量,其好处是(1) 可以让我们尽快利用更新后的value来提升policy,并且减少更新那些无用的states。(2)可以实时计算,所以可以实现iterative DP algorithm at the same time that agent is actually experiencing the MDP。agent经历可以用于决定更新那些states。
generalized policy iteration (GPI):policy-evaluation and policy-improvement processes interaction