本案例适用于爬取彼岸图网4k壁纸10页(如下图
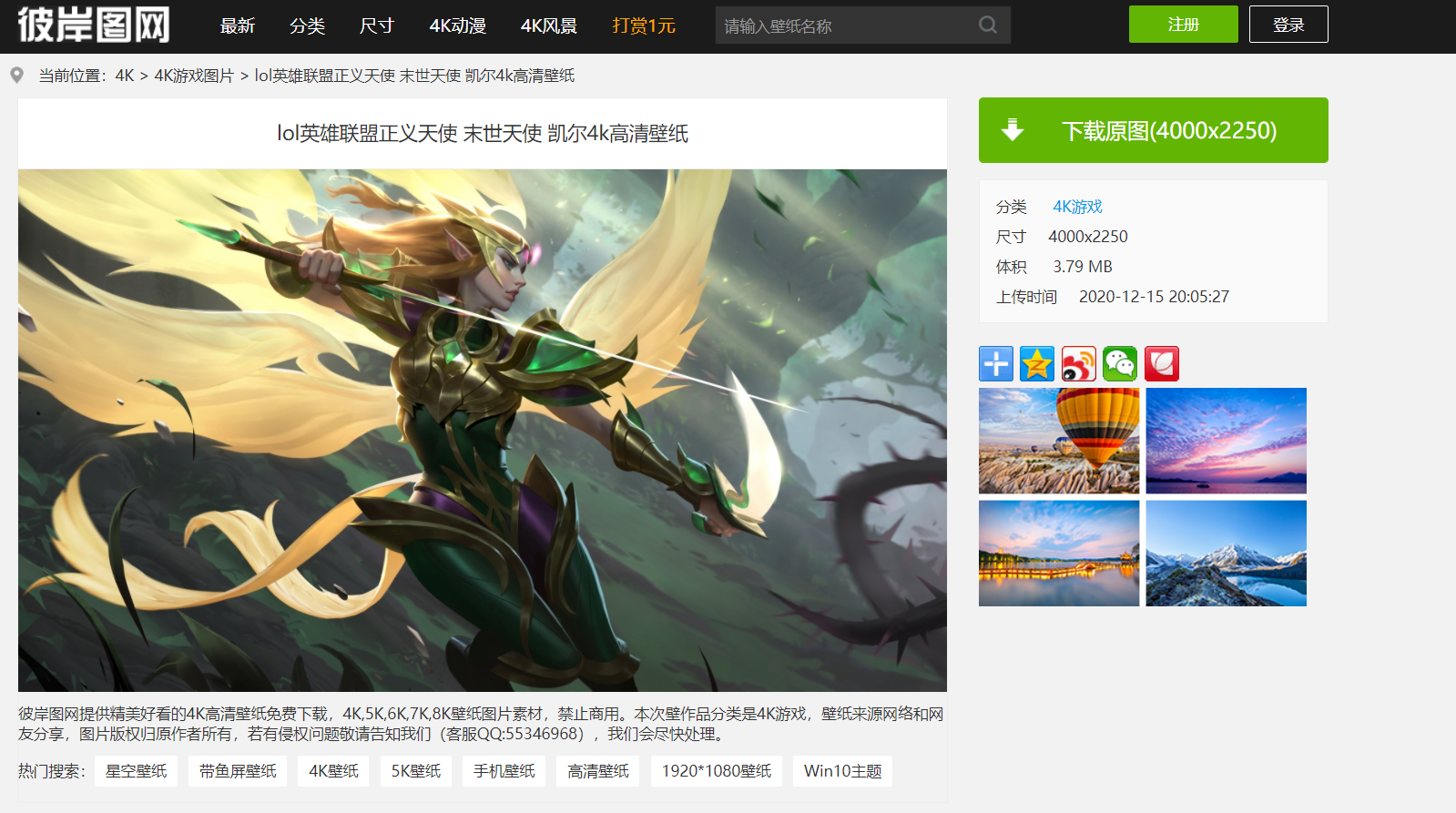
当然有个问题,如果爬取此页的图片会发现爬下来的图片是不清晰的,所以我们得爬取详情页得图片(如下图
开始分析:
1、第一页地址:http://pic.netbian.com/4kyouxi/
第二页地址:http://pic.netbian.com/4kyouxi/index_2.html
第三页地址:http://pic.netbian.com/4kyouxi/index_3.html
一对比会发现第一页与其他页地址不同,得分支处理
2、进入详情页链接,找网页源码

分析完成就可以进行编写代码了
分支处理页面地址不同
1 if __name__ == '__main__': 2 for i in range(2,20): 3 if i == 0: 4 index_base_url = 'http://pic.netbian.com/4kyouxi/index.html' 5 else: 6 index_base_url = 'http://pic.netbian.com/4kdongman/index_%s.html' 7 main(index_base_url %i)
请求网页地址(定义一个函数用于发送请求地址)
def get_html(url): res = requests.get(url) res.encoding = res.apparent_encoding return res
解析请求得页面(定义一个用于解析页面得函数)
def html_parses(text): tree = etree.HTML(text) return tree
请求详情页面(定义一个用于请求详情页得函数)
def get_img_url(url): #调用请求函数 response = get_html(url) #调用解析函数 tree = html_parses(response.text) #xpath获取图片路径 img_url = tree.xpath('//*[@id="img"]/img/@src')[0] #xpath获取图片得名字 img_name =tree.xpath('//*[@id="img"]/img/@title')[0] #调用保存函数 save(img_name,'http://pic.netbian.com'+img_url)
爬取保存至本地(定义一个用于保存得函数)
def save(name,img_url): resonse = get_html(img_url) with open('./彼岸图网/%s.jpg'%name,'wb') as f: f.write(resonse.content)
主函数
def main(url): #请求地址 response = get_html(url) #解析页面 tree = html_parses(response.text) #xpath获取图片地址 detail_urls = tree.xpath('//*[@id="main"]/div[3]/ul/li/a/@href') for i in detail_urls: #构建完整地址 get_img_url('http://pic.netbian.com' +i)
下面是完整得代码
1 import requests 2 from lxml.html import etree 3 def get_html(url): 4 res = requests.get(url) 5 res.encoding = res.apparent_encoding 6 return res 7 8 def html_parses(text): 9 tree = etree.HTML(text) 10 return tree 11 12 def main(url): 13 #请求地址 14 response = get_html(url) 15 #解析页面 16 tree = html_parses(response.text) 17 #xpath获取图片地址 18 detail_urls = tree.xpath('//*[@id="main"]/div[3]/ul/li/a/@href') 19 for i in detail_urls: 20 #构建完整地址 21 get_img_url('http://pic.netbian.com' +i) 22 def get_img_url(url): 23 #调用请求函数 24 response = get_html(url) 25 #调用解析函数 26 tree = html_parses(response.text) 27 #xpath获取图片路径 28 img_url = tree.xpath('//*[@id="img"]/img/@src')[0] 29 #xpath获取图片得名字 30 img_name =tree.xpath('//*[@id="img"]/img/@title')[0] 31 #调用保存函数 32 save(img_name,'http://pic.netbian.com'+img_url) 33 34 def save(name,img_url): 35 resonse = get_html(img_url) 36 with open('./彼岸图网/'+name+'.jpg','wb') as f: 37 f.write(resonse.content) 38 if __name__ == '__main__': 39 for i in range(2,20): 40 if i == 0: 41 index_base_url = 'http://pic.netbian.com/4kyouxi/index.html' 42 else: 43 index_base_url = 'http://pic.netbian.com/4kdongman/index_%s.html' 44 main(index_base_url %i)