0 、开篇:
(1)有十个地址信号引脚的内存IC(集成电路)可以指定的地址范围是多少?
0000000000-1111111111
2^10=1024
(2)高级编程语言中的数据类型表示的是什么?
占据内存区域的大小和存储在该内存区域的数据类型
(3)在32位内存地址的环境中,指针变量的长度是多少位?
32位
(4)与物理内存有着相同的构造的数组的数据类型长度是多少?
1字节
(5)用LIFO方式进行数据读写的数据结构称为什么?
栈
(6)根据数据的大小链表分叉位两个方向的数据结构称为什么?
二叉查找树
1、内存的物理机制很简单
① 下图是内存IC的引脚配置示例
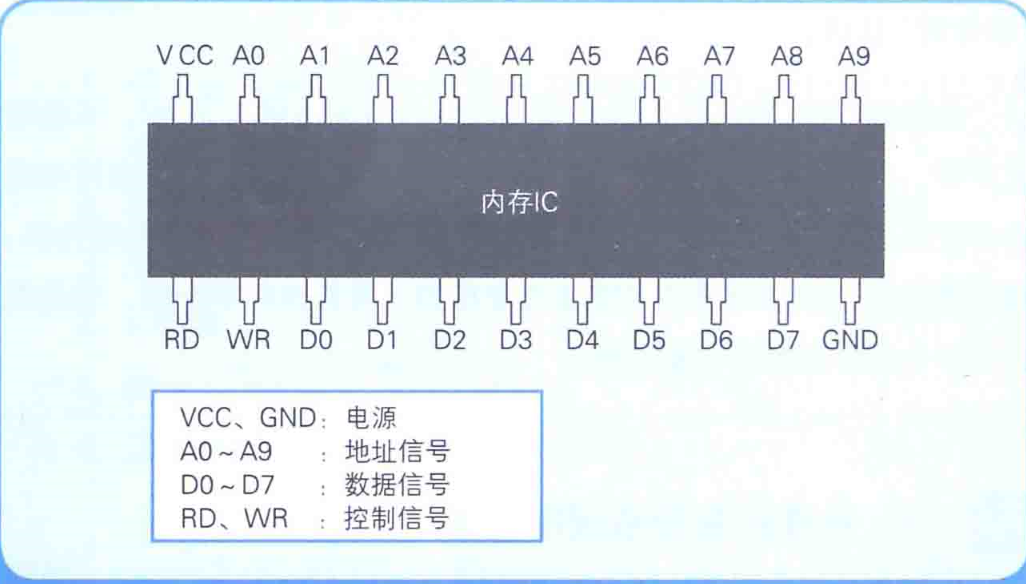
虽然这是一个虚拟的内存IC,但它的引脚和实际的内存IC是一样的。VCC和GND是电源,A0~A9是地址信号的引脚,D0~D7是数据信号的引脚,RD和WR是控制信号的引脚。将电源连接到VCC和GND后,就可以给其他引脚传递比如0或者1这样的信号。大多数情况下,+5V的直流电压表示1,0V表示0 。那么,这个内存IC中能存储多少数据呢?数据信号引脚有D0~D7共八个,表示一次可以输入输出8位(=1字节)的数据。此外,地址信号引脚有A0~A9共十个,表示可以指定0000000000~1111111111共1024个地址。而地址用来表示数据的存储场所,因此我们可以得出这个内存IC中可以存储1024个1字节的数据,即为1KB的容量。
说完容量,现在我们来说说这个如何读写数据。
写:
(1)VCC接入+5V;
(2)GND接入0V;
(3)使用A0~A9的地址信号来指定数据的存储场所;
(4)再把数据的值输入给D0~D7的数据信号;
(5)并把WR(write的简写)信号设定为1;
执行完这些操作,就可以在内存IC内部写入数据,可以见下图:

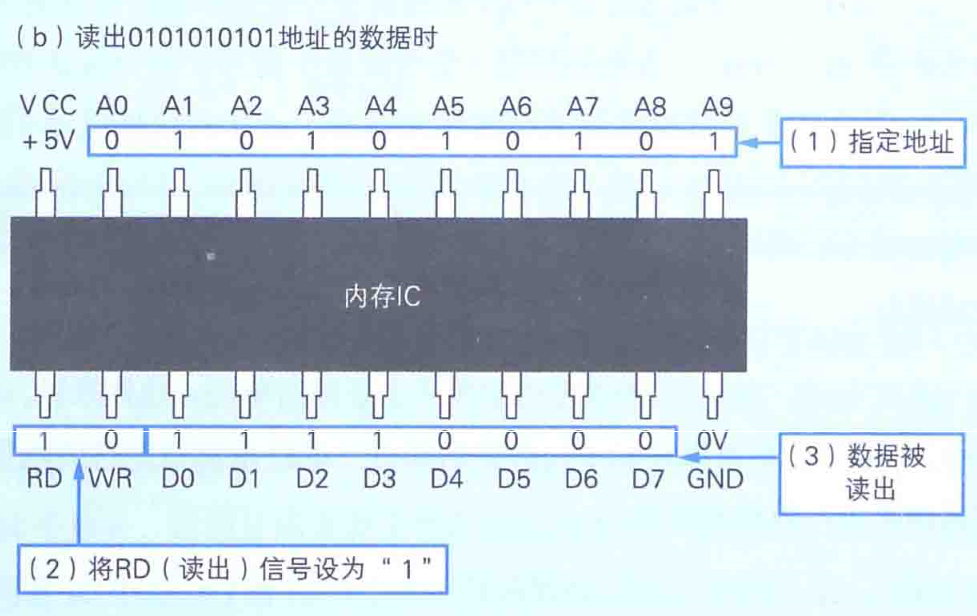
读:
读取数据时,只需要通过A0~A9的地址信号指定数据的存储场所,然后再将RD(read的简写)信号设成1即可。执行完这些操作,指定地址中存储的数据就会被输出到D0~D7的数据信号引脚。如下图:
2、内存的逻辑模型是楼房
虽然内存的实体是内存IC,不过从程序员的角度来看,也可以把它假想成都存储着数据的楼房,并不需要过多地关注内存的电源和控制信号等。我们来看一下下图,内存为1KB时的表示方式(这里地址的值是从上往下逐渐变大)

不过,在程序员眼里的内存模型中,还包含着物理内存不存在的概念,那就是数据类型。编程语言中的数据类型表示存储的是何种类型的数据,从内存上看,就是占用的内存大小(占有的楼层数)的意思。即使是物理上以1个字节位单位来逐一读写数据的内存,在程序中,通过制定其类型,也能实现以特定字节数位单位来进行读写。下面我们来看一个具体的示例:

这3个变量的数据类型分别是,表示1字节长度的char,表示2字节长度的short,以及表示4字节长度的long。因此,虽然同样是数据123,存储时其所占用的内存大小是不一样的。这里我们假定采用的是将数据低位存储在内存低位地址的低字节序方式。

假设一下,如果程序中只能逐个字节地对内存进行读写,那该多么不便啊。在处理超过1个字节的数据时,还必须要编写分割处理程序。此外,在不同的编程语言中,变量可以指定的数据类型的最大长度也不同。
3、简单的指针
接下来,我们来看一下指针。指针是C语言的重要特征。很多人都说指针难以理解,其实对已经阅读到现在的各位读者来说,指针应该很容易理解。理解指针的关键点就是要弄清楚数据类型这个概念。
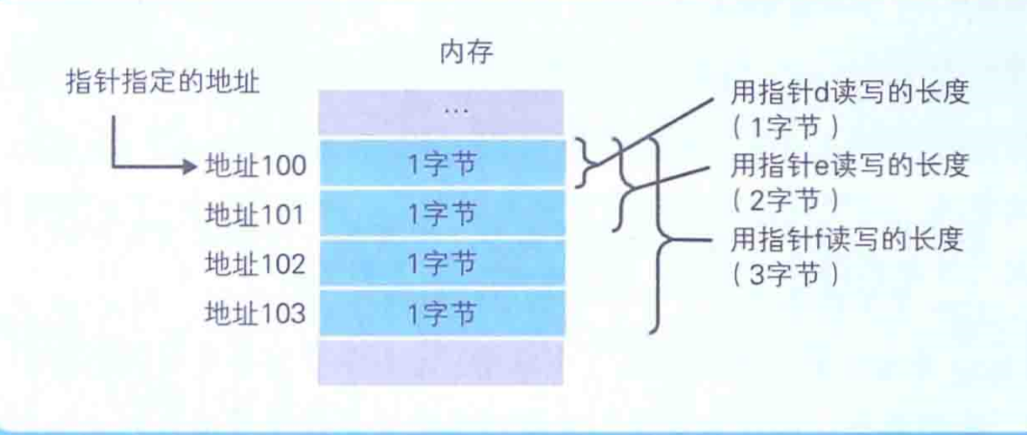
指针也是一种变量,它表示的不是数据的值,而是存储着数据的内存的地址。通过使用指针,就可以对任意指定地址的数据进行读写。一般Windows计算机上使用的程序通常都是32位(4字节)的内存地址,这种情况下,指针的变量的长度也是32位。看下图的各种数据类型指针的定义:

假设d、e、f的值都是100 。在这种情况下,使用d时就能够从编号100的地址中读写1个字节的数据,使用e时就是2个字节(100地址和101地址)的数据,使用f时就是4个字节(100地址~103地址)的数据。瞧,指针是不是很简单,见下图:
4、数组是高效使用内存的基础
让我们回到主题“熟练使用有棱有角的内存”,在熟练之前,我们先来看一下内存最直接的使用方法。在这里,我们要用到数组。
数组是指多个同样数据类型的数据在内存中连续排列的形式。最作为数组元素的各个数据会通过连续的编号被区分开来,这个编号称为索引(index)。指定索引后,就可以对该索引所对应地址的内存进行读写操作(这个在第一章有讲过:CPU是通过利用基址寄存器和变址寄存器来指定内存地址的)。索引和内存地址的变换工作则是由编译器自动实现的。

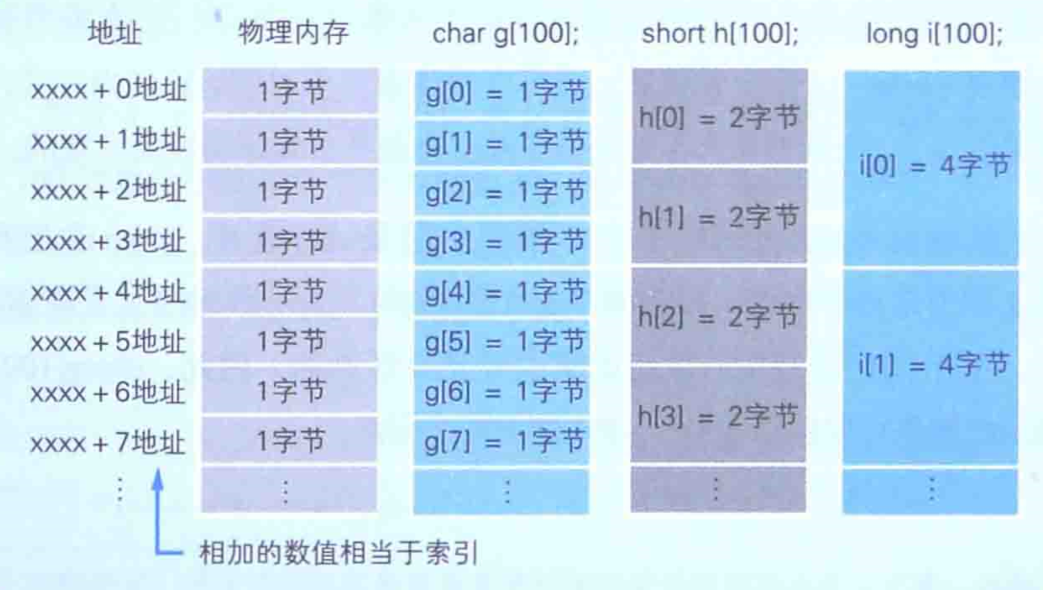
char类型的数组以1个字节为单位对内存进行读写;
short类型的数组以2个字节为单位对内存进行读写;
long类型的数组以4个字节为单位对内存进行读写。
之所以说数组是内存的使用方法的基础,是因为数组和内存的物理构造是一样的。特别是1字节类型的数组,它和内存的物理构造完全一致。
使用数能够使编程工作变得更加高效。如果在反复运行的循环处理中使用数组,很短的代码就能达到按顺序读写。不过,虽然是通过指定索引来使用数组,但这和内存的物理读写并没有特别大的区别。因此很多程序都会在数组的使用上花费大量功夫,下面会介绍一些数组的变形方法。
5、栈、队列以及环形缓冲区
栈和队列对程序员来说再也熟悉不过了,它们都可以不通过指定地址和索引来对数组的元素进行读写。
栈和队列的区别在于数据出入的顺序是不同的。在对内存数据进行读写时,栈用的是LIFO(Last Input First Out,后入先出)方式,而队列用的则是FIFO(First Input First Out,先入先出)方式。
如果要在程序中实现栈和队列,就需要以适当的元素数来定义一个用来存储数据的数组,以及对该数组进行读写的函数对。当然,在这些函数的内部,对数组的读写会涉及索引的管理,但从使用函数的角度来说,就没有必要考虑数组及索引了。
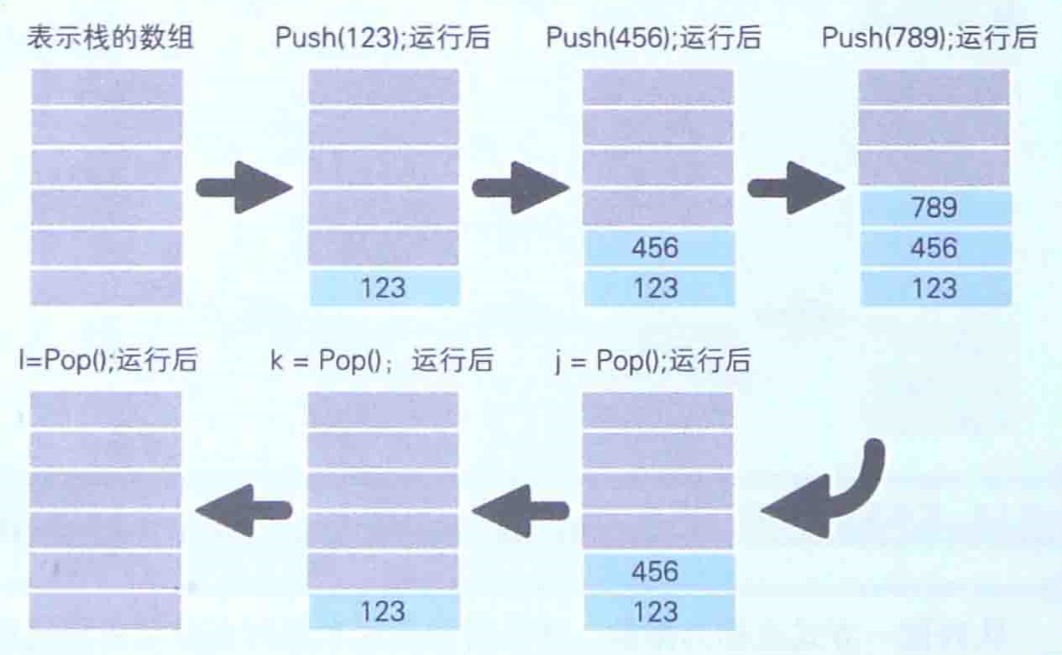
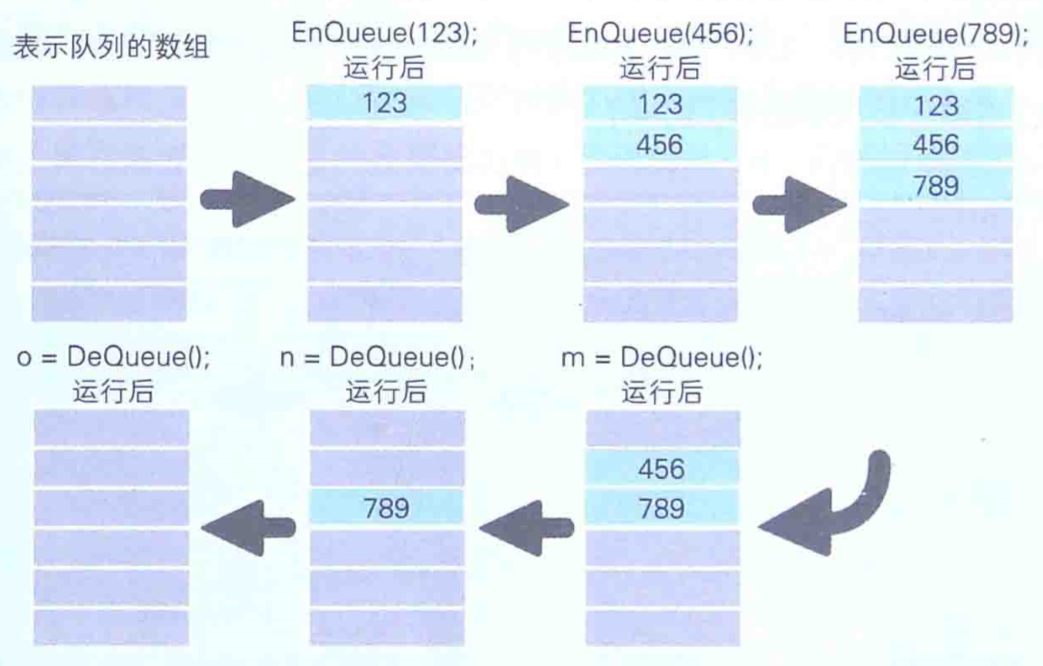
这里,我们暂且把往栈中写入数据的函数命名为Push,把从栈中读出数据的函数命名为Pop,把往队列中写入数据的函数命名为EnQueue,把从队列中读出数据的函数命名为DeQueue。通过使用这些函数,可以将数据临时保存(写入),然后再在需要时把这些数据读出来:
在栈中,LIFO方式表示栈的数组中所保存的最后面的数据会被最先读取出来,代码运行后,按照123、 456 、789的顺序写入的数据,结果却按照789 、456 、123的顺序被读取出来。
队列,FIFO方式表示队列的数组中所 保存的最初数据会最先被读取出来。上述代码运行后,按照123 、 456 、789 的顺序写入的数据,结果会按照123 、456 、789 的顺序被读出来。
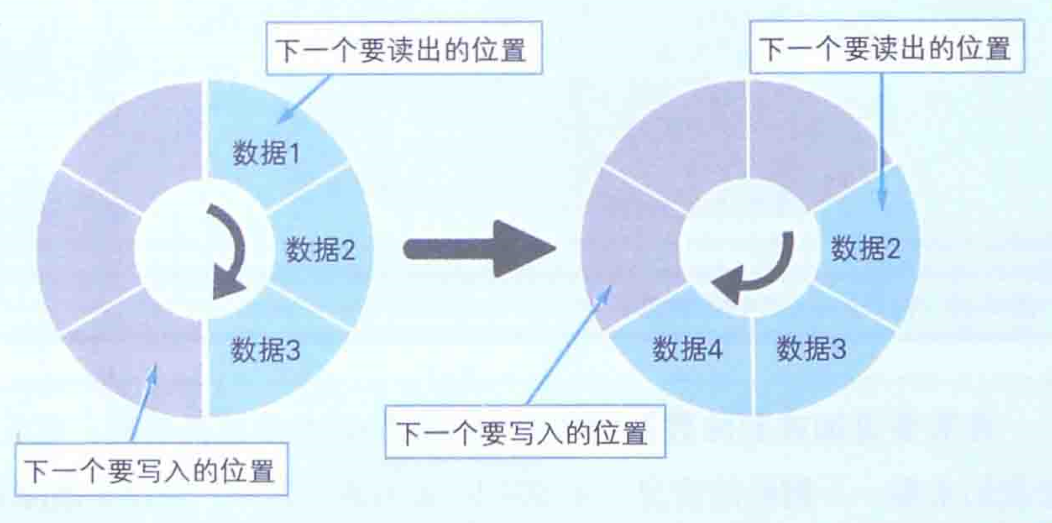
队列一般是以环状缓冲区(ring buffer)的方式来实现的,也就是本章标题中所说的“熟练使用有棱有角的内存”。例如,假设我们要用6个元素的数组来实现一个队列。这时可以从数组的起始位置开始有序存储数据,然后再按照存储时的顺序吧数据读出。在数组的末尾写入数据后,后一个额数据就会被写入数组的起始位置(此时数据已经被读出所以该位置是空的)。这样,数组的末尾就和开头连接了起来,数据的写入和读出也就循环起来了,如下图:
6、链表使元素的追加和删除更容易
接下来就介绍链表和二叉查找树,都是不用考虑索引的顺序就可以对数组元素进行读写的方式。通过使用链表,可以更加高效地对数组元素进行追加和删除处理。而通过使用二叉查找树,则可以更加高效地对数组数据进行检索。
在数组的各个元素中,除了数据的值之外,通过为其附带上下一个元素的索引,即可实现链表。数据的值和下一个元素的索引组合在一起,就构成了数组的一个元素。

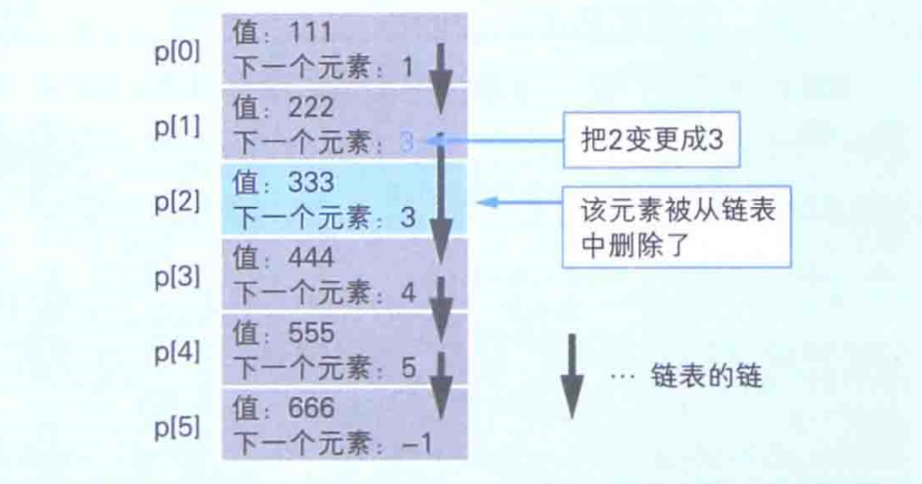
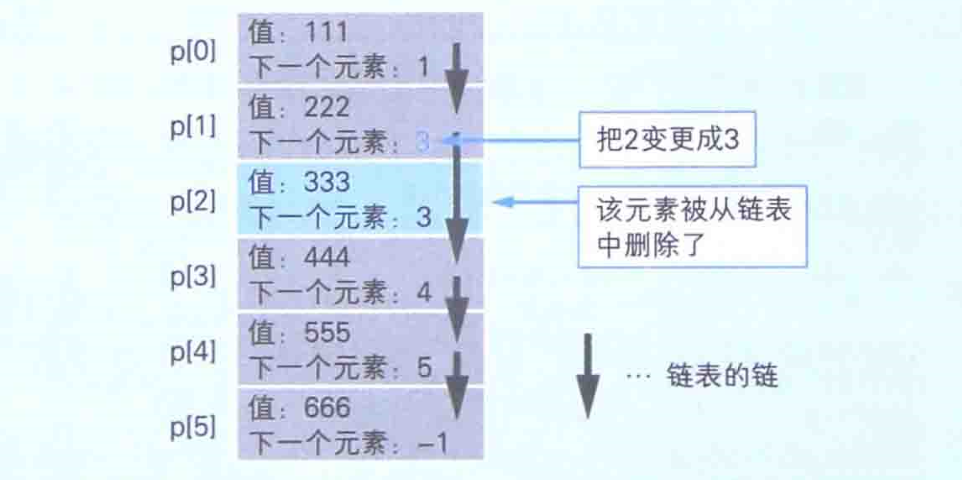
在需要追加或删除数据的情况下,使用链表使很高效的。下图就是链表进行删除的过程:
假设我们删除第3个元素,就可以把第2个元素的“下一个元素:2”变成“下一个元素:3”即可。
下图再展示一个如何往链表中追加数据:
假设要在第5个元素之前追加一个新数据。此时,我们只需要在刚才消除的第3个元素的位置中保存新的数据,并将第4个元素的“下一个元素:5”变更成“下一个元素:2”,以使新追加的元素的索引信息变成“下一个元素:5”即可。
链表与数组相比,最大的好处是中途删除或追加元素时,其后的元素不必要进行全部的移动,而数组就必须移动其后全部的元素,这在高速计算机中也会花费很长时间,如下两张图:


7、二叉查找树使数据搜索更有效
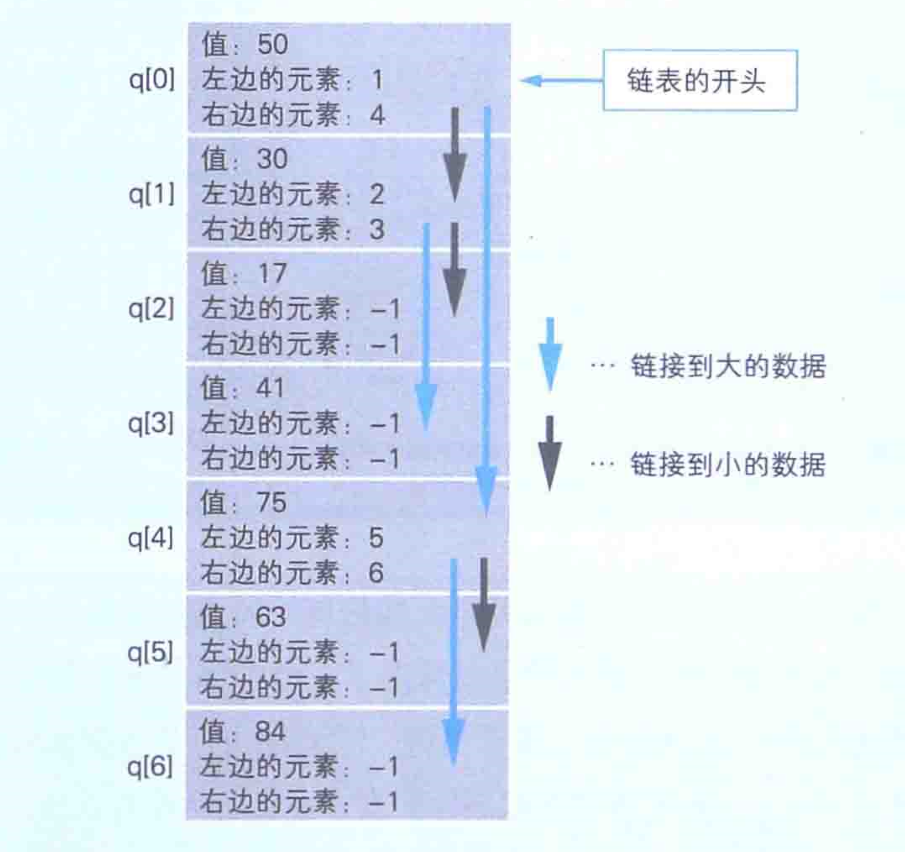
二叉查找树是指在链表的基础上往数组中追加元素时,考虑到数据的大小关系,将其分成左右两个方向的表现形式。例如,假设我们事先把50这个值保存到了数组中,那么如果接下来的值比先前保存的数值大的话,就要将其放到右边,反之如果小的话就放在左边。但实际的内存并不会分成两个方向,这是在程序逻辑上实现的。
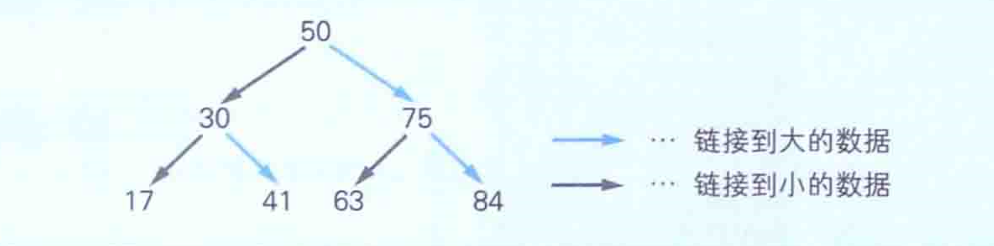
在程序中如何实现呢,其实数组的每个元素中只要有数据的值和两个索引信息就可以了。如下图展示了如何用数组来实现二叉查找树了。