现在我们已经基本熟悉了GIT的基本操作了,接下来该执行研究一下GIT的几个比较重要的组件,GIT有四个常用的组件
- Tag
- Commit
- Tree
- BLOB
最重要的是后面的三个,Tag组件在介绍了标签之后再来说明。后三个组件管理着GIT的所有版本文件。
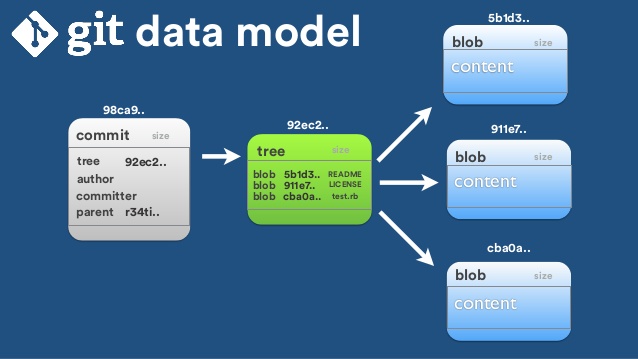
如图所示:Commit组件包含了Tree,Tree组件中又有Blob组件,那么组件究竟有什么意义,又是以什么的方式被应用了,通过具体的实例来说明,首先,初始化一个目录为GIT的Repository,之后查看一下.git目录
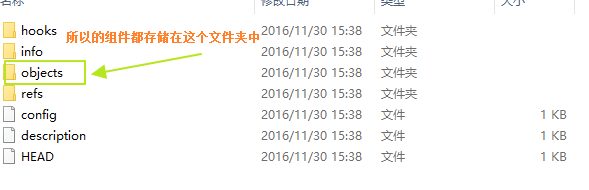
所有的组件都存储在objects文件夹中,初始化之后只会有info和pack两个文件夹,接着我们使用echo a > a.txt来创建一个文件,并且使用git add .将其提交给GIT的Stage,此时再看一下objects文件夹

此时多了一个f5的文件夹,里面有一个文件名很长的文件,这个文件夹就是一个blob组件,当每次把文件设置为Staged状态的时候,就会在objects中创建一个Blob组件,这里需要强调一下,GIT中每个组件都是以hash的二进制方式来存储,这个组件的名称就是文件夹名称+文件夹中的文件的名称,这个hash码是唯一的,我们刚才所创建的组件的hash码就是f5eea678d87a8664e4c76e12d3ef5c4ff775ad58,这也是组件的唯一标示。
blob组件并不会对文件信息进行存储,而是对文件的内容进行记录的(note:不同的文件a.txt,b.txt,但是文件的内容一致的化,那么blob对象就是一致; 同一个文件a.txt,因为内容的修改不一样,从而会生成新的blob对象),我们执行下一个操作,echo b > a.txt添加一个文件,我们把a.txt中的内容替换成b(原来是a),此时文件的状态变成Modified状态,再次通过git add .提交文件到Stage。
此时再观察objects目录
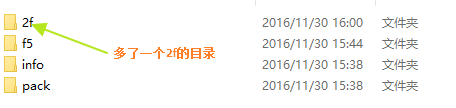
多了一个2f的目录,虽然我们的文件没有发生变化,但是内容发生了变化,此时git会再次创建一个blob组件存储到objects文件夹中,我们再次执行下一个操作echo b > b.txt该命令会创建一个新的文件b.txt,但是文件的内容和a.txt一样,然后使用git add .添加到Stage中
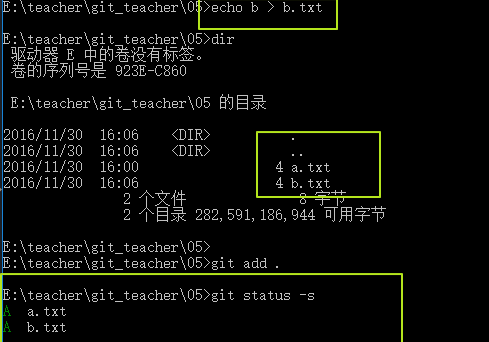
目前a.txt和b.txt都是属于Staged状态,此时再去objects文件夹中看一下。
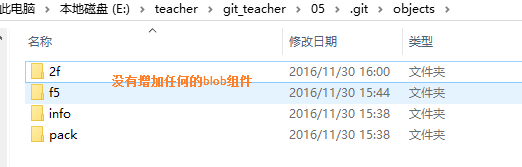
并没有增加任何blob组件,因为b.txt的内容其实和a.txt一样,所以git发现这个blob已经存在了,就不会再增加新的组件。
再次强调一下blob组件是在代码提交到Stage区域的时候生成的,而且是以内容来生成一个字节码文件
我们可以通过命令git hash-object 文件名查询文件的hash码
E: eachergit_teacher�5>git hash-object a.txt
2fea07c1b36b55a95b543c7bd0decbd6798bf9b9
E: eachergit_teacher�5>git hash-object b.txt
2fea07c1b36b55a95b543c7bd0decbd6798bf9b9
我们的a.txt和b.txt是完全一样的名称,这个hash码就是我们的blob组件的名称,再去对应一下文件夹和文件夹中的文件名。
了解了blob组件只会,我们执行下面一个操作,我们把Staged中的内容提交到工厂中,提交之前请观察objects文件夹,执行git commit -m "init"之后。

我们会发现多了两个文件夹d6和f5,这两个文件夹究竟是什么呢(note:多的2个,一个是tree对象,一个是commit对象)?我们通过git log看一下
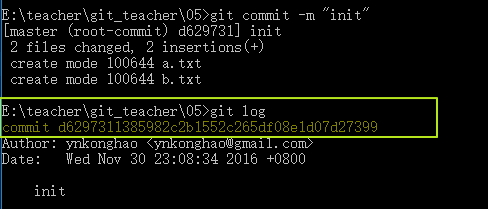
我们看到了一个commit d6297311385982c2b1552c265df08e1d07d27399,这就是我们即将要探讨的commit组件了,而后面这串hash就是这个组件的id,在git中所有的组件都是以hash来存储的,刚才讲的blob也是一样,而且都是以hash的前两位为文件夹,剩余的位数作为文件名。
commit组件在每次提交之后都会生成,当我们进行commit之后,首先会创建一个commit组件,之后把所有的文件信息创建一个tree组件,然后把Stage Area中的blob组件封装在tree中完成一次提交,我们可以通过如下命令查询commit组件
git cat-file -p d6297
cat-file可以获取这个组件的信息d6297就是组件id的缩写(只要写前面的5位git会自动找到这个组件)
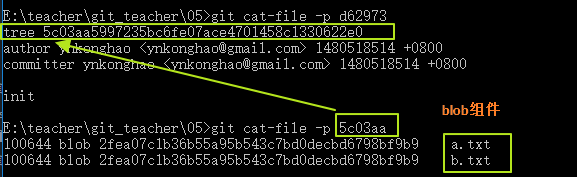
我们会发现commit组件下有一个tree组件,依然也是用hash来作为这个tree组件的名称,之后cat-file一下这个tree组件,我们发现了最开始提交的两个blob组件,而在tree组件中记录了文件的基本信息。
现在我们应该明白git底层的运行流程了,当我们添加或者修改了文件并且add到Stage Area之后,首先会根据文件内容创建不同的blob,当进行提交之后马上创建一个tree组件把需要的blob组件添加进去,之后再封装到一个commit组件中完成本次提交。在将来进行reset的时候可以直接使用git reset --hard xxxxx可以恢复到某个特定的版本,在reset之后,git会根据这个commit组件的id快速的找到tree组件,然后根据tree找到blob组件,之后对仓库进行还原,整个过程都是以hash和二进制进行操作,所以git执行效率非常之高。
最后我们再看一个例子,我们创建一个文件夹,然后再文件夹中创建一个文件,这里希望大家跟着我的命令来思考,组件的创建情况。最后来进行验证,看看我们是否真正掌握了git的组件
mkdir test
cd test
echo hello world >> b.txt
这三个命令之后,会创建一个test的文件夹,之后再创建一个b.txt的文件,并且加入hello world这个内容,我们进行提交之后,想想会创建些什么组件?
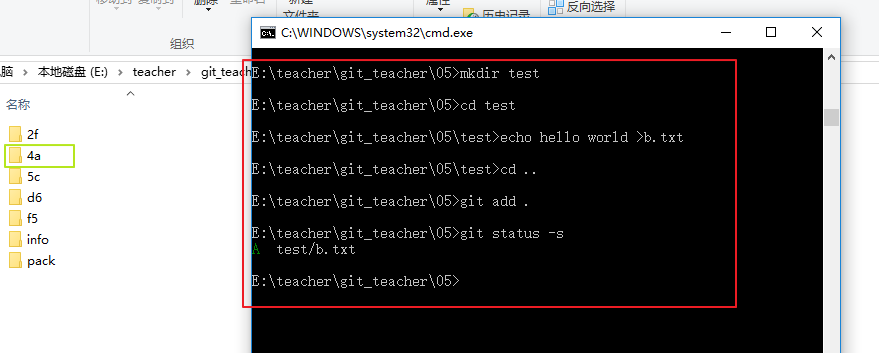
由于b.txt的内容不一致,所以会创建一个blob组件,我这里是以4a开头的,之后进行提交
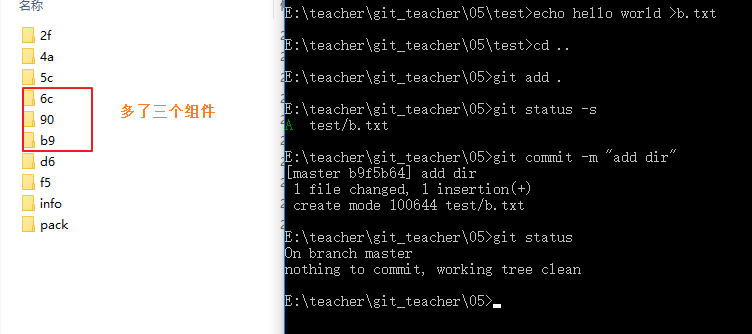
我们会发现多了三个组件,按道理来说应该只会创建一个commit组件,之后根据文件信息生成tree组件,最后把blob组件添加进去,应该只会多1个commit和1个tree,为什么会有三个呢?我们通过cat-file来进行查询
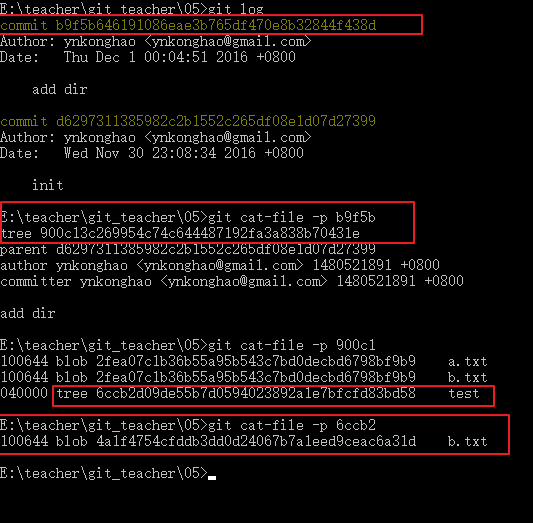
我们会发现首先生成了一个commit组件,这个commit中有一个tree,然后tree中处理a.txt和b.txt外还有一个tree组件,这个组件其实就是我们的文件夹,这个tree下面有新增加的b.txt的blob组件。所以我们如果新增加了一个文件夹,就会为这个文件夹创建一个tree组件。
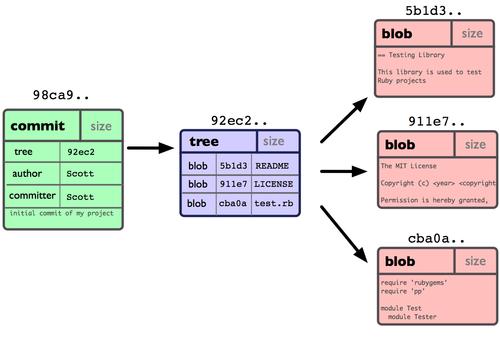
图 3-1. 单个提交对象在仓库中的数据结构
作些修改后再次提交,那么这次的提交对象会包含一个指向上次提交对象的指针(译注:即下图中的 parent 对象)。两次提交后,仓库历史会变成图 3-2 的样子:

图 3-2. 多个提交对象之间的链接关系