一. LinkedList的数据结构
LinkedList是一种可以在任何位置进行高效地插入和移除操作的有序序列,它是基于双向链表实现的。

基础知识补充
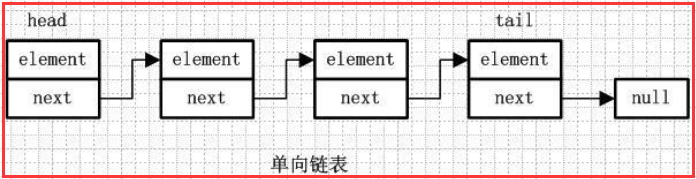
1.1 单向链表
element:用来存放元素
next:用来指向下一个节点元素
通过每个结点的指针指向下一个结点从而链接起来的结构,最后一个节点的next指向null。
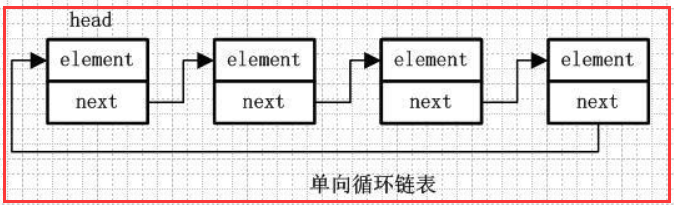
1.2 单向循环链表
element、next 跟前面一样
在单向链表的最后一个节点的next会指向头节点,而不是指向null,这样存成一个环
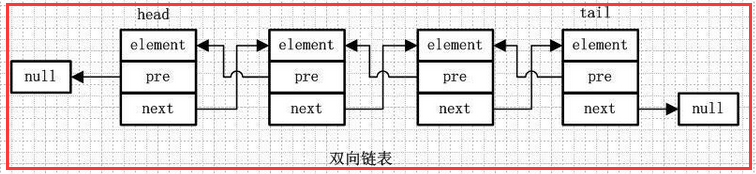
1.3 双向链表
element:存放元素
pre:用来指向前一个元素
next:指向后一个元素
双向链表是包含两个指针的,pre指向前一个节点,next指向后一个节点,但是第一个节点head的pre指向null,最后一个节点的tail指向null。
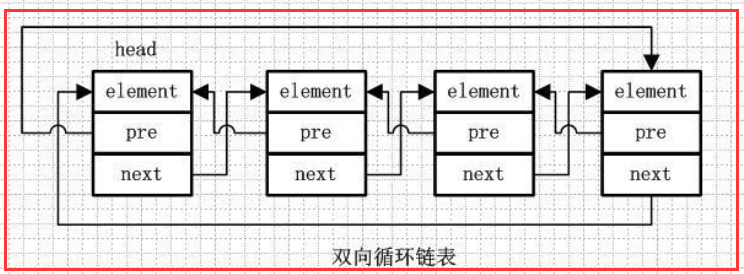
1.4 双向循环列表
element、pre、next 跟前面的一样
第一个节点的pre指向最后一个节点,最后一个节点的next指向第一个节点,也形成一个“环”。
二. LinkedList的源码分析
2.1 类的定义


1 public class LinkedList<E> 2 extends AbstractSequentialList<E> 3 implements List<E>, Deque<E>, Cloneable, java.io.Serializable
分析:LinkedList的类继承结构很有意思,我们着重要看是Deque接口,Deque接口表示是一个双端队列,那么也意味着LinkedList是双端队列的一种实现,所以,基于双端队列的操作在LinkedList中全部有效。相比ArrayList,发现少了RandomAccess接口,那么就推荐使用iterator,在其中就有一个foreach,增强的for循环,其中原理也就是iterator,我们在使用的时候,使用foreach或者iterator都可以。
note: linkedList在执行任何操作的时候,都必须先遍历此列表来靠近通过index查找我们所需要的的值。通俗点讲,这就告诉了我们这个是顺序存取,每次操作必须先按开始到结束的顺序遍历;随机存取,就是arrayList,能够通过index。随便访问其中的任意位置的数据,这就是随机列表的意思。既然有了上面这句话,那么以后如果自己想实现顺序存取这种特性的类(就是链表形式),那么就继承这个AbstractSequentialList抽象类,如果想像数组那样的随机存取的类,那么就去实现AbstracList抽象类。
2.2 类中的成员变量
1 // 实际元素个数 2 transient int size = 0; 3 // 头结点 4 transient Node<E> first; 5 // 尾结点 6 transient Node<E> last;
分析:LinkedList的属性非常简单,一个头结点、一个尾结点、一个表示链表中实际元素个数的变量。注意,头结点、尾结点都有transient关键字修饰,这也意味着在序列化时该域是不会序列化的。
2.3 类的构造函数
该类中的构造函数有两个,分别如下:
1 /** 2 * Constructs an empty list. 3 */ 4 public LinkedList() { 5 } 6 7 8 /** 9 * Constructs a list containing the elements of the specified 10 * collection, in the order they are returned by the collection's 11 * iterator. 12 * 13 * @param c the collection whose elements are to be placed into this list 14 * @throws NullPointerException if the specified collection is null 15 */ 16 public LinkedList(Collection<? extends E> c) { 17 this(); 18 addAll(c); 19 }
分析:前者构造出一个空集合,而后者则会调用无参构造函数,并且会把集合c中所有的元素添加到LinkedList中。
2.4 类中的内部类
1 //根据前面介绍双向链表就知道这个代表什么了,linkedList的奥秘就在这里。 2 private static class Node<E> { 3 E item; // 数据域(当前节点的值) 4 Node<E> next; // 后继(指向当前一个节点的后一个节点) 5 Node<E> prev; // 前驱(指向当前节点的前一个节点) 6 7 // 构造函数,赋值前驱后继 8 Node(Node<E> prev, E element, Node<E> next) { 9 this.item = element; 10 this.next = next; 11 this.prev = prev; 12 } 13 }
分析:内部类Node就是实际的结点,用于存放实际元素的地方。
2.5 类的成员方法
还是依照增删改查的顺序说明:
(1)add
1 public boolean add(E e) { 2 linkLast(e); 3 return true; 4 } 5 6 /** 7 * Links e as last element. 8 */ 9 void linkLast(E e) { 10 final Node<E> l = last; 11 final Node<E> newNode = new Node<>(l, e, null); 12 last = newNode; 13 if (l == null) 14 first = newNode; 15 else 16 l.next = newNode; 17 size++; 18 modCount++; 19 }
分析:调用add方法会将元素默认添加到集合的末尾。
举例说明:
A) 例一:
List<Integer> lists = new LinkedList<Integer>(); lists.add(5); lists.add(6);
说明:首先调用无参构造函数,之后添加元素5,之后再添加元素6。具体的示意图如下:
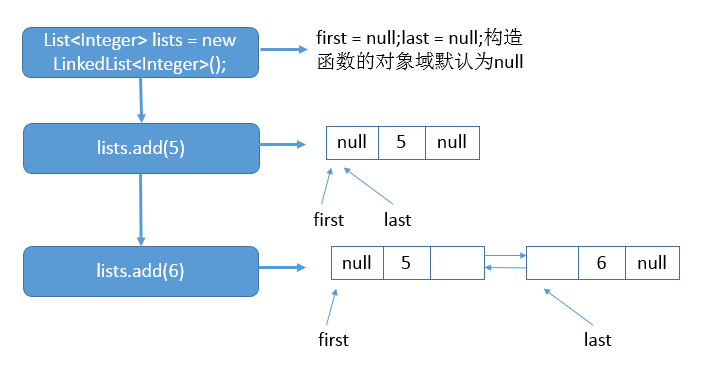
说明:上图的表明了在执行每一条语句后,链表对应的状态。
(2)remove
1 public E remove(int index) { 2 checkElementIndex(index); 3 return unlink(node(index)); 4 } 5 6 /** 7 * Unlinks non-null node x. 8 */ 9 E unlink(Node<E> x) { 10 // assert x != null; 11 final E element = x.item; 12 final Node<E> next = x.next; 13 final Node<E> prev = x.prev; 14 15 if (prev == null) { 16 first = next; 17 } else { 18 prev.next = next; 19 x.prev = null; 20 } 21 22 if (next == null) { 23 last = prev; 24 } else { 25 next.prev = prev; 26 x.next = null; 27 } 28 29 x.item = null; 30 size--; 31 modCount++; 32 return element; 33 }
(3)set
1 public E set(int index, E element) { 2 checkElementIndex(index); 3 Node<E> x = node(index); 4 E oldVal = x.item; 5 x.item = element; 6 return oldVal; 7 }
分析:类似ArrayList中的实现,知识ArrayList中式修改elementData数组中的值,而这里修改的式Node.item选项的值。
(4)get
1 public E get(int index) { 2 checkElementIndex(index); 3 return node(index).item; 4 } 5 6 /** 7 * Returns the (non-null) Node at the specified element index. 8 */ 9 //这里查询使用的是先从中间分一半查找 10 Node<E> node(int index) { 11 // assert isElementIndex(index); 12 //"<<":*2的几次方 “>>”:/2的几次方,例如:size<<1:size*2的1次方, 13 //这个if中就是查询前半部分 14 if (index < (size >> 1)) {//index<size/2 15 Node<E> x = first; 16 for (int i = 0; i < index; i++) 17 x = x.next; 18 return x; 19 } else {//前半部分没找到,所以找后半部分 20 Node<E> x = last; 21 for (int i = size - 1; i > index; i--) 22 x = x.prev; 23 return x; 24 } 25 }
三. LinkedList的性能分析
LinkedList随机访问效率低,但随机插入、随机删除效率高。
3.1 为何随机访问效率低
通过get(int index)获取LinkedList第index个元素时。先是在双向链表中找到要index位置的元素;找到之后再返回。
双向链表查找index位置的节点时,有一个加速动作:若index < 双向链表长度的1/2,则从前向后查找; 否则,从后向前查找。
而ArrayList通过get(int index)获取ArrayList第index个元素时。直接返回数组中index位置的元素,而不需要像LinkedList一样进行查找。
3.2 为何随机插入、删除效率高
通过add(int index, E element)向LinkedList插入元素时。先是在双向链表中找到要插入节点的位置index;找到之后,再插入一个新节点。
双向链表查找index位置的节点时,有一个加速动作:若index < 双向链表长度的1/2,则从前向后查找; 否则,从后向前查找。
而System.arraycopy(elementData, index, elementData, index + 1, size - index); 会移动index之后所有元素即可。这就意味着,ArrayList的add(int index, E element)函数,会引起index之后所有元素的改变!
note:本文部分内容来自:https://www.cnblogs.com/zhangyinhua/p/7688304.html