public void Test1() { //建立一个内存目录 Lucene.Net.Store.RAMDirectory ramDir = new Lucene.Net.Store.RAMDirectory(); //建立一个索引书写器 IndexWriter ramWriter = new IndexWriter(ramDir,new ChineseAnalyzer(), true); //要索引的词,这就相当于一个个的要索引的文件 string[] words = {"中华人民共和国", "人民共和国", "人民","共和国"}; //循环数组,创建文档,给文档添加字段,并把文档添加到索引书写器里 Document doc = null; for (int i = 0; i < words.Length; i++) { doc = new Document(); doc.Add(Field.Text("contents", words[i])); ramWriter.AddDocument(doc); } //索引优化 ramWriter.Optimize(); //关闭索引读写器,一定要关哦,按理说应该把上面的代码用try括主,在finally里关闭索引书写器 ramWriter.Close(); //构建一个索引搜索器 IndexSearcher searcher = new IndexSearcher(ramDir); //用QueryParser.Parse方法实例化一个查询 Query query = QueryParser.Parse("中华人民","contents",new ChineseAnalyzer()); //获取搜索结果 Hits hits = searcher.Search(query); //判断是否有搜索到的结果,当然你也可以遍历结果集并输出 if (hits.Length() != 0) MessageBox.Show("有"); else MessageBox.Show("没有"); }
以下为分词组件:
【分享】Lucene.Net的中文分词组件AdvancedChineseAnalyzer
库名称:AdvancedChineseAnalyzer 高级中文文本分析器
描述:A Chinese Analyzer that utilizes HMM. 基于隐马尔科夫模型的中文分析器。
运行环境:Microsoft .Net Framework 2.0
依存软件:Lucene.Net
作者:Kelvin ZHANG (kelvin.cn{@t}56.com)
授权:Free for noncommercial use 对非盈利使用免费
下载:
https://files.cnblogs.com/KelvinZhang/AdvancedChineseAnalyzer.part1.rar
https://files.cnblogs.com/KelvinZhang/AdvancedChineseAnalyzer.part2.rar
https://files.cnblogs.com/KelvinZhang/AdvancedChineseAnalyzer.part3.rar
【1】为什么要分词?
减小索引大小,减少搜索开销,提高响应速度,改善搜索结果的相关性。
【2】与以往Lucene.Net的NLS包中提供的ChineseAnalyzer有什么不同?
NLS中的ChineseAnalyzer只简单地将连续字串两两组合,例如,对“文本分析器”进行分析,将得到“文本”、“本分”、“分析”和“析器”。而使用AdvancedChineseAnalyzer分析,将得到“文本”、“分析器”两个Tokens。AdvancedChineseAnalyzer的分词算法有两种,一种基于“上下文无关的词频优选”,第二种则是基于“一阶隐马尔科夫模型(HMM)”。
【3】这两种算法的分词正确率和速度各如何?
排除人名,地面等专有未登录词不算,HMM模式下切分正确率达到98%,非HMM模式下达到94%左右。HMM模式每秒可以处理75kbps文本,非HMM模式速度在100kbps左右。两种模式可以自由切换。
【4】怎样才能将AdvancedChineseAnalyzer结合Lucene.Net使用?
1 Lucene.Net.Analysis.Analyzer objCA = new Lucene.Net.Analysis.China.ChineseAnalyzer();
然后把objCA传递给IndexWriter的构造函数就可以了。
【5】AdvancedChineseAnalyzer是免费的吗?
是的,个人以非盈利目的的使用是免费的。但作者不提供技术支持,也不保证AdvancedChineseAnalyzer没有问题。Use it at your own risk.
【6】如何开启HMM模式?
1 Lucene.Net.Analysis.China.ConfigParameter.UseHmm = true;
【7】为何输入文本和输出的不一样,少了很多(见图)?
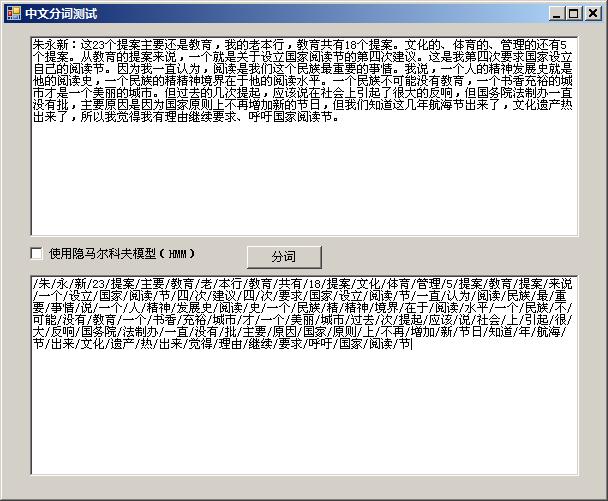
已经过滤了停用词。常见的无意义虚词、标点符号、英文停用词等都已经过滤掉了。