在上一周的工作中,已经构造了500张图片的数据集。这一周的主要工作则是用该数据集训练自己的模型。
在网上下载faster r-cnn的代码,修改数据集的地址,手动添加modle文件夹,我自己重新构造后的文件夹目录如下:
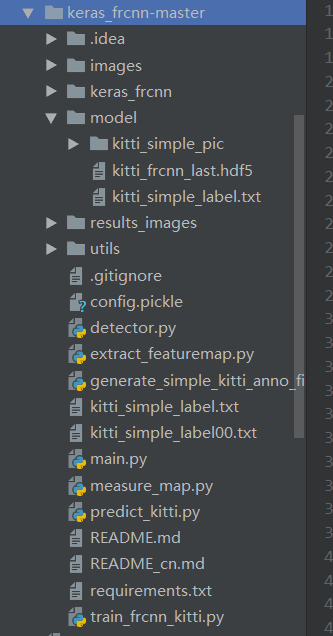
其中,model文件夹目录下的 kitti_frcnn_last.hdf5 为自动生成的模型(还没有修改该模型)
一、构造要训练的函数,并且设置参数:
def train_kitti():
# config for data argument
cfg = config.Config()
cfg.use_horizontal_flips = True 使用水平滑动窗口
cfg.use_vertical_flips = True 使用垂直滑动窗口
cfg.rot_90 = True 90度翻转(应该为了使用互相关操作)
cfg.num_rois = 32
cfg.base_net_weights = os.path.join('./model/', nn.get_weight_path()) 权重
# TODO: the only file should to be change for other data to train
cfg.model_path = './model/kitti_frcnn_last.hdf5' 模型的位置
cfg.simple_label_file = 'kitti_simple_label.txt' 数据集的位置
print(cfg.simple_label_file)
all_images, classes_count, class_mapping = get_data(cfg.simple_label_file) 定义所有的图像,类别数,池化
if 'bg' not in classes_count:
classes_count['bg'] = 0
class_mapping['bg'] = len(class_mapping)
cfg.class_mapping = class_mapping
with open(cfg.config_save_file, 'wb') as config_f: 打开配置文件
pickle.dump(cfg, config_f)
print('Config has been written to {}, and can be loaded when testing to ensure correct results'.format(
cfg.config_save_file))
inv_map = {v: k for k, v in class_mapping.items()}
print('Training images per class:')
pprint.pprint(classes_count)
print('Num classes (including bg) = {}'.format(len(classes_count)))
random.shuffle(all_images) 在所有的图像中随机获取一部分(已经将训练集和验证机按7:3分开了)
num_imgs = len(all_images) 获取数量
train_imgs = [s for s in all_images if s['imageset'] == 'trainval'] 获取训练集
val_imgs = [s for s in all_images if s['imageset'] == 'test'] 获取验证机
print('Num train samples {}'.format(len(train_imgs)))
print('Num val samples {}'.format(len(val_imgs)))
data_gen_train = data_generators.get_anchor_gt(train_imgs, classes_count, cfg, nn.get_img_output_length,
K.image_dim_ordering(), mode='train')
data_gen_val = data_generators.get_anchor_gt(val_imgs, classes_count, cfg, nn.get_img_output_length,
K.image_dim_ordering(), mode='val')
if K.image_dim_ordering() == 'th':
input_shape_img = (3, None, None)
else:
input_shape_img = (None, None, 3)
img_input = Input(shape=input_shape_img)
roi_input = Input(shape=(None, 4))
# define the base network (resnet here, can be VGG, Inception, etc)
shared_layers = nn.nn_base(img_input, trainable=True)
定义RPN网络
# define the RPN, built on the base layers
num_anchors = len(cfg.anchor_box_scales) * len(cfg.anchor_box_ratios)
rpn = nn.rpn(shared_layers, num_anchors)
classifier = nn.classifier(shared_layers, roi_input, cfg.num_rois, nb_classes=len(classes_count), trainable=True)
model_rpn = Model(img_input, rpn[:2])
model_classifier = Model([img_input, roi_input], classifier)
# this is a model that holds both the RPN and the classifier, used to load/save weights for the models
model_all = Model([img_input, roi_input], rpn[:2] + classifier)
try:
print('loading weights from {}'.format(cfg.base_net_weights))
model_rpn.load_weights(cfg.model_path, by_name=True)
model_classifier.load_weights(cfg.model_path, by_name=True)
except Exception as e:
print(e)
print('Could not load pretrained model weights. Weights can be found in the keras application folder '
'https://github.com/fchollet/keras/tree/master/keras/applications')
optimizer = Adam(lr=1e-5)
optimizer_classifier = Adam(lr=1e-5)
model_rpn.compile(optimizer=optimizer,
loss=[losses_fn.rpn_loss_cls(num_anchors), losses_fn.rpn_loss_regr(num_anchors)])
model_classifier.compile(optimizer=optimizer_classifier,
loss=[losses_fn.class_loss_cls, losses_fn.class_loss_regr(len(classes_count) - 1)],
metrics={'dense_class_{}'.format(len(classes_count)): 'accuracy'})
model_all.compile(optimizer='sgd', loss='mae')
epoch_length = 1000
num_epochs = int(cfg.num_epochs)
iter_num = 0
losses = np.zeros((epoch_length, 5))
rpn_accuracy_rpn_monitor = []
rpn_accuracy_for_epoch = []
start_time = time.time()
best_loss = np.Inf
class_mapping_inv = {v: k for k, v in class_mapping.items()}
print('Starting training')
vis = True
for epoch_num in range(num_epochs):
progbar = generic_utils.Progbar(epoch_length)
print('Epoch {}/{}'.format(epoch_num + 1, num_epochs))
while True:
try:
if len(rpn_accuracy_rpn_monitor) == epoch_length and cfg.verbose:
mean_overlapping_bboxes = float(sum(rpn_accuracy_rpn_monitor)) / len(rpn_accuracy_rpn_monitor)
rpn_accuracy_rpn_monitor = []
print(
'Average number of overlapping bounding boxes from RPN = {} for {} previous iterations'.format(
mean_overlapping_bboxes, epoch_length))
if mean_overlapping_bboxes == 0:
print('RPN is not producing bounding boxes that overlap'
' the ground truth boxes. Check RPN settings or keep training.')
X, Y, img_data = next(data_gen_train)
loss_rpn = model_rpn.train_on_batch(X, Y)
P_rpn = model_rpn.predict_on_batch(X)
result = roi_helpers.rpn_to_roi(P_rpn[0], P_rpn[1], cfg, K.image_dim_ordering(), use_regr=True,
overlap_thresh=0.7,
max_boxes=300)
# note: calc_iou converts from (x1,y1,x2,y2) to (x,y,w,h) format
X2, Y1, Y2, IouS = roi_helpers.calc_iou(result, img_data, cfg, class_mapping)
if X2 is None:
rpn_accuracy_rpn_monitor.append(0)
rpn_accuracy_for_epoch.append(0)
continue
neg_samples = np.where(Y1[0, :, -1] == 1)
pos_samples = np.where(Y1[0, :, -1] == 0)
if len(neg_samples) > 0:
neg_samples = neg_samples[0]
else:
neg_samples = []
if len(pos_samples) > 0:
pos_samples = pos_samples[0]
else:
pos_samples = []
rpn_accuracy_rpn_monitor.append(len(pos_samples))
rpn_accuracy_for_epoch.append((len(pos_samples)))
if cfg.num_rois > 1:
if len(pos_samples) < cfg.num_rois // 2:
selected_pos_samples = pos_samples.tolist()
else:
selected_pos_samples = np.random.choice(pos_samples, cfg.num_rois // 2, replace=False).tolist()
try:
selected_neg_samples = np.random.choice(neg_samples, cfg.num_rois - len(selected_pos_samples),
replace=False).tolist()
except:
selected_neg_samples = np.random.choice(neg_samples, cfg.num_rois - len(selected_pos_samples),
replace=True).tolist()
sel_samples = selected_pos_samples + selected_neg_samples
else:
# in the extreme case where num_rois = 1, we pick a random pos or neg sample
selected_pos_samples = pos_samples.tolist()
selected_neg_samples = neg_samples.tolist()
if np.random.randint(0, 2):
sel_samples = random.choice(neg_samples)
else:
sel_samples = random.choice(pos_samples)
loss_class = model_classifier.train_on_batch([X, X2[:, sel_samples, :]],
[Y1[:, sel_samples, :], Y2[:, sel_samples, :]])
losses[iter_num, 0] = loss_rpn[1]
losses[iter_num, 1] = loss_rpn[2]
losses[iter_num, 2] = loss_class[1]
losses[iter_num, 3] = loss_class[2]
losses[iter_num, 4] = loss_class[3]
iter_num += 1
progbar.update(iter_num,
[('rpn_cls', np.mean(losses[:iter_num, 0])), ('rpn_regr', np.mean(losses[:iter_num, 1])),
('detector_cls', np.mean(losses[:iter_num, 2])),
('detector_regr', np.mean(losses[:iter_num, 3]))])
if iter_num == epoch_length:
loss_rpn_cls = np.mean(losses[:, 0])
loss_rpn_regr = np.mean(losses[:, 1])
loss_class_cls = np.mean(losses[:, 2])
loss_class_regr = np.mean(losses[:, 3])
class_acc = np.mean(losses[:, 4])
mean_overlapping_bboxes = float(sum(rpn_accuracy_for_epoch)) / len(rpn_accuracy_for_epoch)
rpn_accuracy_for_epoch = []
if cfg.verbose:
print('Mean number of bounding boxes from RPN overlapping ground truth boxes: {}'.format(
mean_overlapping_bboxes))
print('Classifier accuracy for bounding boxes from RPN: {}'.format(class_acc))
print('Loss RPN classifier: {}'.format(loss_rpn_cls))
print('Loss RPN regression: {}'.format(loss_rpn_regr))
print('Loss Detector classifier: {}'.format(loss_class_cls))
print('Loss Detector regression: {}'.format(loss_class_regr))
print('Elapsed time: {}'.format(time.time() - start_time))
curr_loss = loss_rpn_cls + loss_rpn_regr + loss_class_cls + loss_class_regr
iter_num = 0
start_time = time.time()
if curr_loss < best_loss:
if cfg.verbose:
print('Total loss decreased from {} to {}, saving weights'.format(best_loss, curr_loss))
best_loss = curr_loss
model_all.save_weights(cfg.model_path)
break
except Exception as e:
print('Exception: {}'.format(e))
# save model
model_all.save_weights(cfg.model_path)
continue
print('Training complete, exiting.')
if __name__ == '__main__':
train_kitti()
二.训练结果 (运行了6个小时,还没有运行完,在这里只展示一部分结果)
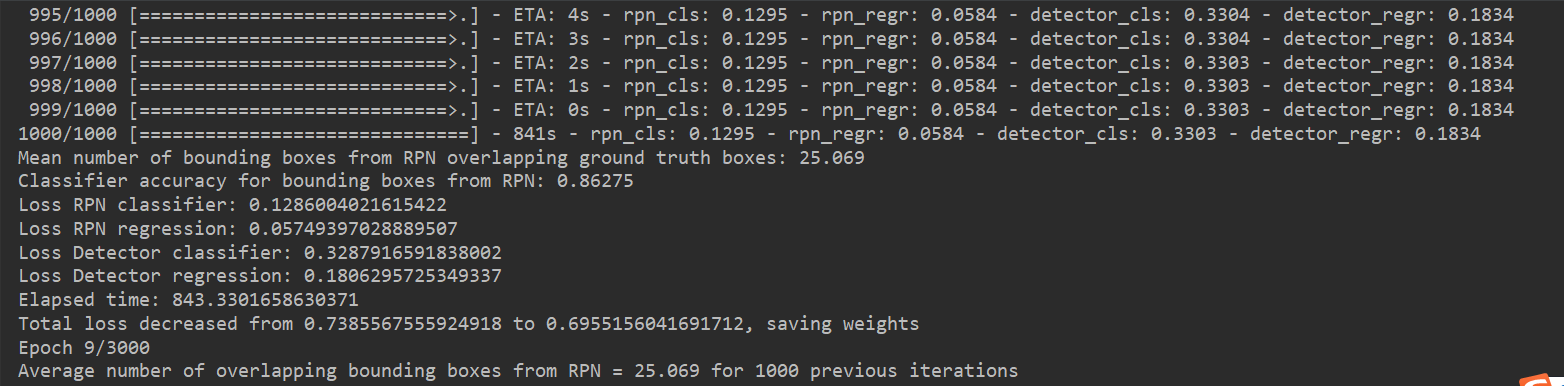
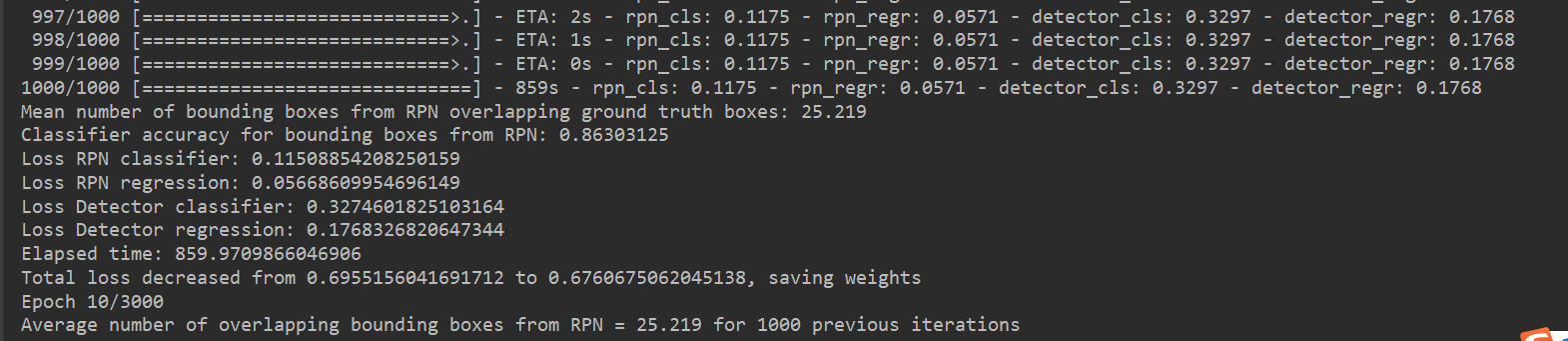
自己的电脑运行速度比较慢,程序只运行了一部分,但是能看出,每次程序结束后,真实检测框的精度在提高,损失在减少,说明该程序应该没有太大问题,后期会尝试修改里面的算法,试试能不能提高速度或准确度。
三.注意数据集的采集
在做实验时,发现一个很严重的问题:因为目前训练的图像,都是人物在图像的中央,导致只有人物在图片中间时,训练效果才比较好,人物在图片边缘,可能检测效果很差,故这周花了很多时间重新做数据集。
个人建议做数据集的步骤这样子,可以减少很多不必要的麻烦:
1.将视频按帧抽取图片
2.将图片处理为416*416(也可以为其他尺寸)
3.将图片随机的按比例分为训练集和验证集(我这里是8:2)
4.给分好的图片按顺序编号(这一步很重要,不然会导致后面训练的标签和图片无法对应)
5.给编号后的图片打标签
6.将xml格式的标签文件转换为需要的txt文件
7.检查txt文件是否和图片相对应
8.没问题就可以用自己的数据集啦~