这里的博客都是笔者初学时写下,一段时间后有其他的理解就再次回来修订
所以排版,文字,图片会有错乱,但重写一篇太过耗费时间,所以只能修修补补又重发
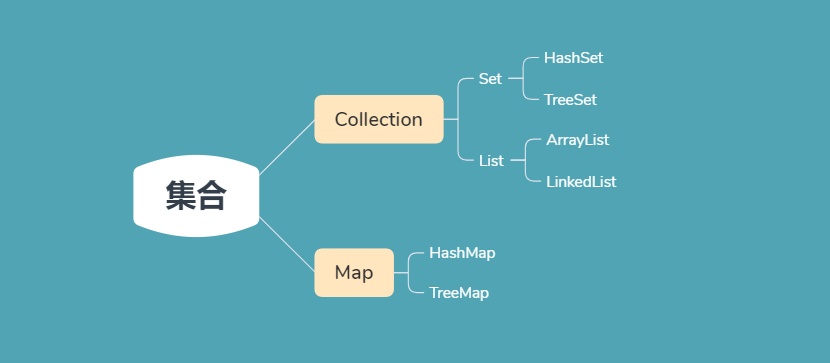
1. 什么是集合
- 集合是一个用来存放数据的容器(数组也是),但集合不同的是可以存放不同类型的对象,并且大小可变
- 其常用类型有Set,List,Map。这些常用的类型往上提取就有了Collection和Map接口
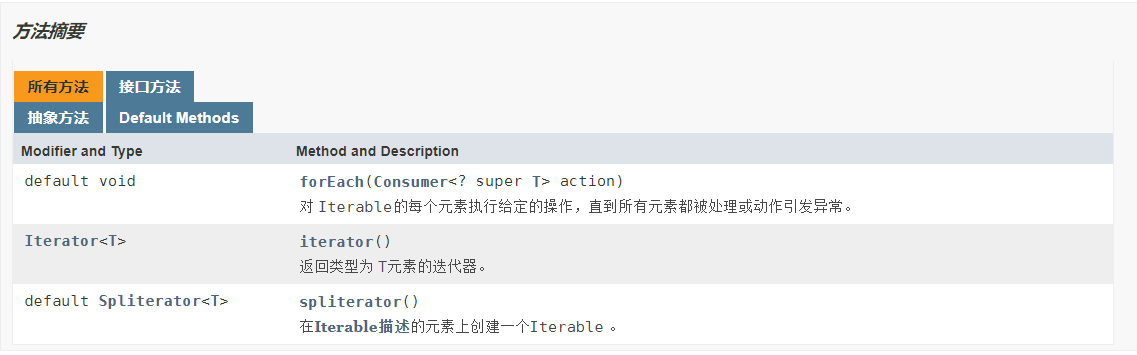
1.1 Collection接口的方法

add(E):添加一个对象
addAll(Collection<? extengds E>):添加指定集合里的全部对象
clear():清空集合
remove(Object):移除一个对象
removeAll(Collection<?>):移除集合里的全部对象
contains(Object):是否包含某个对象
containsAll(Collection<?>):是否包含某集合的全部对象
isEmpty():集合是否为空
size():集合对象的个数
retainAll(Collection<?>):交集,结果放在调用方法的集合
iterator():获取迭代器
1.2 Iterator迭代器
Collection接口继承Iterable接口,而Iterable接口有iterator()方法,该方法返回一个迭代器(用于遍历集合)
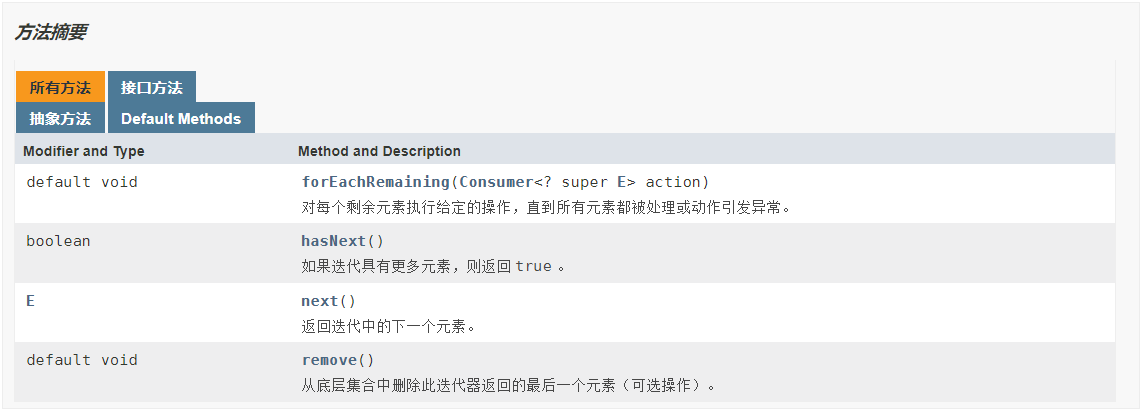
1.3 iterator也是一个接口
里面有四个方法,由于不同的集合有不同遍历方式,所以迭代器抽取成接口,让集合自己实现该接口
1.4 Map接口的方法

entrySet():获取包含键值对的Set集合,形式为Set<Entry<K,V>>
containsKey(Object):是否包含该Key
containsValue(Object):是否包含该Value
get(Object):根据Key获取Value
put(K,V):添加一个键值对
remove(Object):根据Key移除一个键值对
2. List集合
一. List——有序(指存取顺序一致),可重复
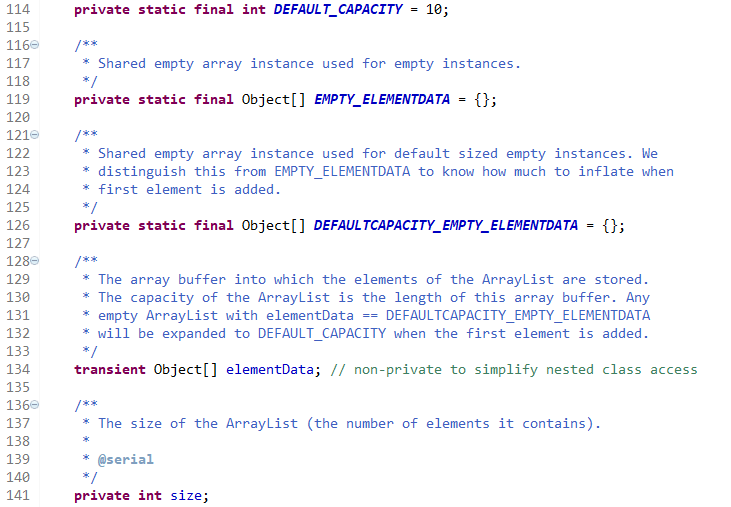
1. ArrayList (底层是Object数组,下标访问贼快)
* 定义的变量 * elementData存放元素 * size是集合的实际大小 * 集合的总大小用elementData.length数组长度来表示 * ArrayList 默认构造函数是一个空的数组
- add 是最常用的方法了,从尾部添加,我们来看看源码
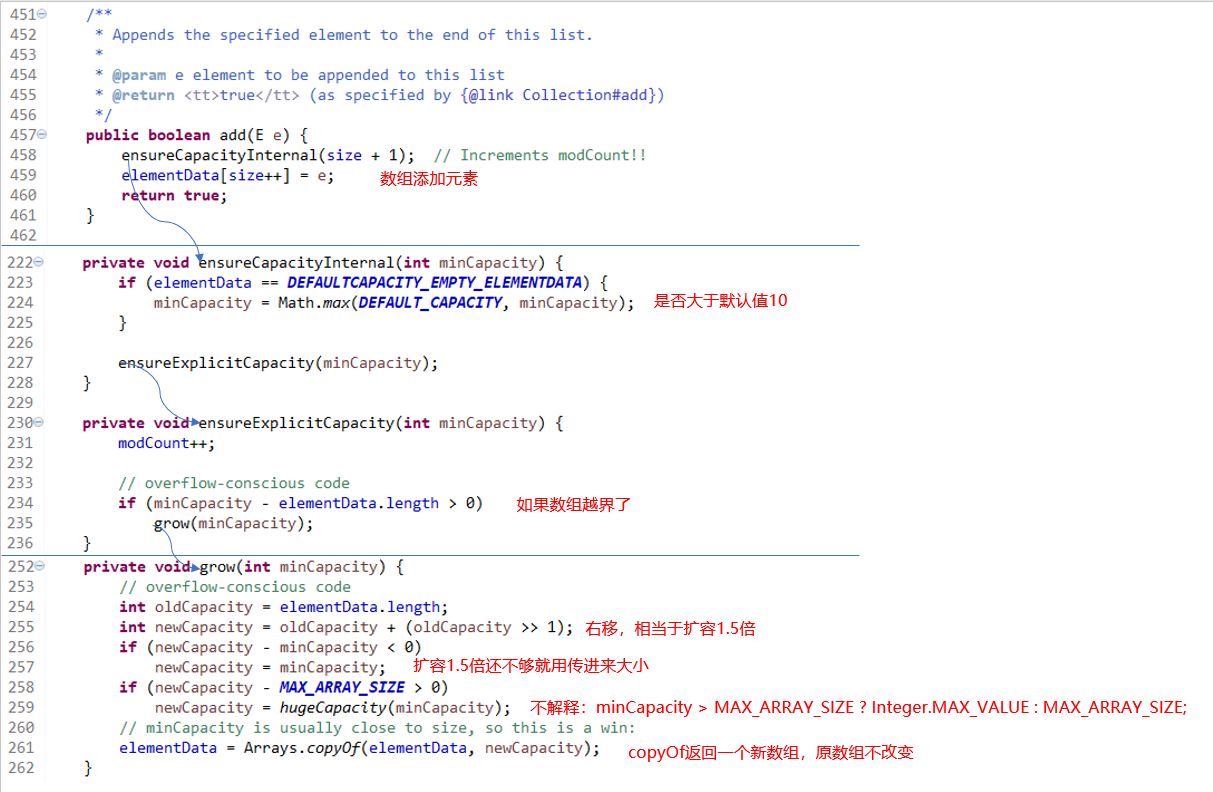
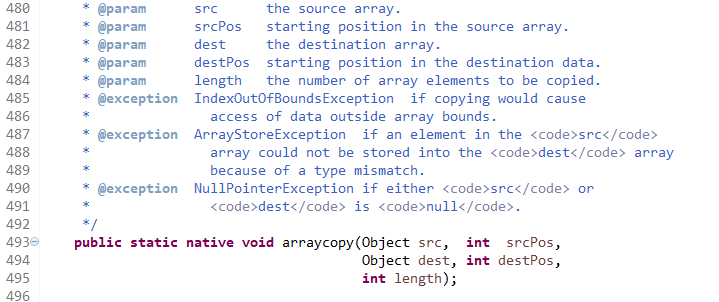
- 其中add( index,E )按下标插入元素稍有不同,其用System.arraycopy方法,由下图也可看出用
native修饰,底层用C/C++编写的且没有返回值,所以猜测是操作原数组进行扩容,埋坑以后回来看能不能理解这个

- get

- set

get 和set都比较简单,和普通操作数组一样,就是操作之前多了检查数组下标
* remove,也用到底层函数,不解释,不过要注意移动后,最后一个元素设置为空,取消引用,使之垃圾回收 * 删除元素时不会减少容量,若希望减少容量则可调用trimToSize(),是集合大小为实际大小

- toArray,也是复制一个新数组过去

2. vector(类似于ArrayList)
- 与ArrayList最大区别是线程安全,但我们一般都是用ArryaList代替它
- 二者有些其他微小区别,比如扩容时为2倍这些等,但不影响
- vector实现同步的方法是加上
synchronized修饰符,所以这里牺牲时间换取同步 - 如要ArrayList同步,可用
Collections.synchronizedList(new ArrayList()) - 还有其他线程安全的集合,后面几篇博客会说明,这里不再赘述
3. LinkedList (底层是双向链表)
- 定义的变量及节点
- first、last头尾节点
- Node 节点,内部维护值,前后节点的指向


**这里重点说明一下(与后面的迭代器有关),这个集合有关链表遍历的功能都会把当前节点之前的数据遍历一边,损耗性能**
- add国际惯例,看源码
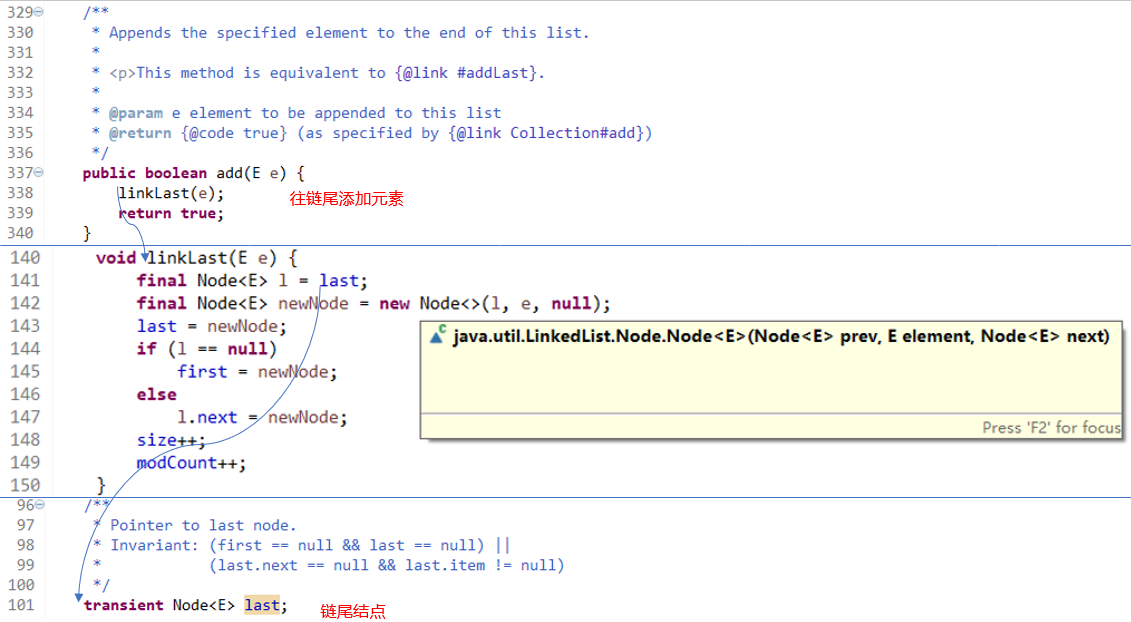
- remove

链表实现移除元素的图示

- get

- set

4. 二者遍历
- ArrayList底层是数组,用for、foreach(底层用Iterator)、Iterator访问速度差不多
- 而LinkedList 底层是双向链表,从get方法源码可知,需要遍历该位置前面的所有数据,所以得用Iterator、foreach
- 为什么用Iterator?因为会保存当前节点,不用从头遍历,不截图了直接上源码
//LinkedList 返回一个专属的迭代器
public Iterator iterator() {
return new LinkedListIterator();
}
//实现该接口
private class LinkedListIterator implements Iterator{
private Node currentNode = head;
private int nextIndex = 0;
public Object next() {
Object data = currentNode.getData();
currentNode = currentNode.getNext(); //从这里可以看出,会保存当前节点,不用从头遍历
nextIndex ++;
return data;
}
}
总结:
- ArrayList适用于随机查询次数多的情况
- LinkedList适用于随机增删
-
源码基于JDK1.8
-
脑图用XMind