在《机器学习---文本特征提取之词袋模型(Machine Learning Text Feature Extraction Bag of Words)》一文中,我们通过计算文本特征向量之间的欧氏距离,了解到各个文本之间的相似程度。当然,还有其他很多相似度度量方式,比如说余弦相似度。
在《皮尔逊相关系数与余弦相似度(Pearson Correlation Coefficient & Cosine Similarity)》一文中简要地介绍了余弦相似度。因此这里,我们比较一下欧氏距离和余弦相似度之间的区别。
首先来说一下欧氏距离(Euclidean Distance):
n维空间里两个向量X(x1,x2,…,xn)与Y(y1,y2,…,yn)之间的欧氏距离计算公式是: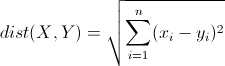
再来说一下余弦相似度(Cosine Similarity):
n维空间里两个向量x(x1,x2,…,xn)与y(y1,y2,…,yn)之间的余弦相似度计算公式是:
用向量形式表示为:
相同之处:
在机器学习中都可以用来计算相似程度。欧氏距离是最常见的距离度量,而余弦相似度则是最常见的相似度度量。很多其他的距离度量和相似度度量都是基于这两者的变形和衍生。
区别:
借助三维坐标系来看下欧氏距离和余弦相似度的区别。(下图摘自:https://blog.csdn.net/lin00jian/article/details/51209715)

从图上可以看出欧式距离衡量的是空间中各点之间的绝对距离,和点所在的位置坐标(即个体各维度的特征数值)直接相关,距离越小,两向量之间越相似;而余弦相似度衡量的是空间中两向量之间的夹角,体现的是方向上的差异,夹角越小(余弦相似度越大),两向量之间越相似。如果保持A点的位置不变,B点朝原方向延伸,那么这个时候余弦相似度cosθ是保持不变的,因为夹角不变,而A、B两点间的距离显然在发生改变,这就是欧氏距离和余弦相似度的不同之处。
适用场景:
欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,比如使用用户行为作为指标分析用户价值的相似情况(比较不同用户的消费能力),这属于价值度量;而余弦相似度对绝对数值不敏感,更多的用于使用用户对内容的评分来分析用户兴趣的相似程度(用户是否喜欢某商品),这属于定性度量。
需要注意的是,欧氏距离和余弦相似度都需要保证各维度处于相同的刻度级别(量纲),所以一般需要对数据先进行标准化处理,否则很可能会引起偏差。比如用户对内容评分,假设为5分制,对用户甲来说评分3分以上就是自己喜欢的,而对于用户乙,评分4分以上才是自己喜欢的,这样就无法很好地衡量两个用户评分之间的相似程度。如果将评分数值减去平均值,那么就可以很好地解决问题。此时,就相当于用皮尔逊相关系数来度量相似程度。