探索性数据分析(Exploratory Data Analysis,EDA)主要的工作是:对数据进行清洗,对数据进行描述(描述统计量,图表),查看数据的分布,比较数据之间的关系,培养对数据的直觉,对数据进行总结等。
探索性数据分析(EDA)与传统统计分析(Classical Analysis)的区别:
传统的统计分析方法通常是先假设样本服从某种分布,然后把数据套入假设模型再做分析。但由于多数数据并不能满足假设的分布,因此,传统统计分析结果常常不能让人满意。
探索性数据分析方法注重数据的真实分布,强调数据的可视化,使分析者能一目了然看出数据中隐含的规律,从而得到启发,以此帮助分析者找到适合数据的模型。“探索性”是指分析者对待解问题的理解会随着研究的深入不断变化。
应用传统统计分析方法的数据分析步骤:
- 提出问题 Problem => 准备数据 Data => 建模 Model => 分析 Analysis => 得出结论 Conclusions
应用探索性数据分析方法的数据分析步骤:
- 提出问题 Problem => 准备数据 Data => 分析 Analysis => 建模 Model => 得出结论 Conclusions
探索性数据分析通常有以下几个步骤:
A. 检查数据:
- 是否有缺失值?
- 是否有异常值?
- 是否有重复值?
- 样本是否均衡?
- 是否需要抽样?
- 变量是否需要转换?
- 是否需要增加新的特征?
注:数据类型分为数值型,类别型,文本型,时间序列等。这里主要指的是数值型(定量数据)和类别型(定性数据),其中数值型又可以分为连续型和离散型。
B. 使用描述统计量和图表对数据进行描述:
1)连续变量:
常见的描述统计量:平均值,中位数,众数,最小值,最大值,四分位数,标准差等
图表:频数分布表(需进行分箱操作),直方图,箱线图(查看分布情况)

2)无序型离散变量:
常见的描述统计量:各个变量出现的频数和占比
图表:频数分布表(绝对频数,相对频数,百分数频数),柱形图,条形图,茎叶图,饼图
3)有序型离散变量:
常见的描述统计量:各个变量出现的频数和占比
图表:频数分布表,堆积柱形图,堆积条形图(比较大小)
C. 考察变量之间的关系:
1)连续变量和连续变量(Continuous & Continuous):
对于连续变量与连续变量之间的关系,可以通过散点图进行查看。对于多个连续变量,可使用散点图矩阵,相关系数矩阵,热图。
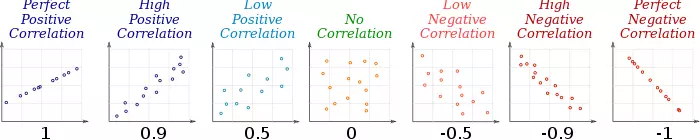
量化指标:皮尔逊相关系数(线性关系),互信息(非线性关系)
2)离散变量和离散变量(Discrete & Discrete):
对于离散变量与离散变量之间的关系,可以通过交叉分组表,复合柱形图,堆积柱形图,饼图进行查看。对于多个离散变量,可以使用网状图,通过各个要素之间是否有线条,以及线条的粗线来显示是否有关系以及关系的强弱。

量化指标:卡方独立性检验--->Cramer’s φ (Phi) or Cramer’s V
3)离散变量和连续变量(Discrete & Continuous):
对于离散变量和连续变量之间的关系,可以使用直方图,箱线图,小提琴图进行查看,将离散变量在图形中用不同的颜色显示,来直观地观察变量之间的关系。
量化指标:独立样本t检验中的t统计量和相应的p值(两个变量),单因素方差分析中的η²(三个变量及以上)
D. 其他
1)检查数据的正态性:直方图,箱线图,Q-Q图(Quantile-Quantile Plot )
直方图,箱线图:看图形是否对称
Q-Q图:比较数据的分位数与某个理论分布的分位数是否匹配
总结一下,如果要对数据集进行探索性分析:(以名字为data的数据集为例)
第一步,用pandas读取数据集,并显示前5行,看是否加载正确;
第二步,有必要时对列名重命名;
第三步,查看数据整体情况(行列数data.shape,数据类型data.dtypes,或者用data.info()同时查看这两项,用data.describe()查看连续变量的描述统计量);
第四步,处理缺失值,异常值,重复值问题(各列分别有多少缺失值data.apply(lambda x: sum(x.isnull()),axis=0),各行分别有多少缺失值data.apply(lambda x: sum(x.isnull()),axis=1),总共有多少行有缺失值
len(data.apply(lambda x: sum(x.isnull()),axis=1).nonzero()[0]),删除重复值data.drop_duplicates());
第五步,有必要时转换数据类型;
第六步,看是否需要添加新的特征;
第七步,确定分析思路,用思维导图画出来;
第八步,按照分析思路进行分析并画出图形;
第九步,总结分析结果;
附:
图形的选择:描述趋势使用折线图,描述数量使用柱状图(且必须从 0 开始),描述关系使用散点图,描述比例使用饼状图。
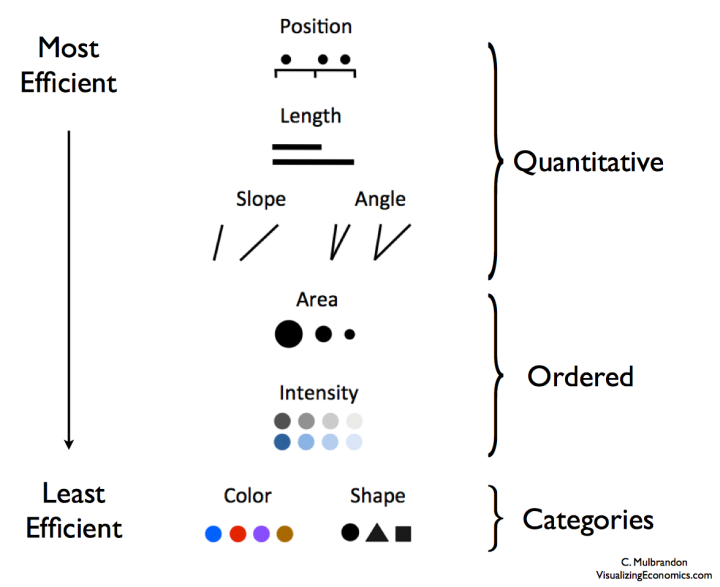
科学家经过 30 年的研究,发现人对位置、长度和角度的感知最敏锐,可以用来表示数量,其次是面积和密度,可表示顺序,对于颜色和形状的感知是最不精确的,只可用来区分类别。