推断统计(Inferential Statistics):利用样本信息对总体进行估计和假设检验。
总体(population):在一个特定研究中所有感兴趣的个体组成的集合。
样本(sample):总体的一个子集。
样本统计量(sample statistics):样本数据的计算度量。
总体参数(population parameters):总体数据的计算度量。
普查(census):搜集总体全部数据的调查过程。
抽样调查(sampling survey):搜集样本数据的调查过程。
点估计量(point estimator):用来估计总体参数的样本统计量。
标准误差(standard error):点估计量的标准差。
点估计(point estimate):样本统计量的值。
边际误差(margin of error):边际误差将参数(如均值或比值)估计中的随机抽样误差量进行量化。当置信区间对称时,边际误差是置信区间的一半。
区间估计(interval estimate):在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常由点估计加减边际误差得到。当我们用样本来对总体进行估计时,如果只是一个估计值的话,那就称为点估计。但是每次随机抽样计算出的结果都不一样,因此点估计不一定准,这时用一个区间来对总体进行估计会更准确。
总体均值的区间估计:1,σ已知: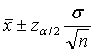 ;2,σ未知:
;2,σ未知: (用s估计σ,此时总体均值的估计值服从t分布,
(用s估计σ,此时总体均值的估计值服从t分布,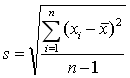 )。
)。
置信度(confidence level):置信区间有xx%的可能性包含总体参数。xx%即为置信度,通常设置为90%,95%,99%。置信度越高,置信区间也就越大。
置信区间(confidence interval):包含总体参数的随机区间,区间估计的另一种叫法。
假设检验(hypothesis test):https://www.cnblogs.com/HuZihu/p/9692828.html