1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
算法层面:
①L1正则,通过增大正则项导致更多参数为0,参数系数化降低模型复杂度,从而抵抗过拟合。
②L2正则,通过使得参数都趋于0,变得很小,降低模型的抖动,从而抵抗过拟合。
数据层面:
①增加样本数量
②通过特征选择,剔除一些不重要的特征,从而降低模型复杂度
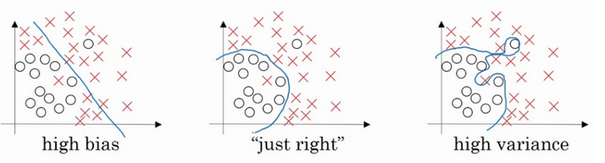
过拟合表现在训练数据上的误差非常小,而在测试数据上误差反而增大。其原因一般是模型过于复杂,过分得去拟合数据的噪声和outliers.
正则化则是对模型参数添加先验,使得模型复杂度较小,对于噪声以及outliers的输入扰动相对较小。如果我们的参数值对应一个较小值的话(参数值比较小),那么往往我们会得到一个形式更简单的假设。
实际上,这些参数的值越小,通常对应于越光滑的函数,也就是更加简单的函数。因此 就不易发生过拟合的问题。
2.用logiftic回归来进行实践操作,数据不限。
使用逻辑回归根据泰坦尼克号上乘船人员的船舱等级(分三等)、性别、年龄进行预测该乘客是否生还。
先导入需要使用的库
import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report import numpy as np
读取泰坦尼克号生还人数数据集,对数据集进行初步处理
data=pd.read_csv("./data/titanic_data.csv") data.drop("PassengerId",axis=1,inplace=True) #删除乘客id列 data.loc[data['Sex']=='male','Sex']=1 #将非数值型数据数值化—使用数值1代替男性 data.loc[data['Sex']=='female','Sex']=0 #将非数值型数据数值化—用数值0代替女性 data.fillna(data["Age"].mean(),inplace=True) #因年龄列有缺失值 故使用该列平均值填充空值
选取训练数据和目标数据并划分训练集和测试集(8:2划分)
x=data.iloc[:,1:] #从第一列开始,所有列都为训练数据 y=data.iloc[:,0] #第0列为目标数据,即是否生还 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
构建逻辑回归模型,训练模型
model = LogisticRegression()
model.fit(x_train,y_train)
使用模型进行数据预测及对模型进行评估
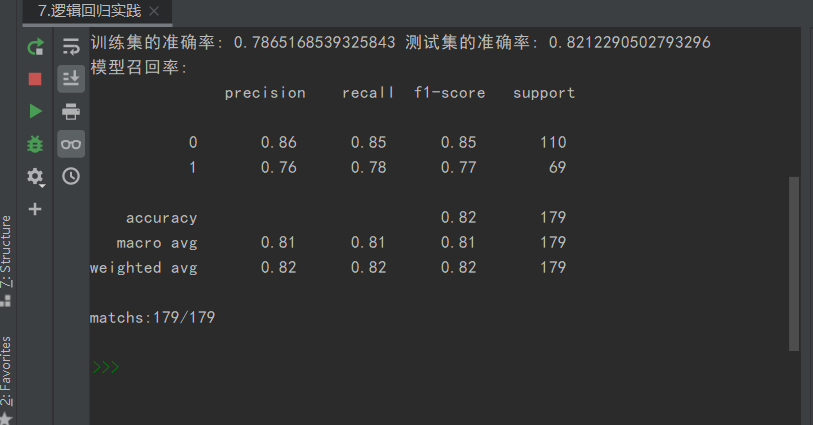
y_pre=model.predict(x_test) train_score = model.score(x_train, y_train) #训练集的正确率 test_score = model.score(x_test, y_test) #测试集的正确率 print("训练集的准确率:",train_score, "测试集的准确率:",test_score) print('模型召回率: ', classification_report(y_test,y_pre)) print('matchs:{0}/{1}'.format(np.equal(y_pre,y_test).shape[0], y_test.shape[0])) # 预测正确个数
预测结果: