编程实现:要传输一些数据(比如英文单词),设计一个利用哈夫曼算法的编码系统,为这些单词编码,并在接收端进行译码。基本要求:
(1)将需要传输的数据存放在数据文件data.txt 中。
(2)读入数据文件并为其编码,将编码后的内容存入文件code.txt中。
(3)读入code.txt,译码。并将译码后的内容输出在屏幕上。
事先准备好date.txt文件
PS:之前代码创建哈夫曼编码时有点个错误,改正了
代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<stdbool.h>
//N为汉夫曼树叶子节点数
#define N 256
//M为哈夫曼树所含节点总数
#define M 2 * N - 1
//定义极大值
#define INFINITE 0x3f3f3f3f
//date文件中的所含字符种类,本程序可以包括整个ASCII码
#define CHAR_KINDS 256
typedef struct{
int weight;
int parent;
int LChild;
int RChild;
//用来存储汉夫曼树叶子节点的所存的信息,方便解码
int info;
}HTNode, HuffmanTree[M + 1];
//哈夫曼编码
typedef char *HuffmanCode[N + 1];
//选出两个权值最小的子树
void Select(HuffmanTree *ht, int m, int *s1, int *s2){
int minWeight = INFINITE;
int i;
for(i = 1; i <= m; i++){
if((*ht)[i].weight < minWeight && (*ht)[i].parent == 0){
minWeight = (*ht)[i].weight;
*s1 = i;
}
}
minWeight = INFINITE;
for(i = 1; i <= m ;i++){
if((*ht)[i].weight < minWeight && (*ht)[i].parent == 0 && i != *s1){
minWeight = (*ht)[i].weight;
*s2 = i;
}
}
}
//创建汉夫曼树
void CrtHuffman(HuffmanTree *ht, int w[], int tw[], int n){
int i, j = 0;
//寻找非零的权值,并且对哈夫曼树叶子节点(子树)进行初始化
for(i = 1; i <= n; i++){
(*ht)[i].weight = w[tw[i - 1]];
(*ht)[i].parent = 0;
(*ht)[i].LChild = 0;
(*ht)[i].RChild = 0;
(*ht)[i].info = tw[i - 1];
}
int m = n * 2 - 1;
//对非叶子节点进行初始化
for(i = n + 1; i <= m; i++){
(*ht)[i].weight = 0;
(*ht)[i].parent = 0;
(*ht)[i].LChild = 0;
(*ht)[i].RChild = 0;
(*ht)[i].info = -1;
}
//构造哈夫曼树
for(i = n + 1; i <= m; i++){
int s1, s2;
//选择连个权值最小的子树,创建新子树
Select(ht, i - 1, &s1, &s2);
//新子树的权值等于选出来两个权值之和
(*ht)[i].weight = (*ht)[s1].weight + (*ht)[s2].weight;
//s1子树和s2子树的双亲变成i
(*ht)[s1].parent = i;
(*ht)[s2].parent = i;
//i子树的左右孩子分别为s1和s2
(*ht)[i].LChild = s1;
(*ht)[i].RChild = s2;
}
}
//创建哈夫曼编码
void CrtHuffmanCode(HuffmanTree *ht, HuffmanCode *hc, int w[], int tw[], int n){
char *cd;
cd = (char *)malloc(n * sizeof(char)));
cd[n - 1] = '�';
int i, start, c, p;
//对哈夫曼树的每个叶子节点进行编码
for(i = 1; i <= n; i++){
start = n - 1;
c = i;
p = (*ht)[i].parent;
//每个叶子节点的编码都是从叶子节点往树根推,直到此节点双亲为0,即到达根节点
while(p != 0){
--start;
//若为左分支,编码为0;右分支编码为1
if((*ht)[p].LChild == c) cd[start] = '0';
else cd[start] = '1';
c = p;
p = (*ht)[p].parent;
}
(*hc)[tw[i - 1]] = (char *)malloc((n - start) * sizeof(char));
strcpy((*hc)[tw[i - 1]], &cd[start]);
}
free(cd);
}
//统计权值
void CountCharWeight(FILE **fp, int w[]){
if((*fp = fopen("date.txt", "r+")) == NULL){
printf("不能打开该文件
");
exit(0);
}
char ch;
while(!feof(*fp)){
ch = fgetc(*fp);
if(ch == -1) break;
w[(int)ch]++;
}
}
//为每个字符进行编码,并且输出到date.txt文件中
void Coding(FILE **sfp, FILE **cdfp, HuffmanCode *hc){
if((*cdfp = fopen("code.txt", "w+")) == NULL){
printf("不能打开该文件
");
exit(0);
}
//将源文本文件的文件标记指向文件开头
rewind(*sfp);
char ch;
while(!feof(*sfp)){
ch = fgetc(*sfp);
//由于feof(*sfp)函数只能判断当前位置是不是文件结束位置,编码会多一个
//ch = fgetc(*sfp)会多往后走一个,则人为判断一下即可,即feof(*sfp)返回值为-1
if(ch == -1) break;
fputs((*hc)[(int)ch], *cdfp);
}
fclose(*sfp);
}
//查找哈夫曼树的根
int FindRoot(HuffmanTree *ht, int n){
int i;
int m = 2 * n - 1;
for(i = 1; i <= m; i++){
if((*ht)[i].weight != 0 && (*ht)[i].parent == 0 && (*ht)[i].LChild != 0 && (*ht)[i].RChild != 0){
return i;
}
}
return 0;
}
//解码
void Decoding(HuffmanTree *ht, FILE **cdfp, int w[], int n){
rewind(*cdfp);
char ch;
int root, son;
//如果找到根便解码
if(root = FindRoot(ht, n)){
son = root;
//利用哈夫曼树进行解码
while(!feof(*cdfp)){
ch = fgetc(*cdfp);
if(ch == -1) break;
if(ch == '0') son = (*ht)[son].LChild;
else son = (*ht)[son].RChild;
//如果到达叶子节点,便找到哈夫曼编码对应的信息,接着继续从根节点进行解码
if((*ht)[son].LChild == 0 && (*ht)[son].RChild == 0){
printf("%c", (char)(*ht)[son].info);
son = root;
}
}
}
fclose(*cdfp);
}
//统计不为零权值的个数,并且记录其下标到tw[]
int GetWeightId(int tw[], int w[]){
int i, n = 0;
for(i = 0; i < CHAR_KINDS; i++){
if(w[i] > 0){
tw[n++] = i;
}
}
return n;
}
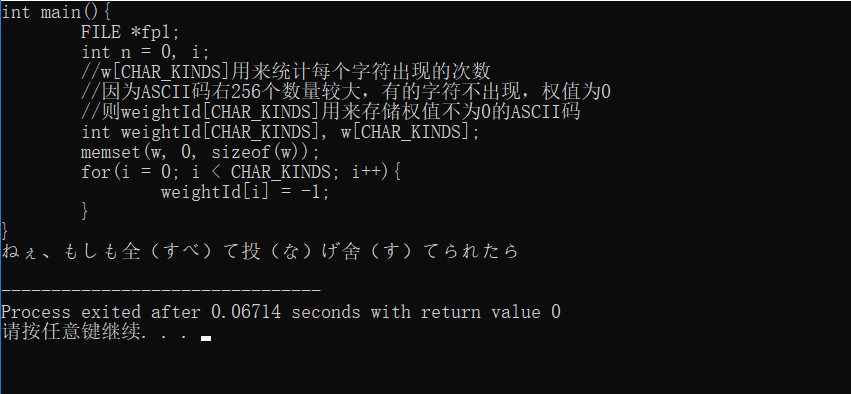
int main(){
FILE *fp1;
int n = 0, i;
//w[CHAR_KINDS]用来统计每个字符出现的次数
//因为ASCII码右256个数量较大,有的字符不出现,权值为0
//则weightId[CHAR_KINDS]用来存储权值不为0的ASCII码
int weightId[CHAR_KINDS], w[CHAR_KINDS];
memset(w, 0, sizeof(w));
for(i = 0; i < CHAR_KINDS; i++){
weightId[i] = -1;
}
CountCharWeight(&fp1, w);
HuffmanTree huffmantree;
n = GetWeightId(weightId, w);
HuffmanCode hc;
CrtHuffman(&huffmantree, w, weightId, n);
CrtHuffmanCode(&huffmantree, &hc, w, weightId, n);
FILE *codefp;
Coding(&fp1, &codefp, &hc);
Decoding(&huffmantree, &codefp, w, n);
printf("
");
return 0;
}
运行结果:
改进,把从文件读取字符换成int型变量,便可以对汉字和日文进行编码解码:
代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
//N为汉夫曼树叶子节点数
#define N 256
//M为哈夫曼树所含节点总数
#define M 2 * N - 1
//定义极大值
#define INFINITE 0x3f3f3f3f
//date文件中的所含字符种类,本程序可以包括整个ASCII码
#define CHAR_KINDS 256
typedef struct{
int weight;
int parent;
int LChild;
int RChild;
//用来存储汉夫曼树叶子节点的所存的信息,方便解码
int info;
}HTNode, HuffmanTree[M + 1];
//哈夫曼编码
typedef char *HuffmanCode[N + 1];
//选出两个权值最小的子树
void Select(HuffmanTree *ht, int m, int *s1, int *s2){
int minWeight = INFINITE;
int i;
for(i = 1; i <= m; i++){
if((*ht)[i].weight < minWeight && (*ht)[i].parent == 0){
minWeight = (*ht)[i].weight;
*s1 = i;
}
}
minWeight = INFINITE;
for(i = 1; i <= m ;i++){
if((*ht)[i].weight < minWeight && (*ht)[i].parent == 0 && i != *s1){
minWeight = (*ht)[i].weight;
*s2 = i;
}
}
}
//创建汉夫曼树
void CrtHuffman(HuffmanTree *ht, int w[], int tw[], int n){
int i, j = 0;
//寻找非零的权值,并且对哈夫曼树叶子节点(子树)进行初始化
for(i = 1; i <= n; i++){
(*ht)[i].weight = w[tw[i - 1]];
(*ht)[i].parent = 0;
(*ht)[i].LChild = 0;
(*ht)[i].RChild = 0;
(*ht)[i].info = tw[i - 1];
}
int m = n * 2 - 1;
//对非叶子节点进行初始化
for(i = n + 1; i <= m; i++){
(*ht)[i].weight = 0;
(*ht)[i].parent = 0;
(*ht)[i].LChild = 0;
(*ht)[i].RChild = 0;
(*ht)[i].info = -1;
}
//构造哈夫曼树
for(i = n + 1; i <= m; i++){
int s1, s2;
//选择连个权值最小的子树,创建新子树
Select(ht, i - 1, &s1, &s2);
//新子树的权值等于选出来两个权值之和
(*ht)[i].weight = (*ht)[s1].weight + (*ht)[s2].weight;
//s1子树和s2子树的双亲变成i
(*ht)[s1].parent = i;
(*ht)[s2].parent = i;
//i子树的左右孩子分别为s1和s2
(*ht)[i].LChild = s1;
(*ht)[i].RChild = s2;
}
}
//创建哈夫曼编码
void CrtHuffmanCode(HuffmanTree *ht, HuffmanCode *hc, int w[], int tw[], int n){
char *cd;
cd = (char *)malloc(n * sizeof(char));
cd[n - 1] = '�';
int i, start, c, p;
//对哈夫曼树的每个叶子节点进行编码
for(i = 1; i <= n; i++){
start = n - 1;
c = i;
p = (*ht)[i].parent;
//每个叶子节点的编码都是从叶子节点往树根推,直到此节点双亲为0,即到达根节点
while(p != 0){
--start;
//若为左分支,编码为0;右分支编码为1
if((*ht)[p].LChild == c) cd[start] = '0';
else cd[start] = '1';
c = p;
p = (*ht)[p].parent;
}
(*hc)[tw[i - 1]] = (char *)malloc((n - start) * sizeof(char));
strcpy((*hc)[tw[i - 1]], &cd[start]);
}
free(cd);
}
//统计权值
void CountCharWeight(FILE **fp, int w[]){
if((*fp = fopen("data.txt", "r+")) == NULL){
printf("不能打开该文件
");
exit(0);
}
int ch;
while(!feof(*fp)){
ch = fgetc(*fp);
if(ch == -1) break;
w[ch]++;
}
}
//为每个字符进行编码,并且输出到date.txt文件中
void Coding(FILE **sfp, FILE **cdfp, HuffmanCode *hc){
if((*cdfp = fopen("code.txt", "w+")) == NULL){
printf("不能打开该文件
");
exit(0);
}
//将源文本文件的文件标记指向文件开头
rewind(*sfp);
int ch;
while(!feof(*sfp)){
ch = fgetc(*sfp);
//由于feof(*sfp)函数只能判断当前位置是不是文件结束位置,编码会多一个
// = fgetc(*sfp)会多往后走一个,则人为判断一下即可,即feof(*sfp)返回值为-1
if(ch == -1) break;
fputs((*hc)[(int)ch], *cdfp);
}
fclose(*sfp);
}
//查找哈夫曼树的根
int FindRoot(HuffmanTree *ht, int n){
int i;
int m = 2 * n - 1;
for(i = 1; i <= m; i++){
if((*ht)[i].weight != 0 && (*ht)[i].parent == 0 && (*ht)[i].LChild != 0 && (*ht)[i].RChild != 0){
return i;
}
}
return 0;
}
//解码
void Decoding(HuffmanTree *ht, FILE **cdfp, int w[], int n){
rewind(*cdfp);
char ch;
int root, son;
//如果找到根便解码
if(root = FindRoot(ht, n)){
son = root;
//利用哈夫曼树进行解码
while(!feof(*cdfp)){
ch = fgetc(*cdfp);
if(ch == -1) break;
if(ch == '0') son = (*ht)[son].LChild;
else son = (*ht)[son].RChild;
//如果到达叶子节点,便找到哈夫曼编码对应的信息,接着继续从根节点进行解码
if((*ht)[son].LChild == 0 && (*ht)[son].RChild == 0){
printf("%c", (*ht)[son].info);
son = root;
}
}
}
fclose(*cdfp);
}
//统计不为零权值的个数,并且记录其下标到tw[]
int GetWeightId(int tw[], int w[]){
int i, n = 0;
for(i = 0; i < CHAR_KINDS; i++){
if(w[i] > 0){
tw[n++] = i;
}
}
return n;
}
int main(){
FILE *fp1;
int n = 0, i;
//w[CHAR_KINDS]用来统计每个字符出现的次数
//因为ASCII码右256个数量较大,有的字符不出现,权值为0
//则weightId[CHAR_KINDS]用来存储权值不为0的ASCII码
int weightId[CHAR_KINDS], w[CHAR_KINDS];
memset(w, 0, sizeof(w));
for(i = 0; i < CHAR_KINDS; i++){
weightId[i] = -1;
}
CountCharWeight(&fp1, w);
HuffmanTree huffmantree;
n = GetWeightId(weightId, w);
printf("%d
",n);
HuffmanCode hc;
CrtHuffman(&huffmantree, w, weightId, n);
CrtHuffmanCode(&huffmantree, &hc, w, weightId, n);
FILE *codefp;
Coding(&fp1, &codefp, &hc);
Decoding(&huffmantree, &codefp, w, n);
printf("
");
return 0;
}
运行结果如下: