一. 安装virtualBox
虚拟机需要安装两台. 一个是master, 一个是node. 这两台虚拟机的名字一定不能相同. 因此, master服务器的名字叫做ubantu, node的名字叫ubantu-node
1. 安装ubantu系统
2. 设置
-
-
设置桥接模式
-
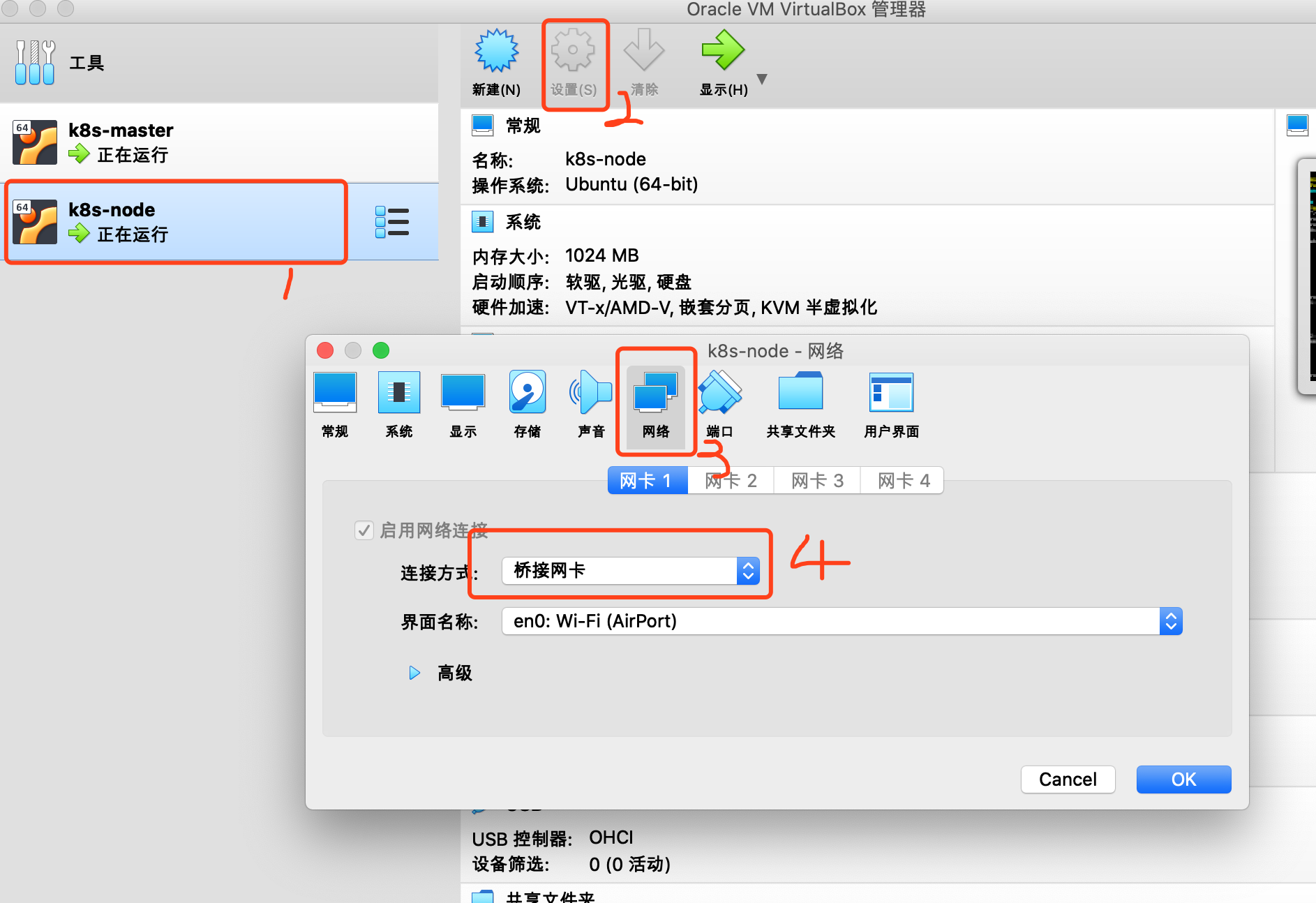
-
-
设置root密码
-
sudo passwd root
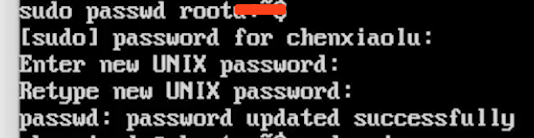
先输入用户密码, 然后在输入root密码
-
-
设置 root ssh 访问
-
网络不通, 重启电脑, 以root用户登录, 密码:123456
ping www.baidu.com 能ping通
设置ssh
更新apt-get apt-get update 安装ssh apt-get install ssh 设置ssh vim /etc/ssh/sshd_config 将PermitRootLogin 的值设置为yes
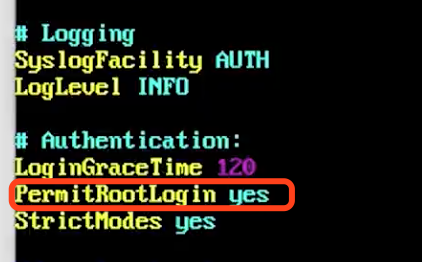
重启ssh
systemctl restart ssh
查看ip地址: ip a
在mac的terminal通过ssh连接到服务: ssh root@192.168.1.103, 输入用户密码. 连接成功
-
-
关闭防火墙
ufw disable

-
二. 在虚拟机上安装docker
1. 登录服务器, 查看ip
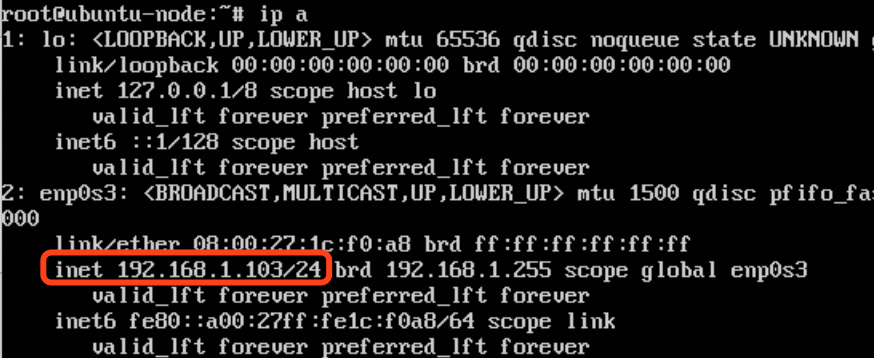
2. 在mac终端ssh登录
ssh root@192.168.1.103
密码: 123456
3. 安装docker
apt-get update apt-get install -y docker.io
检验docker是否安装成功. 命令行输入docker检查
4. docker的配置
- 阿里云加速器配置 : https://cr.console.aliyun.com/
- 登录https://cr.console.aliyun.com/, 并找到镜像加速器, 参考教程,进行配置
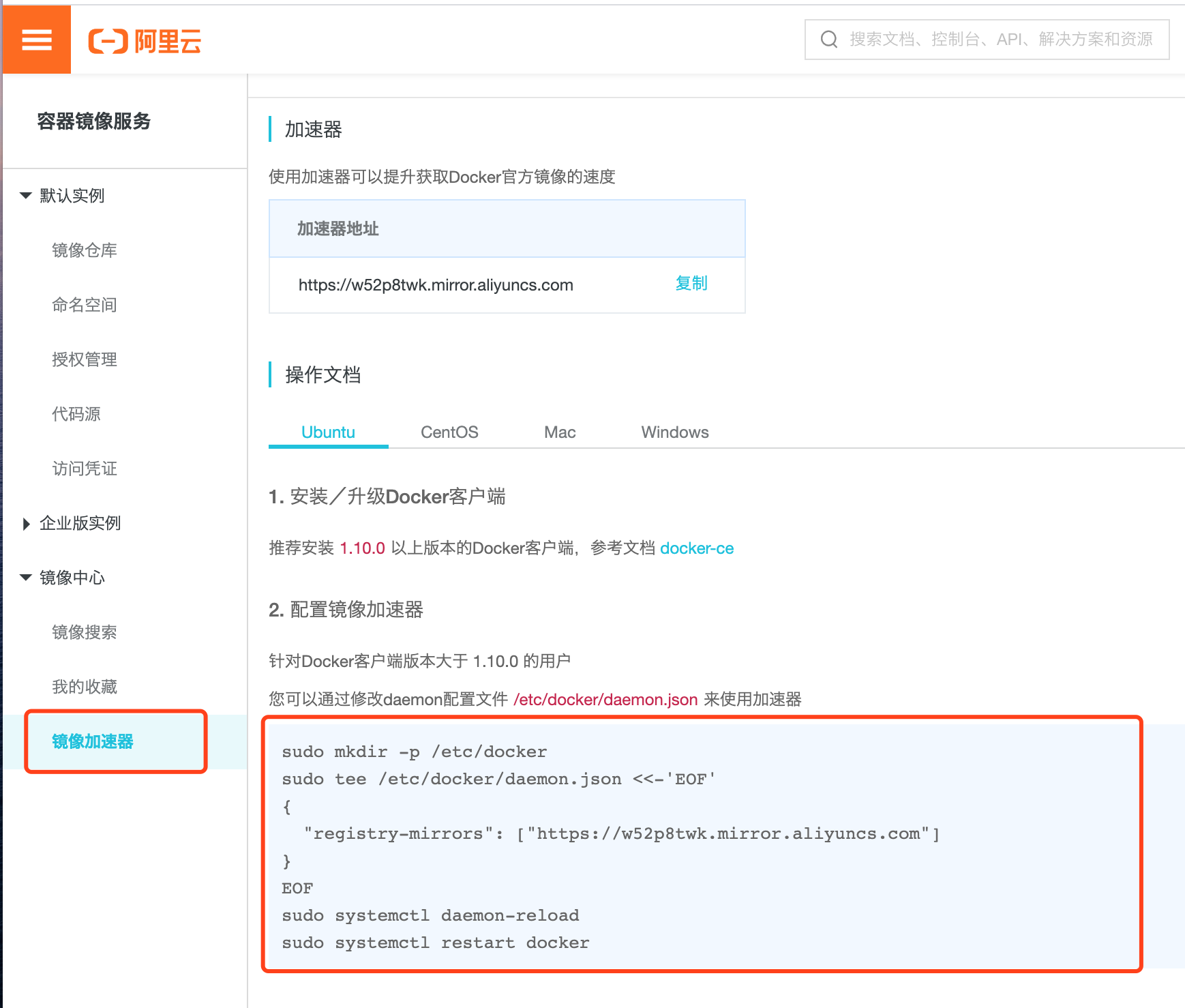
第一步: 创建文件夹, 有就不用创建了 sudo mkdir -p /etc/docker 第二步:添加文件, 并将大括号的内容添加到文件里 sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://w52p8twk.mirror.aliyuncs.com"] } EOF 第三步: 重启docker sudo systemctl daemon-reload sudo systemctl restart docker
三. 在docker上安装mysql
第一步: 在master节点上, 安装myqsl镜像
docker pull mysql:5.6
第二步: 启动mysql容器
docker run -p 3306:3306 --name mymysql -v /home/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.6
-e MYSQL_ROOT_PASSWORD: -e是用来设置环境变量的. 这里设置的是mysql的root用户的密码
-v : 挂载卷
![]()
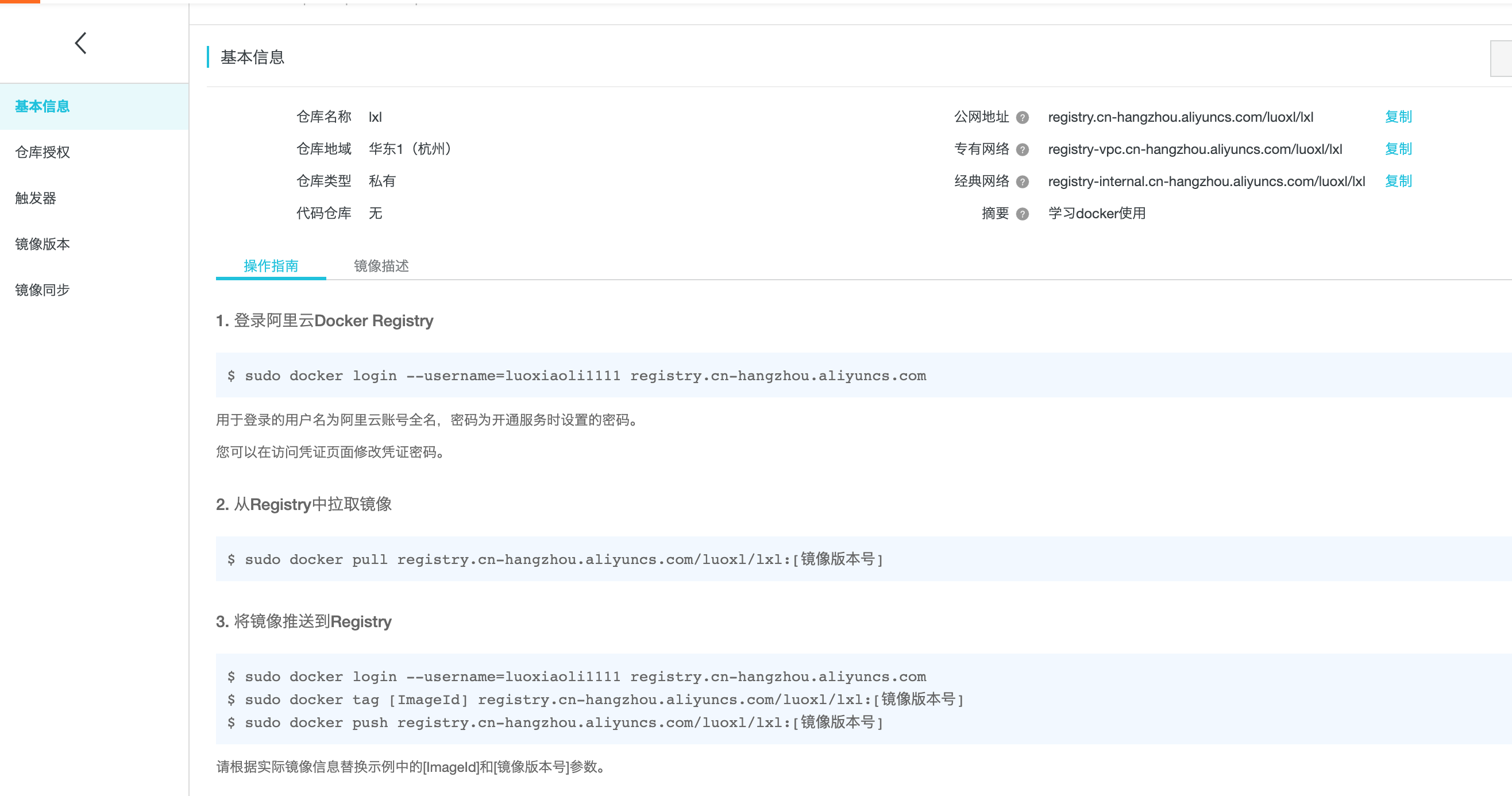
第三步: 阿里云仓库的登录
1. 创建一个自己的镜像仓库

2. 点击管理按钮, 可以查看登录阿里云镜像仓库的操作方法
四.安装k8s
科学&上网: 安装k8s,需要翻墙, 其实一直不明白,啥事科学&上网,原来科学&上网的含义就是翻墙. 因为安装k8s的软件, 需要翻墙下载一些东西.
前提:
1. 两台主机上都安装了docker
2. 两台主机上都要安装kubeadm, kubelet, 和kubectl
3. 两台主机都要禁用虚拟内存
第一步:禁用虚拟内存并永久关闭
swapoff -a && sed -i '/ swap / s/^(.*)$/#1/g' /etc/fstab
为什么禁用虚拟内存呢?
原因是kubeadm安装k8s的时候, 它在init的时候回去检测是否有虚拟分区有没有关闭, 如果你开启了虚拟内存,我们的容器, pod就有可能放在虚拟内存中, 这样会大大降低工作效率
如果是安装的linux操作系统, 需要关闭SELinux
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
第二步: 安装kubeadm, kubelet, 和kubectl
安装apt-transport-https 和 curl
apt-get update && apt-get install -y apt-transport-https curl
第三步: 如何设置代理
下载k8s的软件, 需要设置代理, 我使用的是v2&ray.
1. copy 代理参数
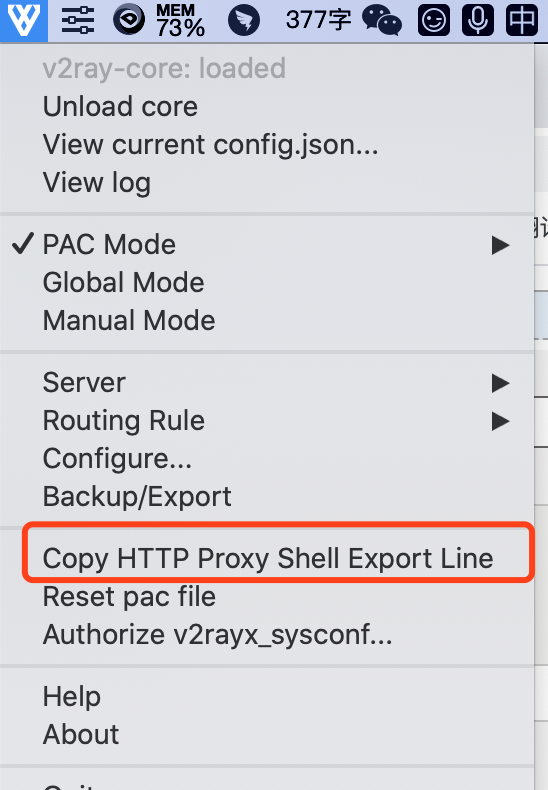
然后粘贴出来: export http_proxy="http://127.0.0.1:8001"; export HTTP_PROXY="http://127.0.0.1:8001"; export https_proxy="http://127.0.0.1:8001"; export HTTPS_PROXY="http://127.0.0.1:8001"
2. 查看mac本机的ip
ifconfig | grep 182.168.1
![]()
网关是101
3. 给虚拟机设置代理
export http_proxy="http://192.168.1.101:8001"; export HTTP_PROXY="http://192.168.1.101:8001"; export https_proxy="http://192.168.1.101:8001"; export HTTPS_PROXY="http://192.168.1.101:8001"

4. 检查代理是否设置成功
echo $http_proxy
![]()
第四步: 把官方的下载源, 加入到apt-get中
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF>/etc/apt/sources.list.d/kubernates.list
deb http://apt.kubernates.io/kubernates-xenial main
EOF
拆解步骤一:
我直接运行 curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - 报错,
分两步执行:
1. 在浏览器输入网址下载 apt-key.gpg :
curl -O https://packages.cloud.google.com/apt/doc/apt-key.gpg
2. 将文件导入到虚拟机, 使用apt-key命令加载获取到的文件
sudo apt-key add apt-key.gpg(成功后回显OK)

拆解步骤二:
将源加到文件当中
cat <<EOF >/etc/apt/sources.list.d/kubernates.list
deb http://apt.kubernates.io/ kubernates-xenial main
EOF
实际上是将一行文字放到了Kubernetes.list文件中.
我们查看一下这个文件
vi /etc/apt/sources.list.d/kubernates.list
我们看到已经有了
![]()
第五步: 下载kubelet kubeadm kubectl
apt-get update && apt-get install -y kubelet kubeadm kebuctl
-------------华丽的分割线--开始------------
在这里重点备注::::::重点:::::重点:::::重点::::::
科学&上网搞死人------整了好多天, 每次都死在这里.
可以使用国内镜像. 重要的事情说三遍
可以使用国内镜像.
可以使用国内镜像.
可以使用国内镜像.
参考这篇文章:
Kubernetes国内镜像、下载安装包和拉取gcr.io镜像: https://blog.csdn.net/nklinsirui/article/details/80581286
Kubernets国内镜像 阿里云提供了Kubernetes国内镜像来安装kubelet、kubectl 和 kubeadm。 登陆阿里云镜像网站:https://opsx.alibaba.com/mirror 查找关键字“kubernetes”,点击【帮助】按钮。 ———————————————— Debian / Ubuntu
swapoff -a && sed -i '/ swap / s/^(.*)$/#1/g' /etc/fstab
apt-get update && apt-get install -y apt-transport-https
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main EOF
apt-get update
apt-get install -y kubelet kubeadm kubectl ———————————————— CentOS / RHEL / Fedora cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF setenforce 0 yum install -y kubelet kubeadm kubectl systemctl enable kubelet && systemctl start kubelet ————————————————
前面五个步骤, 参考这里分割线内部即可
-------------华丽的分割线--结束------------
第六步: 禁止组件更新
apt-mark hold kubelet kubeadm kubectl

第七步: 初始化master
1. 禁用虚拟内存
swapoff -a
2. 初始化kubeadm
kubeadm init --pod-network-cidr=10.244.0.0/16
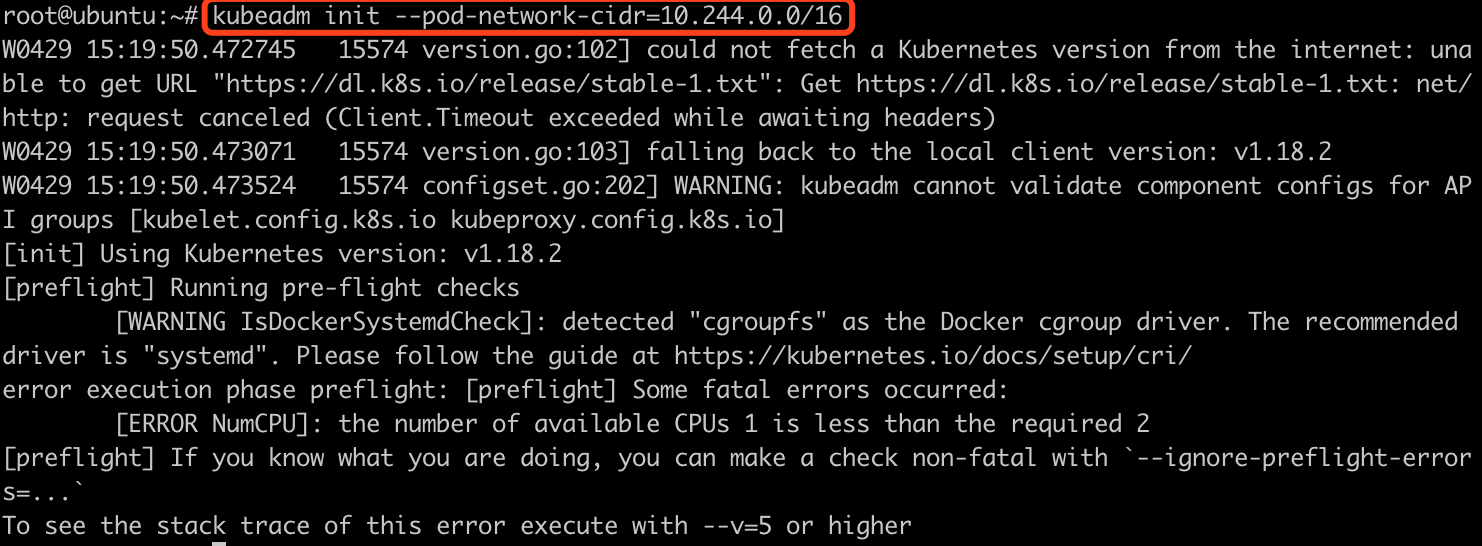
直接运行会报错, 要求是2cpu,我们是1cpu, 如果想要忽略,需要加上一个参数--ignore-preflight-errors=NumCPU
kubeadm init --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=NumCPU
执行结果:
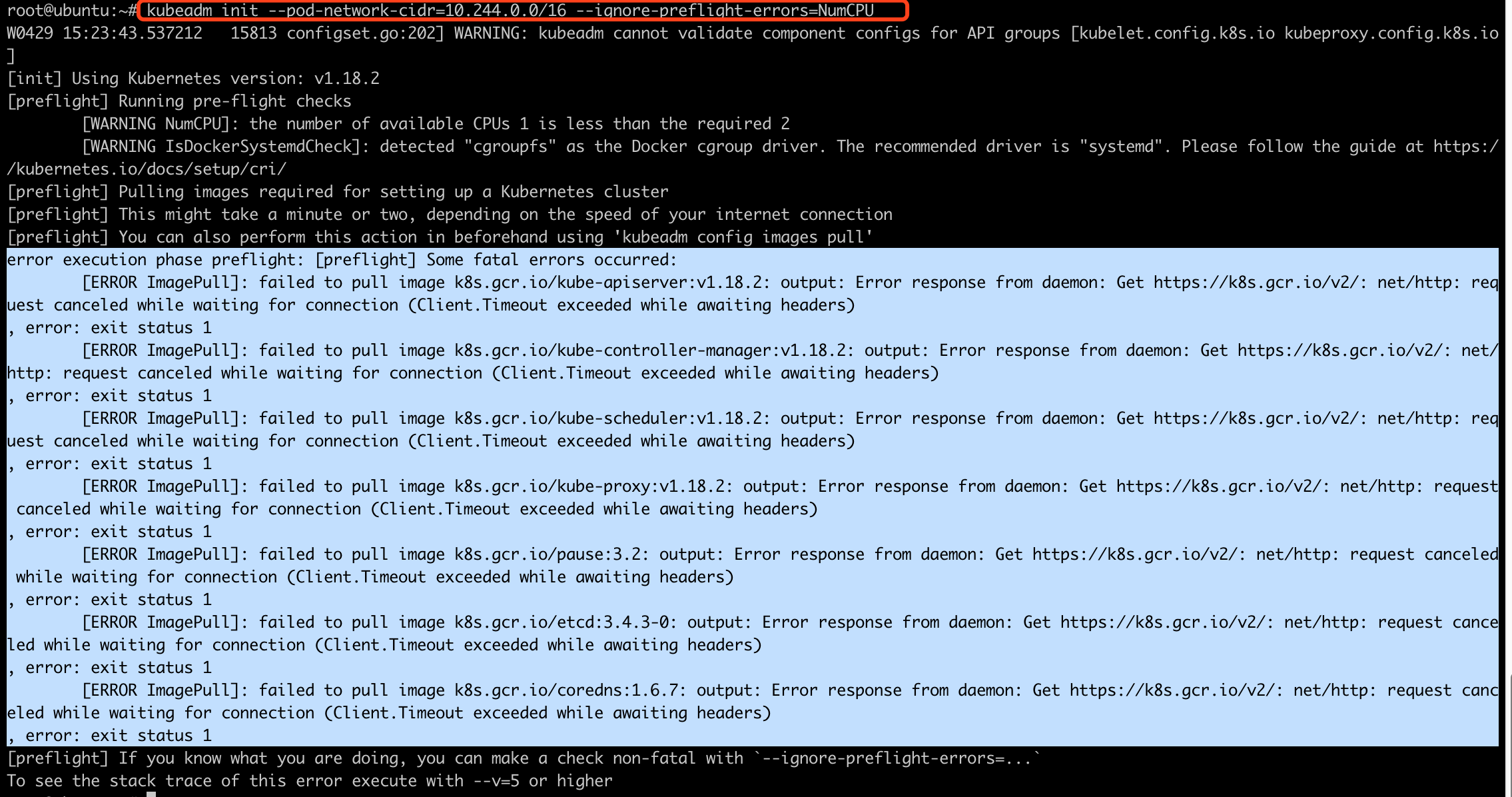
我们看到,在初始化下载镜像的时候, 有部分组件下载失败了.
我们记录下来这些下载失败的组件
error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-apiserver:v1.18.2: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-controller-manager:v1.18.2: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-scheduler:v1.18.2: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-proxy:v1.18.2: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/pause:3.2: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/etcd:3.4.3-0: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/coredns:1.6.7: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1
然后通过如下方法, 重新下载:
1. 可以从keveon或者mirrorgooglecontainer或者阿里云镜像库中下载, 当其中一个镜像库找不到时, 尝试另一个
2. 在手工设置tag
使用下面三组命令:
docker pull mirrorgooglecontainers/$imageName docker tag mirrorgooglecontainers/$imageName k8s.gcr.io/$imageName docker rmi mirrorgooglecontainers/$imageName
下面我们来一个一个下载
1). 下载docker pull mirrorgooglecontainers/kube-apiserver:v1.18.
docker pull registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-apiserver:v1.18.2
拉取镜像参考文章(说的很详细): 国内拉取google kubernetes镜像https://blog.csdn.net/networken/article/details/84571373
我最终使用的是阿里云镜像, 找到镜像详情页面, 可以复制地址
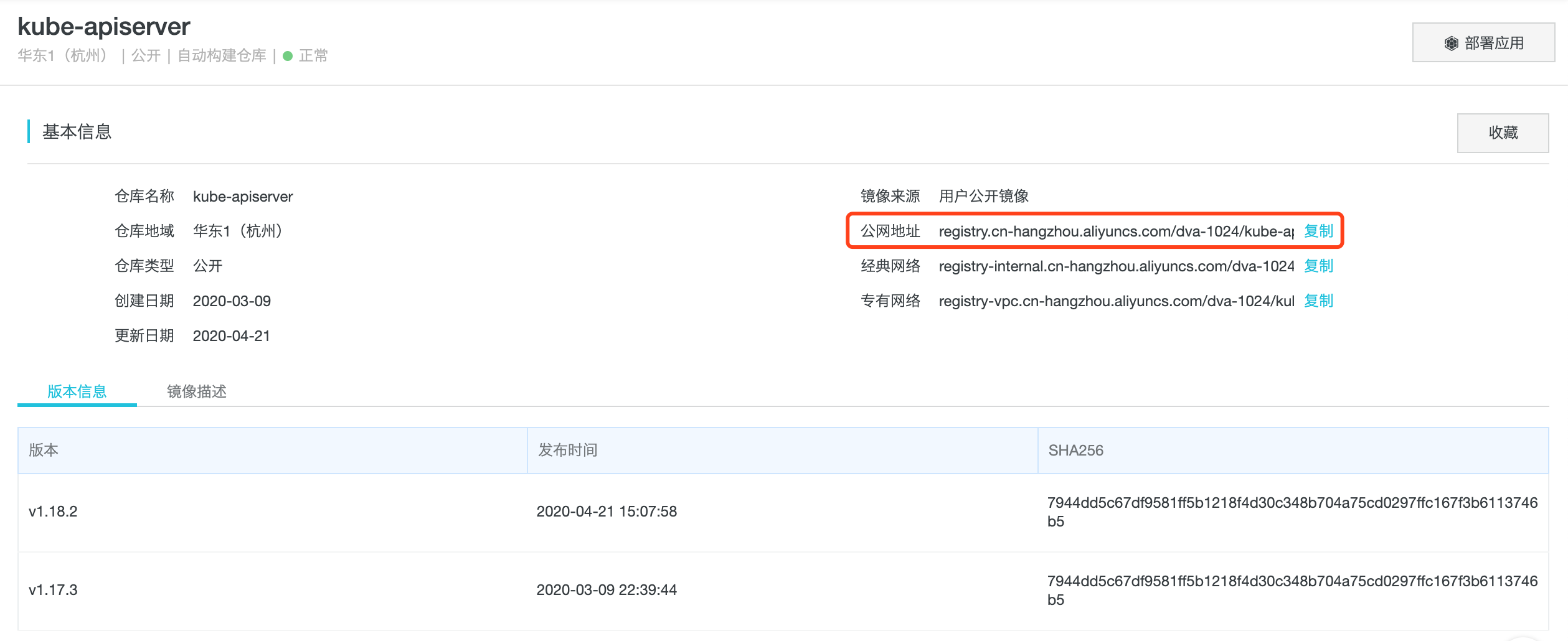
2). 修改下载下来的镜像的tag为k8s.gcr.io的
docker tag registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-apiserver:v1.18.2 k8s.gcr.io/kube-apiserver:v1.18.2

3). 删除阿里云镜像
docker rmi registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-apiserver:v1.18.2

4) 所有其他的镜像都这么操作, 一共7个
# 拉取镜像 docker pull registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-proxy:v1.18.2 docker pull registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-controller-manager:v1.18.2 docker pull registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-apiserver:v1.18.2 docker pull registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-scheduler:v1.18.2 docker pull registry.cn-hangzhou.aliyuncs.com/dva-1024/pause:3.2 docker pull registry.cn-hangzhou.aliyuncs.com/dva-1024/coredns:1.6.7 docker pull registry.cn-hangzhou.aliyuncs.com/dva-1024/etcd:3.4.3-0 -------------------------------------- #修改tag docker tag registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-proxy:v1.18.2 k8s.gcr.io/kube-proxy:v1.18.2 docker tag registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-apiserver:v1.18.2 k8s.gcr.io/kube-apiserver:v1.18.2 docker tag registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-controller-manager:v1.18.2 k8s.gcr.io/kube-controller-manager:v1.18.2 docker tag registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-scheduler:v1.18.2 k8s.gcr.io/kube-scheduler:v1.18.2 docker tag registry.cn-hangzhou.aliyuncs.com/dva-1024/pause:3.2 k8s.gcr.io/pause:3.2 docker tag registry.cn-hangzhou.aliyuncs.com/dva-1024/coredns:1.6.7 k8s.gcr.io/coredns:1.6.7 docker tag registry.cn-hangzhou.aliyuncs.com/dva-1024/etcd:3.4.3-0 k8s.gcr.io/etcd:3.4.3-0 ---------------------------------- # 删除镜像 docker rmi registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-proxy:v1.18.2 docker rmi registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-controller-manager:v1.18.2 docker rmi registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-apiserver:v1.18.2 docker rmi registry.cn-hangzhou.aliyuncs.com/dva-1024/kube-scheduler:v1.18.2 docker rmi registry.cn-hangzhou.aliyuncs.com/dva-1024/pause:3.2 docker rmi registry.cn-hangzhou.aliyuncs.com/dva-1024/coredns:1.6.7 docker rmi registry.cn-hangzhou.aliyuncs.com/dva-1024/etcd:3.4.3-0
效果如下:
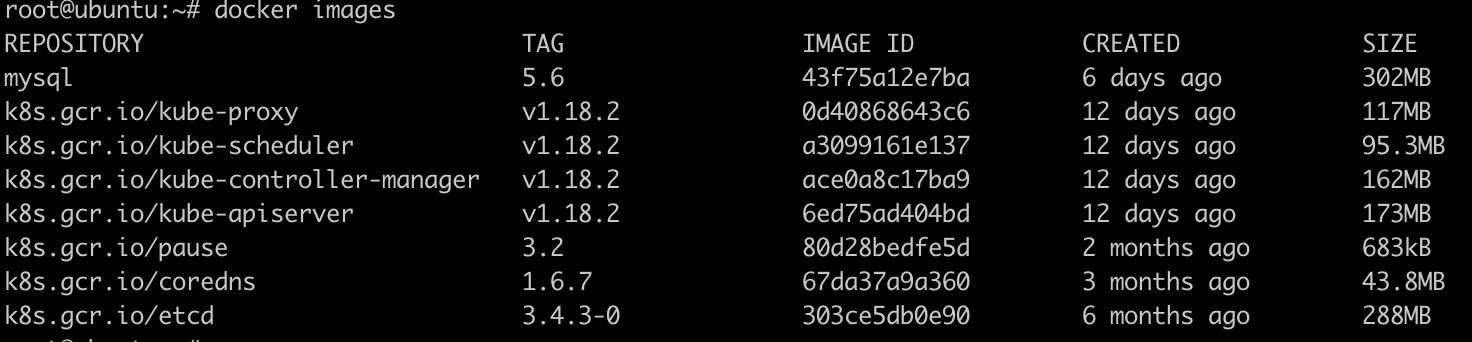
3. 重新执行初始化, 并记录最后生成的kubeadm join命令
kubeadm init --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=NumCPU
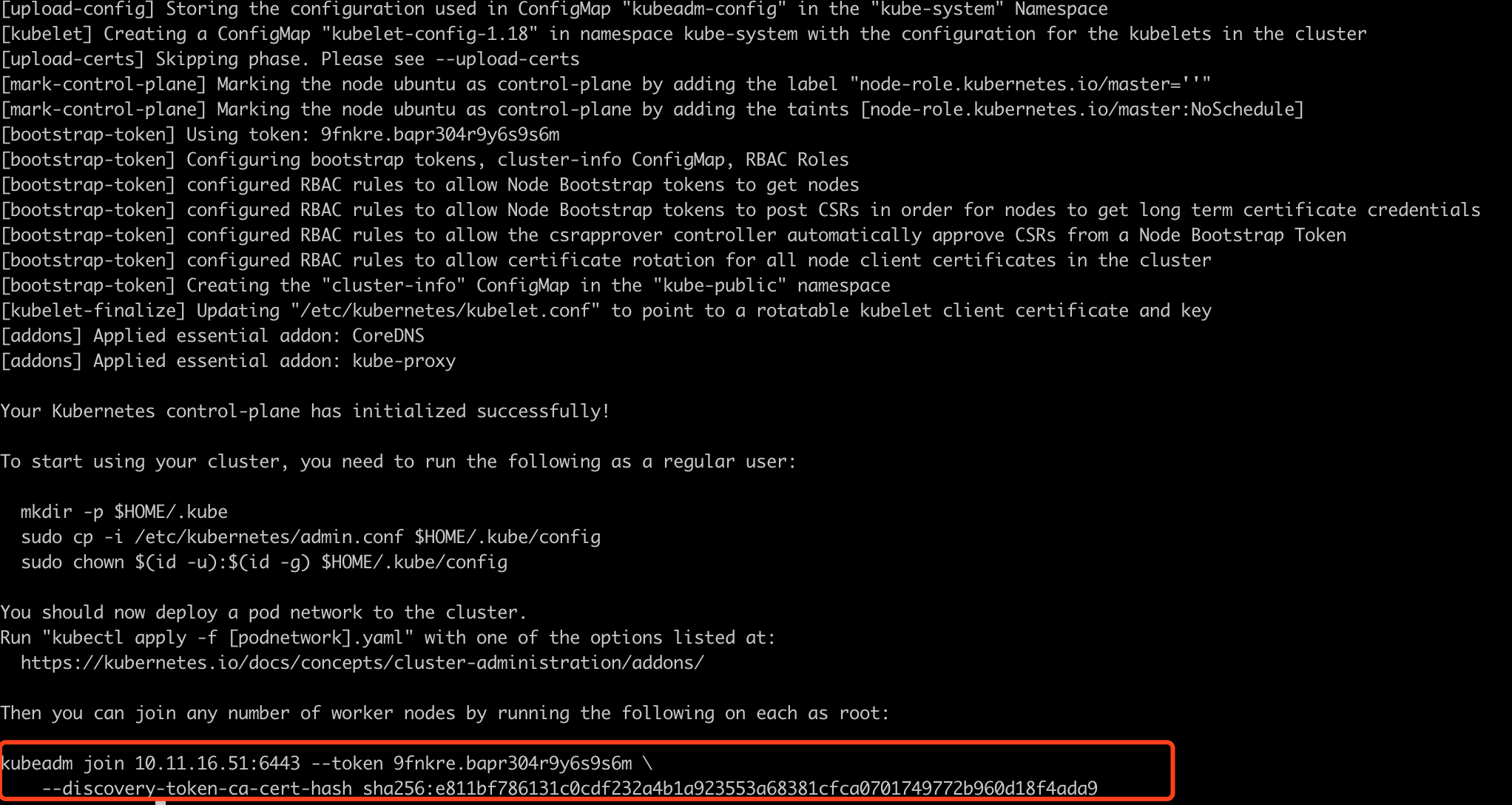
记录生成的kubeadm join命令
kubeadm join 192.168.1.109:6443 --token ehtgdn.c7cjv35rqp45it25
--discovery-token-ca-cert-hash sha256:2f6192bc28397d1bbd00922538a9588345c37f890e7c8ace5d22585fa1922464
kubeadm join 192.168.1.106:6443 --token vezzap.0w213k8ms11a0v51 --discovery-token-ca-cert-hash sha256:4fcac7c487209d7c354351ba6f93110253df4d0440fc68cb23fc4ac0baed4e0c
为什么要记录呢? 后面我们可以吧生成的kubeadm join记录下来, 然后后面在节点上执行一下, 就表示这个节点加入了k8s集群
此条kubeadm init操作完成以下步骤:
1> 准备工作,检查主机配置是否符合要求等 2> 下载相关镜像 (其实是我们提前准备好的) 3> 启动kubelet,配置对应的配置文件, 为各个组件生成证书,放在/etc/kubernetes/pki/ 目录 核心组件配置文件,放在/etc/kubernetes/manifests 目录下 (静态pod生命周期与pod一致,可以通过yaml或者http方式创建) 4> kubeadm的配置文件保存,上报各种接口和信息给k8s master 5> 生成 token,node申请加入集群时授权,启用基于角色的访问控制 6> 安装两个重要组件,coredns,kube-proxy。 7> 提示安装完成,提示使用准备命令。
4. 执行下面三个命令
1. mkdir -p $HOME/.kube 2. sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config 3.

第八步: 安装网络插件(只在master上执行)
sysctl net.bridge.bridge-nf-call-iptables=1
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
把文件下载到本地
第二个命令我在命令行执行连接超时. 直接在网页打开(需要翻墙).
# Ubuntu安装rzsz
sudo apt-get install lrzsz


--- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: flannel rules: - apiGroups: - "" resources: - pods verbs: - get - apiGroups: - "" resources: - nodes verbs: - list - watch - apiGroups: - "" resources: - nodes/status verbs: - patch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: flannel roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: flannel subjects: - kind: ServiceAccount name: flannel namespace: kube-system --- apiVersion: v1 kind: ServiceAccount metadata: name: flannel namespace: kube-system --- kind: ConfigMap apiVersion: v1 metadata: name: kube-flannel-cfg namespace: kube-system labels: tier: node app: flannel data: cni-conf.json: | { "name": "cbr0", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] } net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan" } } --- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: kube-flannel-ds namespace: kube-system labels: tier: node app: flannel spec: template: metadata: labels: tier: node app: flannel spec: hostNetwork: true nodeSelector: beta.kubernetes.io/arch: amd64 tolerations: - key: node-role.kubernetes.io/master operator: Exists effect: NoSchedule serviceAccountName: flannel initContainers: - name: install-cni image: quay.io/coreos/flannel:v0.10.0-amd64 command: - cp args: - -f - /etc/kube-flannel/cni-conf.json - /etc/cni/net.d/10-flannel.conflist volumeMounts: - name: cni mountPath: /etc/cni/net.d - name: flannel-cfg mountPath: /etc/kube-flannel/ containers: - name: kube-flannel image: quay.io/coreos/flannel:v0.10.0-amd64 command: - /opt/bin/flanneld args: - --ip-masq - --kube-subnet-mgr resources: requests: cpu: "100m" memory: "50Mi" limits: cpu: "100m" memory: "50Mi" securityContext: privileged: true env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace volumeMounts: - name: run mountPath: /run - name: flannel-cfg mountPath: /etc/kube-flannel/ volumes: - name: run hostPath: path: /run - name: cni hostPath: path: /etc/cni/net.d - name: flannel-cfg configMap: name: kube-flannel-cfg
然后保存到本地.
修改kube-flannel.yml文件, 增加下图中红色的部分

将这个文件改完放在根目录~下
![]()
执行命令, 应用到kubeadm
kubectl apply -f kube-flannel.yml
查看当前master的状态
kubectl get node

如果不是ready状态, 查看日志, 看原因
journalctl -f -u kubelet.service
比如, 没有安装网络插件
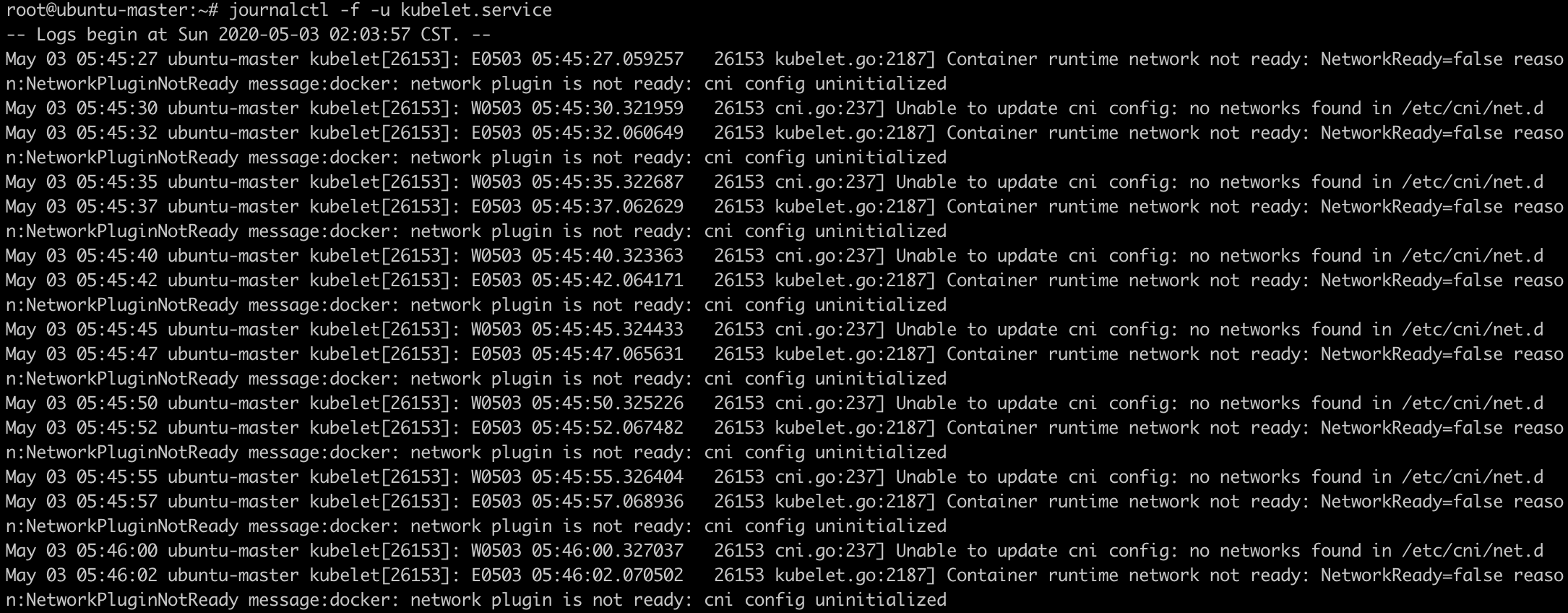
遇到的问题error:
1、error: unable to recognize “mycronjob.yml”: no matches for kind “CronJob” in version “batch/v2alpha1”
去kube-apiserver.yaml文件中添加: - --runtime-config=batch/v2alpha1=true,然后重启kubelet服务,就可以了
下面是具体操作:
cd /etc/kubenetes/manifest
vi kube-apiserver.yaml
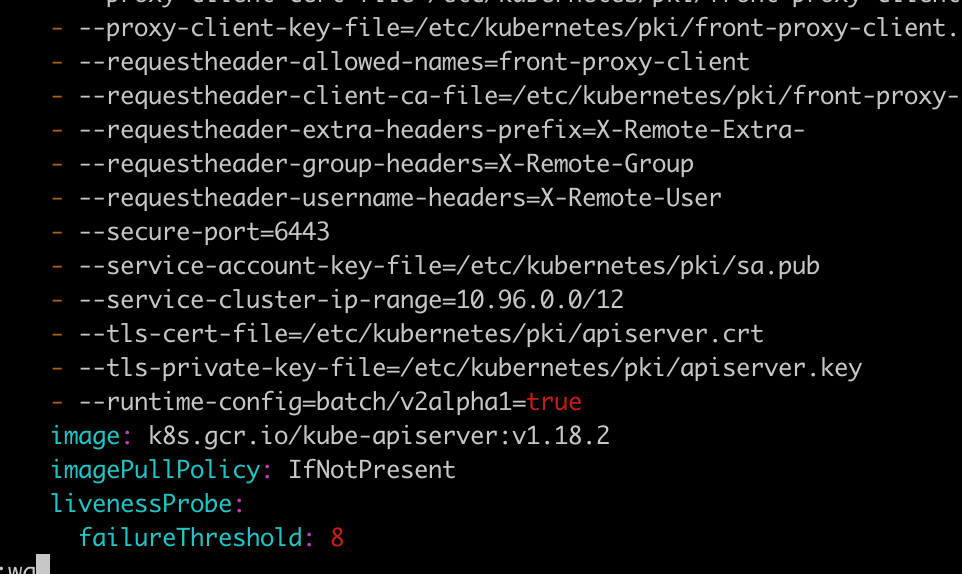
重启

这个问题是参考了下面这两篇文章解决的
参考文章:
1. https://blog.csdn.net/qq_34857250/article/details/82562514 第六条
2. https://www.cnblogs.com/aaroncnblogs/articles/8901173.html 在后面的位置,包括重启kubectl
2. no matches for kind "DaemonSet" in version "extensions/v1beta1"
这个问题是参考这篇文章解决的. 按照它上面说的操作:https://blog.csdn.net/wangmiaoyan/article/details/101216496
第九步:添加node
1. 将之前记录下来的kubeadm join 命令执行 2. 禁用虚拟内存 swapoff -a 3. sysctl net.bridge.bridge-nf-call-iptables=1
1. 将之前记录下来的kubeadm join命令执行
kubeadm join 192.168.1.109:6443 --token ehtgdn.c7cjv35rqp45it25 --discovery-token-ca-cert-hash sha256:2f6192bc28397d1bbd00922538a9588345c37f890e7c8ace5d22585fa1922464
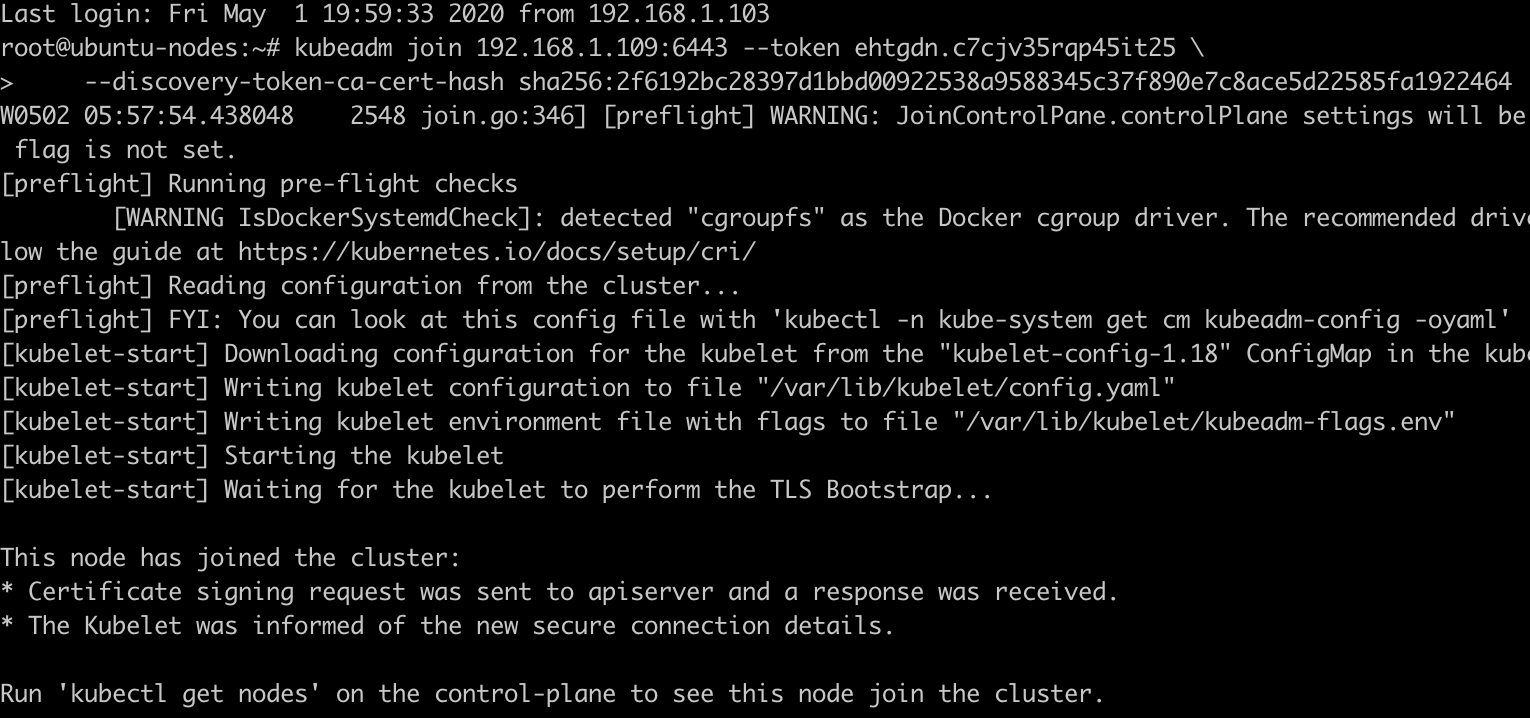
2. 禁用虚拟内存 swapoff -a
3. 执行sysctl net.bridge.bridge-nf-call-iptables=1
4. 检查node是否ready
在master上进行检查
kubectl get node

都是NotReady, 下面我们来处理NotReady的问题
5. 检查所有pod是否正常
kubectl get pod --all-namespaces -o wide
如果有pod处于非running状态, 则查看该pod,
kubectl describe pod *** -n kube-system,
有可能是镜像无法下载导致镜像启动失败, 如果是, 手动在node上pull image, 然后在master上删掉对应的pod,
k8s会自动重新调度pod, 删除pod命令:
kubectl delete pod *** -n kube-system
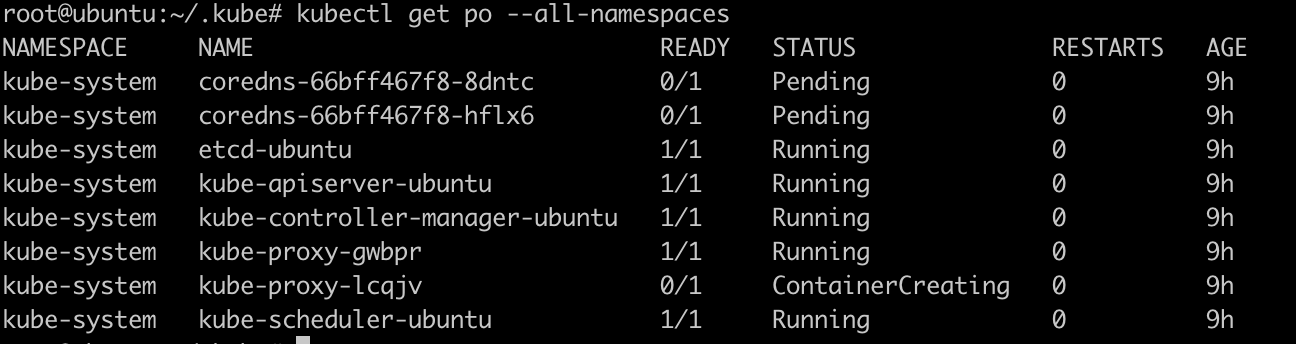
现在coredns-66bff467f8-8dntc是Pending状态, 非Running状态. 我们来处理一下
a) 查看该pod
kubectl describe pod kube-proxy-lcqjv -n kube-system

从错误原因可以看出, 需要pause:3.2镜像, 但是没有.
b) 在node节点上, 拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/dva-1024/pause:3.2
docker tag registry.cn-hangzhou.aliyuncs.com/dva-1024/pause:3.2 k8s.gcr.io/pause:3.2
docker rmi registry.cn-hangzhou.aliyuncs.com/dva-1024/pause:3.2
c) 在master节点上删除kube-proxy-lcqjv这个pod, 然后让他重新调度
kubectl delete pod kube-proxy-lcqjv -n kube-system
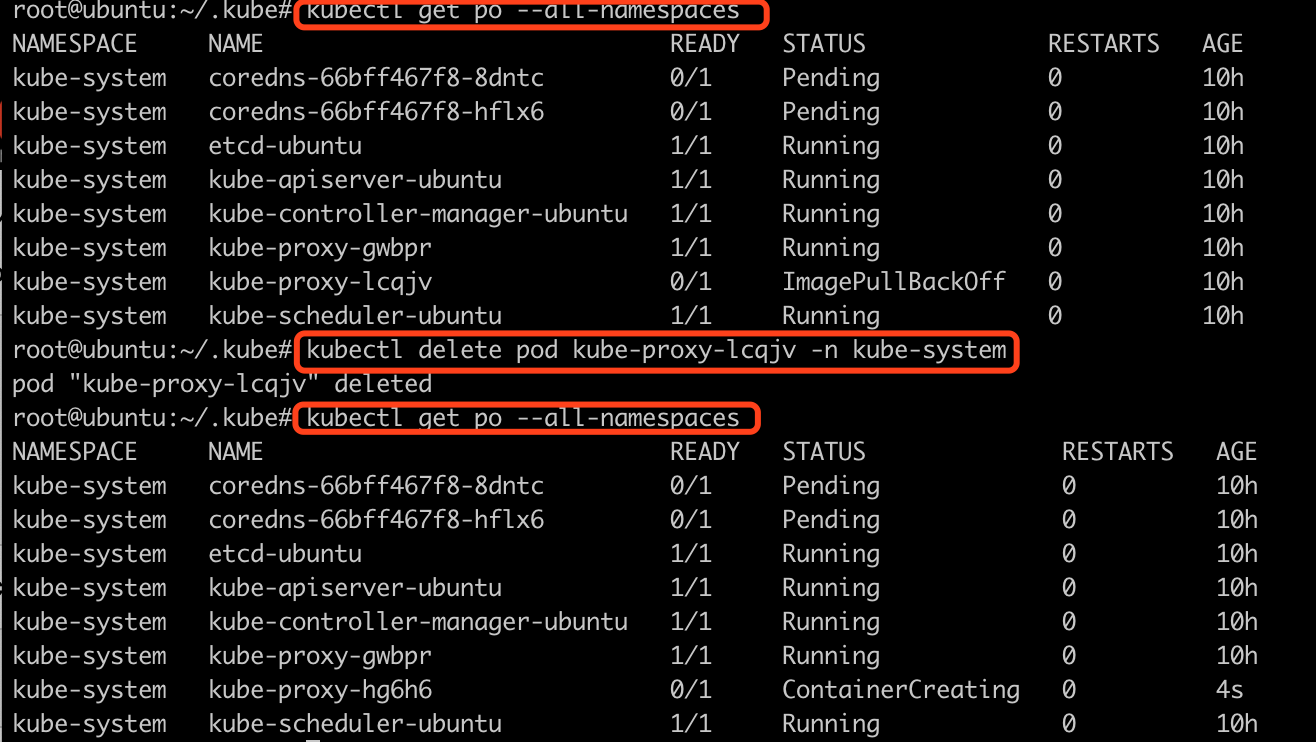
删除后, 重新查看发现还是有pod是ContainerCreating状态, 继续按照上面的方法, 查看. 直到这些pod都running为止
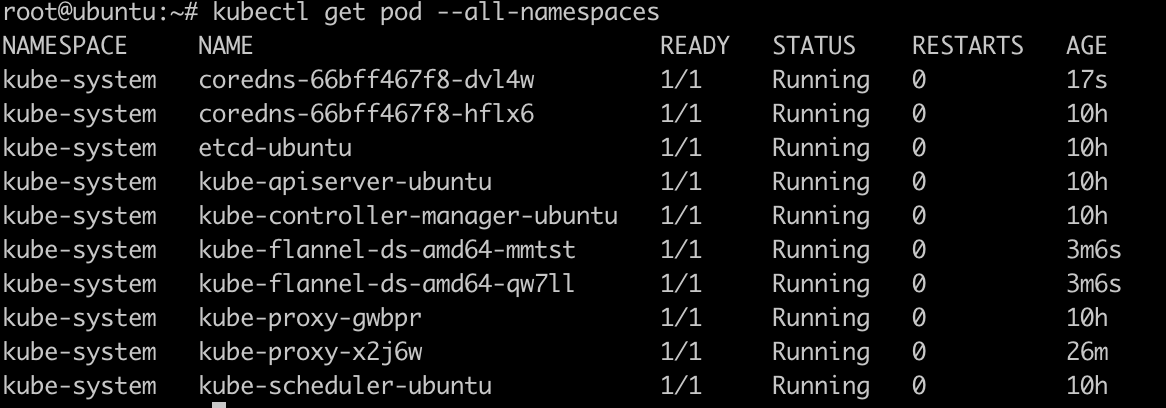
查询节点状态
kubectl get node

node是Ready的状态, 但是....master依然是notReady
处理master的NotReady状态
查看节点日志:
journalctl -f -u kubelet.service
备注: 处理pod都是pending状态, 参考文章: https://blog.csdn.net/wangmiaoyan/article/details/101216496
第十步: k8s安装异常处理
1. 在node上执行kubeadm reset 可以断开node, 然后重新join
2. 在master上执行kubeadm reset后可以重新init
ERROR1 : 执行kubeadm reset后, 会遇到这个问题ERROR
Unable to connect to the server: x509: certificate signed by unknown authority
问题描述:
昨天按照教程搭建了一个集群,今天想重新实验下,于是执行kubeadm reset命令清除集群所有的配置。 接着按照部署的常规流程执行kubeadm init --kubernetes-version=v1.14.3 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=0.0.0.0命令创
建集群。然后执行以下几个命令: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config 接着当我执行kubectl get nodes等命令时,所有的命令都会打印出错误:Unable to connect to the server: x509: certificate signed by unknown authority (
possibly because of “crypto/rsa: verification error” while trying to verify candidate authority certificate “kubernetes”) 当在这些 kubectl 命令后加入 --insecure-skip-tls-verify 参数时,就会报如下错误:error: You must be logged in to the server (Unauthorized)
我记得reset完成的时候, 给了一个提示,如下:

没有手动删除~/.kube/config配置文件. 而我重新执行了init初始化以后, 没有再次执行这三句话, 因为里面有下面的这个文件
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
于是, 把关注点放在config这个配置的第二句话上
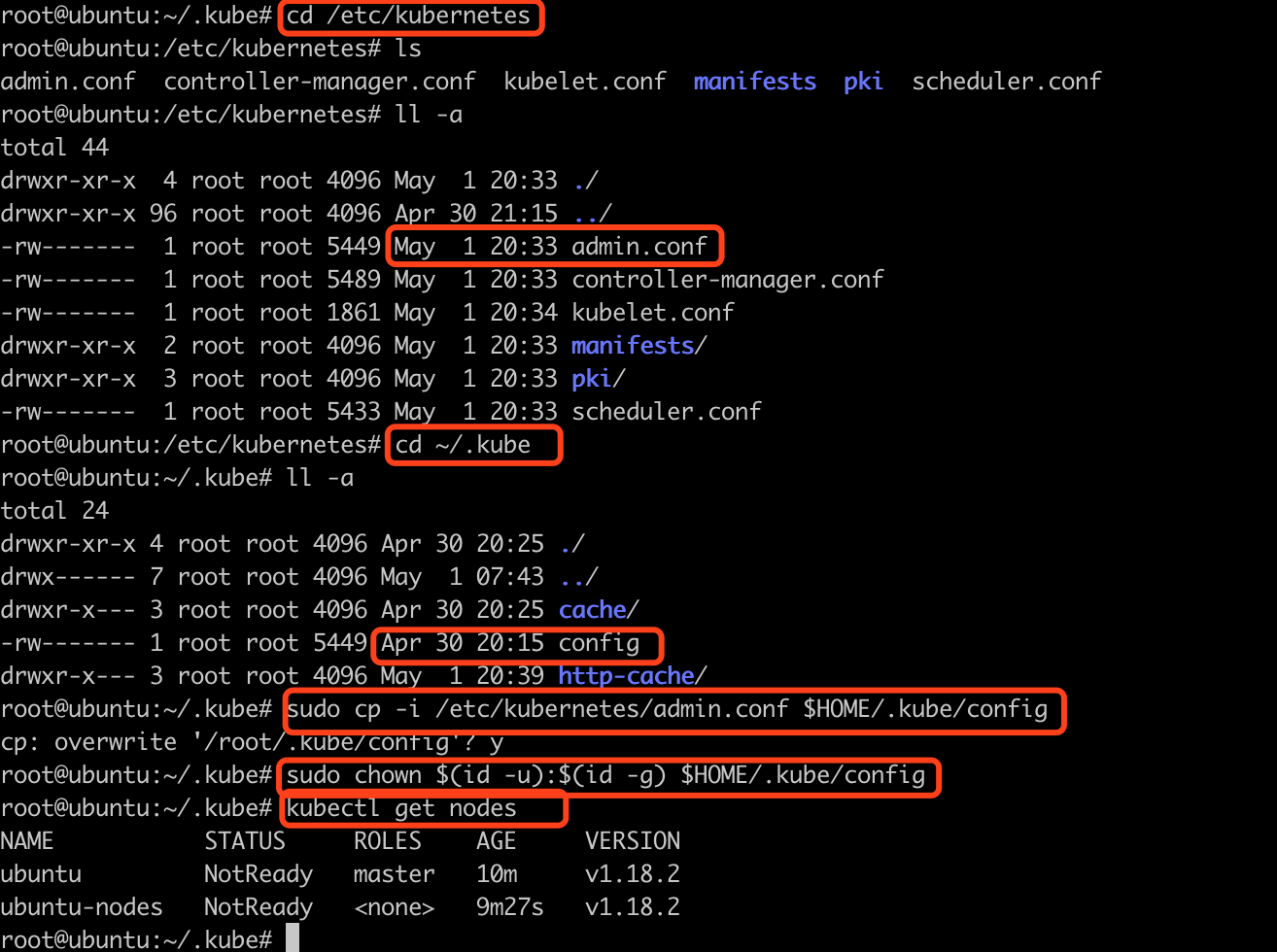
首先. 看了cd /etc/kubernetes目录, 发现admin.conf的创建时间是5月1号
然后,看了cd ~/.kube目录, 发现config的创建时间是4月30号. 很显然不是最新的.
于是, 执行了sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config 和sudo chown $(id -u):$(id -g) $HOME/.kube/config
在执行kubectl get nodes, 可以正常显示了.
3. 重新启动后, 要执行如下命令
0. ufw disable 1.swapoff -a && sed -i '/ swap / s/^(.*)$/#1/g' /etc/fstab
2. systemctl daemon-reload // 重新读取本地配置文件
3. systemctl restart kubelet
设置开机自启 systemctl enable kubelet
头疼的问题: 从单位回到家, 网络的ip地址变了
1. 修改配置文件
2. 将网络换成静态ip
参考文章: https://blog.csdn.net/whywhy0716/article/details/92658111
参考文章:
1. k8s 集群部署问题整理: https://blog.csdn.net/qq_34857250/article/details/82562514
2. https://www.cnblogs.com/aaroncnblogs/articles/8901173.html
3. https://blog.csdn.net/wangmiaoyan/article/details/101216496