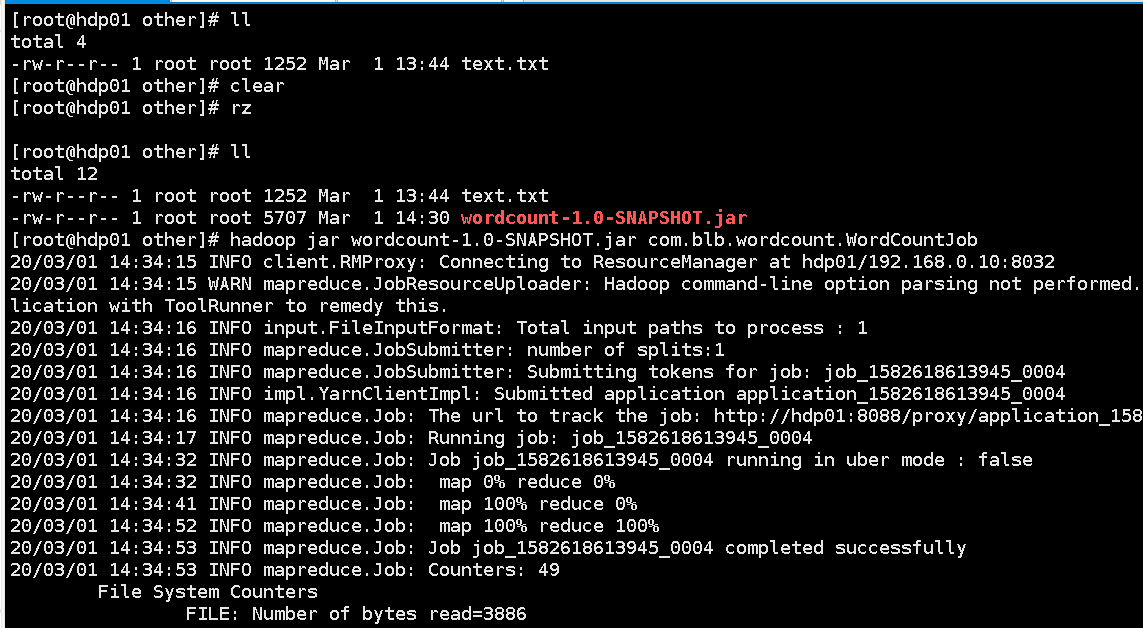
最终结果展示:
一.MapReduce的概念
1)MapReduce是一个离线计算的框架
2)MPAReduce是基于HDFS之上的,没有HDFS就没有MapReduce
3)MapReduce由两个阶段组成:Map和Reduce,用户只需实现map()和reduce()即可完成分布式计算
4)Map阶段:逐个遍历【用来收集数据的】
5)Reducer阶段:做合并操作【用来合并数据】
二.具体实现
1.创建maven项目,导入jar包
<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <!--COMMON是hadoop一切的核心--> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.3</version> </dependency> <!--hadoop是基于客户端服务器的--> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.3</version> </dependency> <!--操作MapReduce需要HDFS的依赖--> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.3</version> </dependency> <!--做MapReduce所需依赖包--> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.7.3</version> </dependency> </dependencies>
2.项目结构

3.编写WordCountMapper类
package com.blb.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * Mapper<LongWritable,String, Text, IntWritable> * 第一个参数:表示读取的每一行的起始量 * 第二个参数:表示读取的一行数据 * 第三个参数:表示我们要输出的key类型 * 第三个参数:表示我们要输出的value类型 * hadoop中提供了一套自己的序列化和反序列化的接口Writable * 对应的8种基本数据类型和String类型都帮我们实现了Writable接口 * int IntWritable * long LongWritable * double DoubleWritable * String Text * null NullWritable * int = IntWritable.get() 将IntWritable类型转换为int类型 * new IntWritable(1) 将int类型的1转换为IntWritable类型 */ public class WordCountMapper extends Mapper<LongWritable,Text, Text, IntWritable> { //ctrl+o 找需要重写的方法 /** * 该方法执行一行调用一次 * @param key :每一行的其实偏移量 * @param value :每一行的内容 * @param context :上下文对象 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //去掉每一行的空格 String s = value.toString().replaceAll(" ", ""); //将字符串转换为字符数组 char[] chars = s.toCharArray(); //循环遍历数组,然后写入context for (char c:chars){ //输出示例:<"我",1> context.write(new Text(c+""),new IntWritable(1)); } } }
4.编写WordCountReduce类
package com.blb.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Reducer<Text, IntWritable,Text,IntWritable> * Reducer处理的是map的结果 * 第一个参数:是从map中传递过来的key的类型 * 第二个参数:是从map中传递过来的value类型 * 第三个参数:是Reducer执行之后写入文件的key类型【最终统计的词】 * 第四个参数:是Reducer执行之后写入文件的value类型【每个词出现了多少次】 * map输出的结果:<"我",1> <"爱",1> <"我",1> * reducer拿到数据之前会做一个分组[key相同的为一组],分组是框架内部完成的, * Reducer拿到的数据:<"我",<1,1>> <"爱",1> */ public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> { /** * 该方法一组调用一次,对结果进行求和 * @param key :每一组中相同的key * @param values :每一组相同的key对应的所有value值<"我",<1,1>> * @param context :上下文对象,用于传输,将数据写入到HDFS中 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //用于做统计 int sum = 0; for (IntWritable i:values){ //将IntWritable类型的值转换为int类型的值然后求和 sum += i.get(); } context.write(key,new IntWritable(sum)); } }
5.编写WordCountJob类
package com.blb.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * WordCountJob是一个可执行程序 * 主要的目的是将Mapper和Reducer这两个类组合起来 */ public class WordCountJob { public static void main(String[] args) { //先添加一个配置文件 Configuration conf = new Configuration(); //配置服务器的地址和端口 conf.set("fs.defaultFS","hdfs://hdp01:9000"); try { //启动一个Job【作用:封装程序中的mapper和reducer,封装输入输出】 Job job = Job.getInstance(conf); //设置计算机的主驱动类,运行的时候回达成jar包运行 job.setJarByClass(WordCountJob.class); //设置Mapper类和Reducer类 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReduce.class); //设置mapper的输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置Reducer的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置输入的路径,需要统计单词的路径 FileInputFormat.setInputPaths(job,new Path("/file/text.txt")); //设置输出的路径,执行完之后的结果的存放位置 FileOutputFormat.setOutputPath(job,new Path("/out/")); //job提交 job.waitForCompletion(true); //true:是否打印日志 } catch (Exception e) { e.printStackTrace(); } } }
6.将项目打成jar包
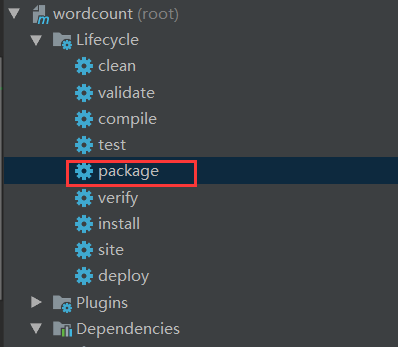
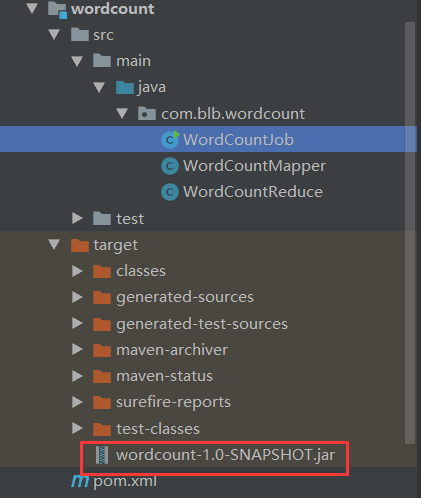
7.启动hadoop
(1)启动hdfs:start-dfs.sh
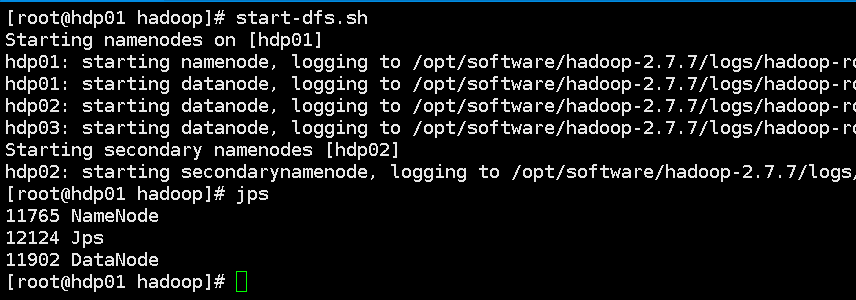
(2)启动MapReduce:start-yarn.sh
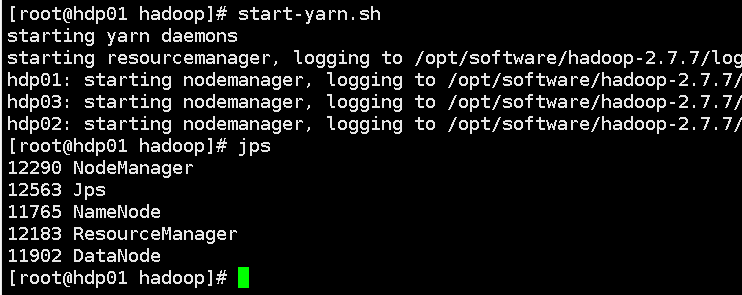
8.上传本地文本到linux和hdfs上
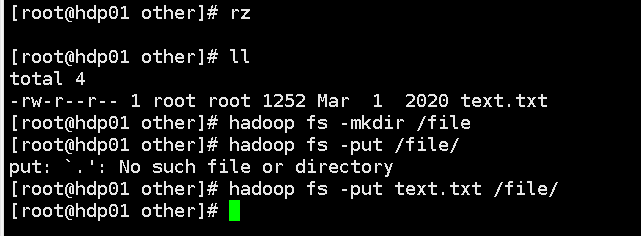

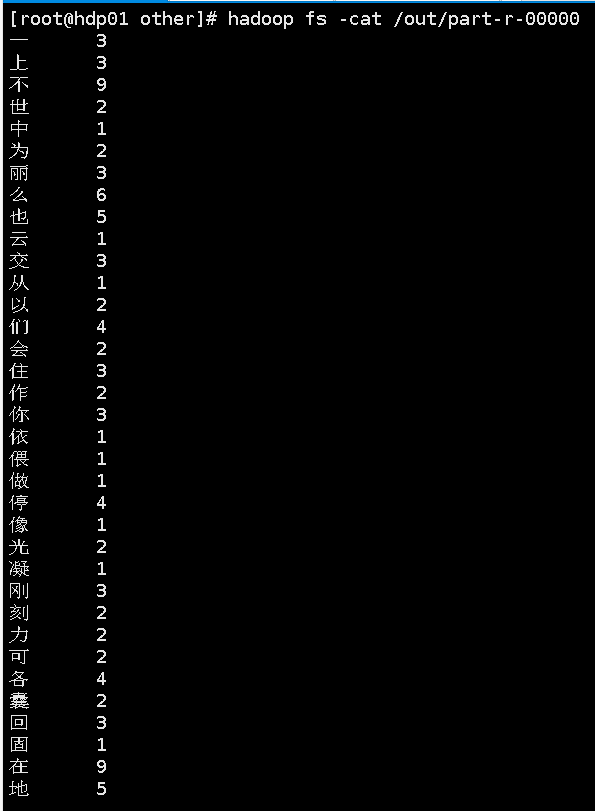
9.上传先前打好的jar包后运行

可能会出现的问题1:3个节点的时间不同步
解决:ntpdate ntp1.aliyun.com 将为当前系统的时间设置为阿里云的时间
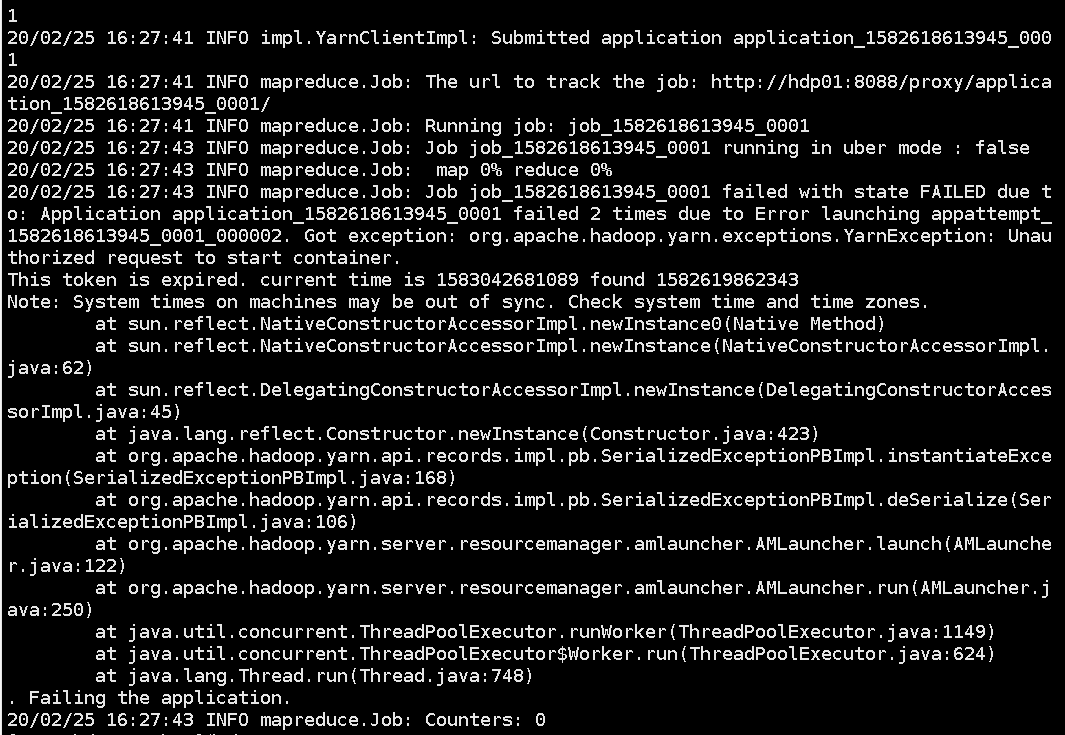
10.运行成功界面