一、MQ消息发送

1、发送端MQ-client(消息生产者:Producer)将消息发送给MQ-server;
2、MQ-server将消息落地;
3、MQ-server回ACK给MQ-client(Producer);
4、MQ-server将消息发送给消息接受端MQ-client(消息消费者:Customer);
5、MQ-client(Customer)消费接受到消息后发送ACK给MQ-server;
6、MQ-server将落地消息删除
二、MQ发送和接收消息的几种方式
发送方式如下:
1、同步发送
原理:可靠同步发送是指消息发送方发出数据之后,会在收到接收方发回响应之后才发下一个数据包的通讯方式
应用场景:重要通知邮件、报名短信通知、营销短信系统等
2、异步发送
原理:可靠异步发送是指发送方发出数据后,不等接收方发回响应,接着发送下个数据包的通讯方式。MQ 的异步发送,需要用户实现异步发送回调接口(SendCallback),在执行消息的异步发送时,应用不需要等待服务器响应即可直接返回,通过回调接口接收服务器响应,并对服务器的响应结果进行处理。
应用场景:异步发送一般用于链路耗时较长,对 RT 响应时间较为敏感的业务场景,例如用户视频上传后通知启动转码服务,转码完成后通知推送转码结果等。
3、单向发送
原理:单向发送特点为只负责发送消息,不等待服务器回应且没有回调函数触发,即只发送请求不等待应答。此方式发送消息的过程耗时非常短,一般在微秒级别。
应用场景:适用于某些耗时非常短,但对可靠性要求并不高的场景,例如日志收集。
三、MQ的几种模式:
1、简单模式:

一个生产者对应一个消费者!生产者发送消息给消息列队,消费者接收消息(一旦消费者接收了消息,消息列队就会自动删除消息,不管是消费者挂了还是网络断了或者其他情况造成的消费者没有完全接收消息列队里的消息,消息列队都会自动删除消息)
2、工作模式:
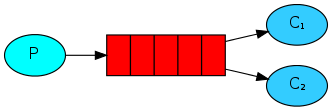
一个生产者对应多个消费者,但是只能有一个消费者获得消息!
3、发布订阅模式:

一个消费者将消息发送到交换器,交换器绑定多个队列,然后被监听该队列的消费者所接收并消费
4、路由模式:

生产者将消息发送到direct交换器,在绑定队列和交换器的时候有一个路由key,生产者发送的消息会指定一个路由key,那么消息只会发送到相应key相同的队列,接着监听该队列的消费者消费信息.
5、topic主题模式:
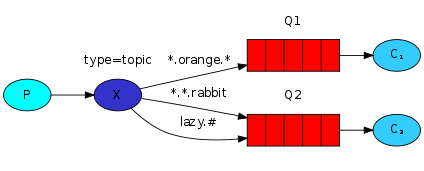
在路由模式基础上,让路由key可以使用通配符(符号"#"表示匹配一个或多个词,符号"*"表示匹配一个词)。相当于进行分类。灵活程度更高些。隐患:容易误伤。
四、MQ种类介绍
常用的MQ类型有:ActiveMQ、RabbitMQ、RocketMQ、Kafka
优缺点对比如下:
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
| 单机吞吐量 | 万级,比 RocketMQ、Kafka 低一个数量级 | 万级,比 RocketMQ、Kafka 低一个数量级 | 10 万级,支撑高吞吐 | 10 万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic 数量对吞吐量的影响 | topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 | ||
| 时效性 | ms 级 | 微秒级,这是 RabbitMQ 的一大特点,延迟最低 | ms 级 | 延迟在 ms 级以内 |
| 可用性 | 高,基于主从架构实现高可用 | 高,基于主从架构实现高可用 | 非常高,分布式架构 | 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,可以做到 0 丢失 | 经过参数优化配置,可以做到 0 丢失 |
| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,并发能力很强,性能极好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 功能较为简单,主要支持简单的 | MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用 |
五、MQ相关问题
1.MQ是如何保证消息的高可用性?
1)rabbitMQ的高可用性:
单机模式:一般生产不会使用,故不存在高可用的优化;
普通集群模式:在多个服务器上部署多个MQ实例,但是创建的queue元数据只会放在一个rabbitmq实例上面;如果消费连接到其他实例上,那么该实例就会从拥有queue的实例上获取数据返回给你。这种普通的集群只是做到了提高吞吐量,并不能达到消息的高可用,并且有queue的实例机器一旦宕机或者不能持久化,将会导致其他实例无法进行数据拉取;
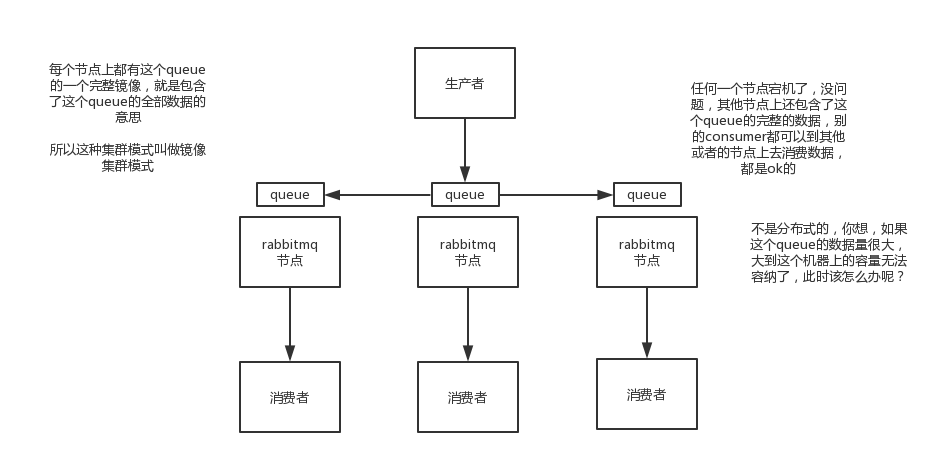
镜像集群模式:类似于普通集群模式,但是queue元数据和消息会同时存在于多个实例上,就算其中一个服务宕机,也不会影响到整个集群的完整性,这样就做到了消息的高可用;缺点:性能开销大、无法线性扩容
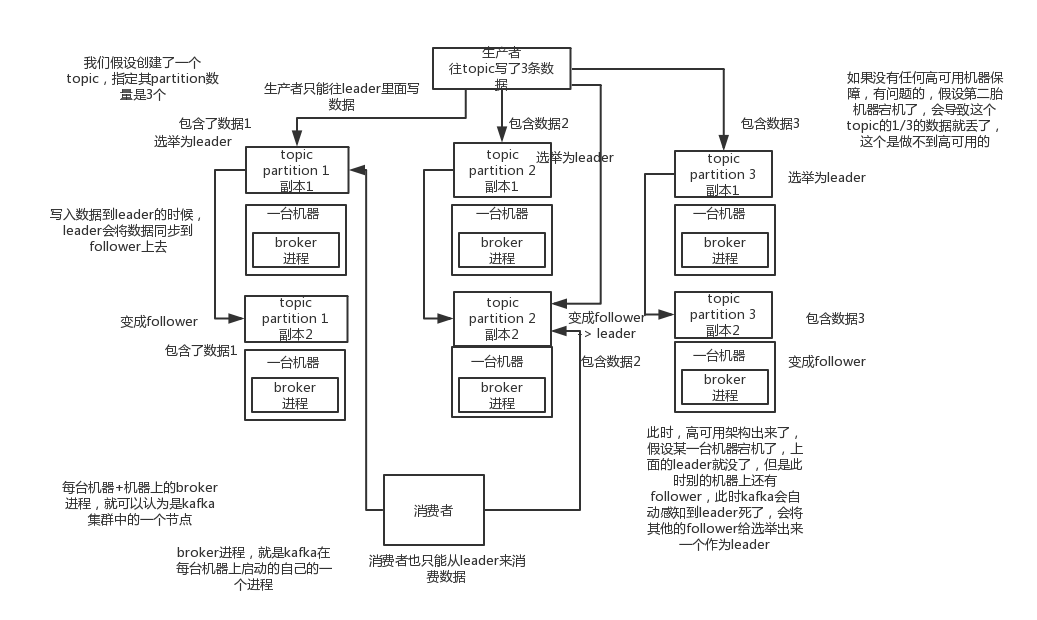
2)kafka的高可用性:
kafka的基本架构:多个broker节点组成,创建一个topic可以被划分为多个partition,每个partition存放在不同的broker上,存放一部分数据,这就是天然的分布式消息队列;kafka在0.8版本之后,提供了HA机制,每个partition数据都会同步到其他机器上,形成自己的多个replica副本,然后所有的replica会选举出一个leader和生产者和消费者打交道,这种HA机制可以提高容错性和高可用性。
2.MQ是如何保证消息的幂等性?
1)MQ幂等性出现的情况:a.生产者发送消息到mq,mq返回给生产者ack的时候突然网络中断,生产者认为消息未发送成功(实际上已经发送到mq了),当网络正常之后,生产者会重新再发一次,这就会导致mq重复发送了消息;b.消费者在消费处理完消息后,在给mq返回ack时候网络中断,mq未收到确认信息,当网络正常之后,mq会继续重新发送给其他消费者,导致消息的重复消费。
2)MQ幂等的解决方案:a.mq在接收生产者传来的消息将消息落地时,为每一条消息生成inner-msg-id(全局唯一、与业务无关),作为去重和幂等的依据,保证只有1条消息落到MQ-Server的DB中;b.消费者在接收和处理mq发送来的消息时,业务消息体中必须要有一个biz-id(同一个业务场景全局唯一、对MQ透明、由消费方负责判重),作为去重和幂等的依据,数据落地消费者数据库,处理消费信息时先判断是否已处理。
3.MQ是如何保证消息的可靠性传输?
1)rabbitMq的可靠性传输:
a.生产者丢数据时,可设置开启confirm模式,这样每次写消息时都会被分配到唯一的id,mq通过这个id判断是否被写入(返回ack说明写入成功,返回nack说明未写入成功,可以重发),该种模式是异步的(有一种事务同步机制,即使用rabbitMq提供事务的开启channel.txSelect、提交channel.txCommit、回滚channel.txRollback,不推荐);
b.rabbitMq自己丢失数据,那么就需要开启rabbitMq的持久化,将消息写入磁盘中,步骤如下:设置队列queue的持久化(channel.queue_declare(queue='hello', durable=True))和消息的持久化(channel.basic_publish(exchange='',routing_key='hello',body='hello',properties=pika.BasicProperties(delivery_mode=2)));
c.消费者丢失数据时,可以使用rabbitMq提供的ack机制,如果消费者未返回信息,那么mq重新发送信息,值需要保证消费处理的幂等即可。
2)kafka的可靠性输入:
a.生产者丢数据,要求配置:acks=all,保证每条数据写入replica之后才认为是成功,retries=MAX,写入失败无限重试;
b.kafka丢失数据,要求配置:生产者配置好;topic 设置 replication.factor 参数值必须大于1,保证每个partition必须至少有2个副本;Kafka 服务端设置 min.insync.replicas 参数值必须大于1,保证1个leader必须有一个follower与自己保持联系;
c.消费者丢失数据,同rabbitMq。
4.MQ是如何保证消息被消费的顺序性?
1)rabbitMq的顺序性:拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点;或者就一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理;
2)kafka的顺序性:写入一个partition中的数据一定是有序的,生产者在写的时候 ,可以指定一个key,比如指定订单id作为key,这个订单相关数据一定会被分发到一个partition中去。消费者从partition中取出数据的时候也一定是有序的,把每个数据放入对应的一个内存队列,一个partition中有几条相关数据就用几个内存队列,消费者开启多个线程,每个线程处理一个内存队列。