按照旧例,先安利一下主要作者:一扶苏一 以及扶苏一直挂念的——银临姐姐:银临_百度百科 (滑稽)
好哒,现在步入正题:
先看第一题:


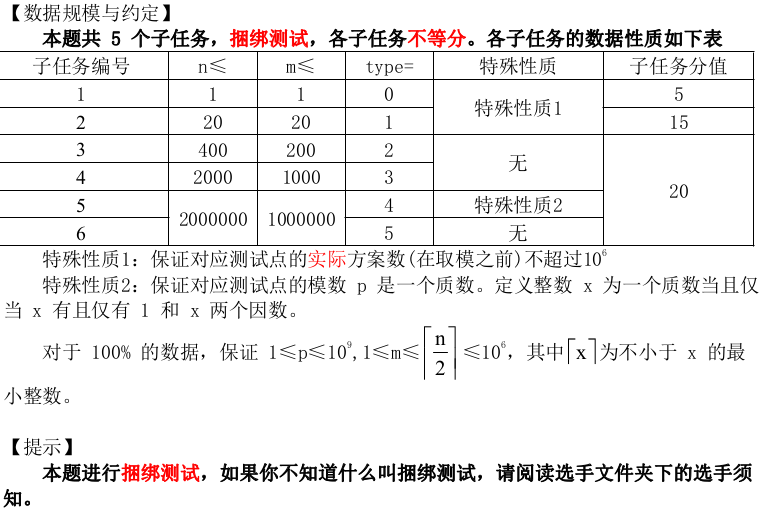
题解:
在NOIP范围内,看到“求方案数”,就说明这个题是一个计数问题。数据范围小的时候一般用DP/递推,数据范围大了的话一般就是数学问题的(组合数学警告)。如果这道题用DP的话,状态即为:dp[i][j]表示第i盆花摆到第j个空的方案数。状态转移方程即为:dp[i][j]=∑dp[i-1][k],k=2*(i-2)+1,...,j-2;时间复杂度为O(n2m)。最终答案即为dp[i]的所有情况再乘上A(m,m)(因为花的顺序也会影响到方案数)。
考虑优化,发现dp[i][j]是由若干个连续的dp[i-1]的和得到,自然想到了前缀和优化,设s[i][j]=dp[i][1]+dp[i][2]+...+dp[i][j],则状态转移方程可以改写为dp[i][j]=s[i-1][j-2]-s[i-1][2*(i-2)],这样就可以用O(1)的复杂度推出来状态了。而s则可在每次dp[i]都算完后推出,时间复杂度O(m),那么整体的时间复杂度即为O(nm)。发现状态的复杂度就是O(nm),显然该DP的复杂度优化下限就是O(nm)(因为复杂度不可能比状态数还少啊),即DP已经优化到尽头了,然而并不足以解出这道题,所以接下来还得考虑一下用数学怎么做了。
我们将m盆花放在n个位置中,还有n-m个空位置,由于m盆花要求互不相邻,所以我们要将这m盆花插到n-m个空位置隔出来的n-m+1个空中(之间的n-m-1个空,还有两边的两个空)。看下图感性理解一下吧(滑稽):

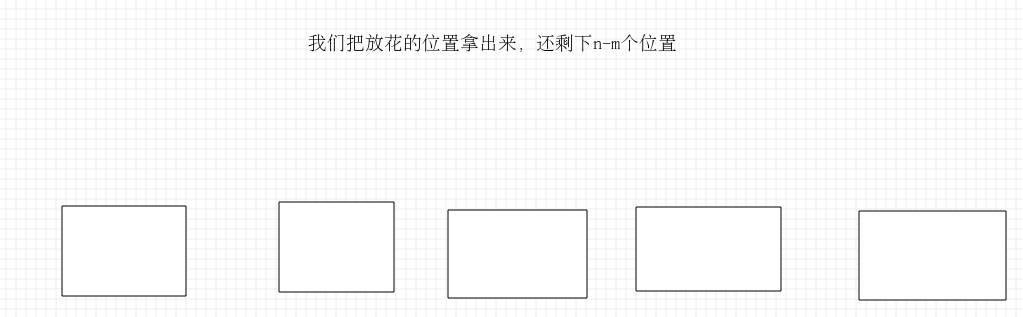

所以最后的答案就是C(n-m+1,m)*A(m,m)=A(n-m+1,m),别忘了计算过程中间及最后要取模。
思路就讲完啦,看标程吧:
1 #include <stdio.h> 2 3 int main() { 4 freopen("ilove.in", "r", stdin); 5 freopen("ilove.out", "w", stdout); 6 int I, love, yin, lin;//??? 7 scanf("%d%d%d%d", &I, &love, &yin, &lin); 8 love = love - yin + 1; 9 int ans = 1; 10 for (int i = love - yin + 1; i <= love; ++i) { 11 ans = 1ll * ans * i % lin; 12 } 13 printf("%d ", ans); 14 return 0; 15 }
(看到这么短的代码,再看自己考试时2个小时半低效率半走神地推导DP,呵呵~~)
再看第二题:


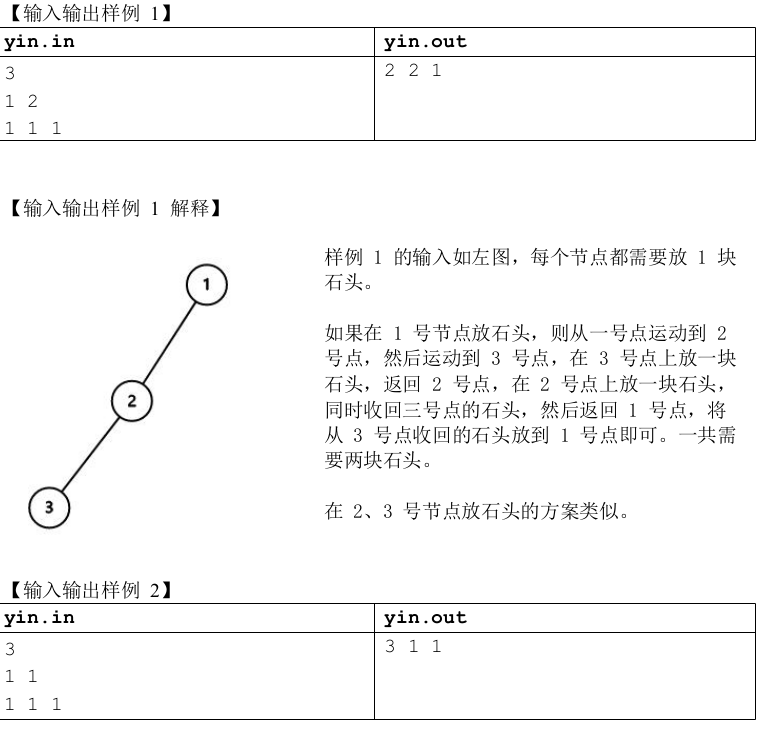

题解:注意到扶苏行走的规则是:“当扶苏在点u时,扶苏要么在u的孩子中选择一个没有到达过的点v并行走到v,要么选择回到u的家长节点”,这一规则导致扶苏必须一次性的把一个点的子树全部走完后才能从这个点出去,否则就不能再下到子树中没有走过的点了,导致有点没有放上石子,不和题意。由此就知道应从儿子推向父亲的策略。
同时易知一个省石子的策略是将一个节点的儿子都放上石子后,给这个节点放上石子,然后再把他儿子上的所有石子拿走,去向别的节点放石子。同时还发现,一个节点u的一个儿子v放完石子后可以将这个儿子的儿子们上的石子都拿走,去给这个v的兄弟节点放石子,显然这提醒我们呢,很可能要制定一个合理的贪心顺序去依次处理一个节点的所有儿子。
设每个节点u的答案为ansu,走完节点 u 的所有孩子 v 所需要的总石子数 c u;走完所有孩子后,剩下的石子(也就是cu的减去儿子们总的w)为 ret(rest缩写),当 ret ≥ w u的时候,直接用 ret 放下 要在u 放上的石子,于是在节点 u 的放石子总花费就是 c u ,越小越好;当 ret < w u 的时候,用剩下的石子放在 u 上,然后再额外放上去一些石子,这样做的花费是 w u +∑w v,显然是最小的花费,考虑当 c u 越小 ret 才越小,c u 取最小时显然能取到最优情况。综上,可以尽可能使 c u 减小,来达到最优解。这就是贪心所要达到的目的。
那么问题变成了:
有 x 个商品,购买第 i 个物品需要手里有 ans i 元钱,花费 w i 元。求一个顺序
使得购买所有商品所需要的钱数最少。
这个问题的最最优顺序是按照 ans i -w i 不升序购买,也就是差值越大越要先买。
考虑证明:
设有两个物品 i,j,设 a i =ans i -w i ,a j =ans j -w j 。且 a i >a j 。考虑先买 i 再买 j 的
花费是 max(ans i , w i +ans j ) ----1式,同理先买 j 的花费是 max(ans j , w j +ans i )----2式 。
提出 w,则 1式=w i +max(a i ,ans j ),2式=w j +max(a j ,ans i )=w j +max(a j ,a i +w i )=w j +a i +w i 。
考虑 1 式的 max 如果取前面一项,则 1式=w i +a i <2式,如果取后面一项则 1
=w i +ans j =w i +a j +w j <2,于是无论怎么取,1式恒小于2式,于是先买 i 更优。数学归
纳可得按照 ans i -w i 不升序购买最优。于是按照这个顺序,对儿子排一遍序即可。
见标程:
1 #include <cstdio> 2 #include <vector> 3 #include <algorithm> 4 5 const int maxn = 100010; 6 7 int n; 8 int MU[maxn], ans[maxn]; 9 std::vector<int>son[maxn];//动态数组 10 11 void dfs(const int u); 12 bool cmp(const int &_a, const int &_b); 13 14 int main() { 15 freopen("yin.in", "r", stdin);//文件操作 16 freopen("yin.out", "w", stdout); 17 scanf("%d", &n); 18 for (int i = 2, x; i <= n; ++i) { 19 scanf("%d", &x); 20 son[x].push_back(i); 21 } 22 for (int i = 1; i <= n; ++i) { 23 scanf("%d", MU + i); 24 } 25 dfs(1); 26 for (int i = 1; i < n; ++i) { 27 printf("%d ", ans[i]); 28 } 29 printf("%d ", ans[n]); 30 return 0; 31 } 32 33 void dfs(const int u) { 34 for (auto v : son[u])//等价于for(int v=0;v<son[u];v++) 35 //注意动态数组下标从0开始 36 { 37 dfs(v);//深搜每个儿子 38 } 39 std::sort(son[u].begin(), son[u].end(), cmp); 40 int _ret = 0; 41 for (auto v : son[u]) { 42 if (_ret >= ans[v]) { 43 _ret -= ans[v]; 44 } else { 45 ans[u] += ans[v] - _ret; 46 _ret = ans[v] - MU[v]; 47 } 48 } 49 ans[u] += std::max(0, MU[u] - _ret); 50 } 51 52 inline bool cmp(const int &_a, const int &_b) { 53 return (ans[_a] - MU[_a]) > (ans[_b] - MU[_b]);//剩下多的在前面 54 }
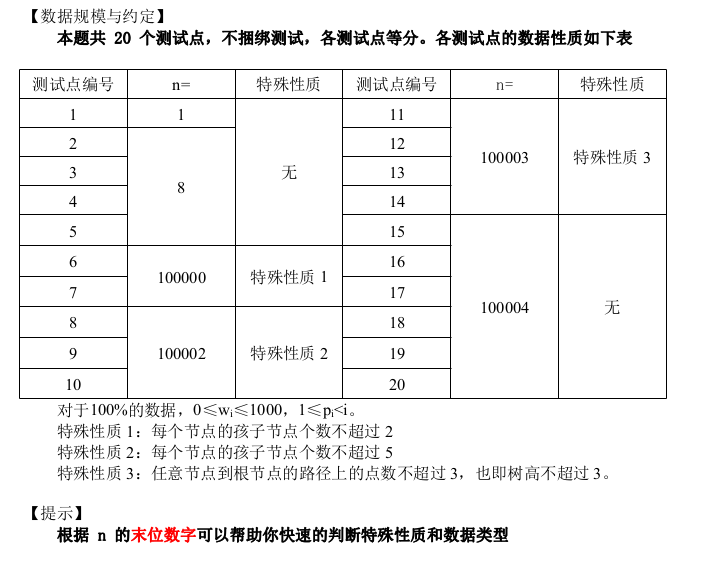
终于到最后一题啦:



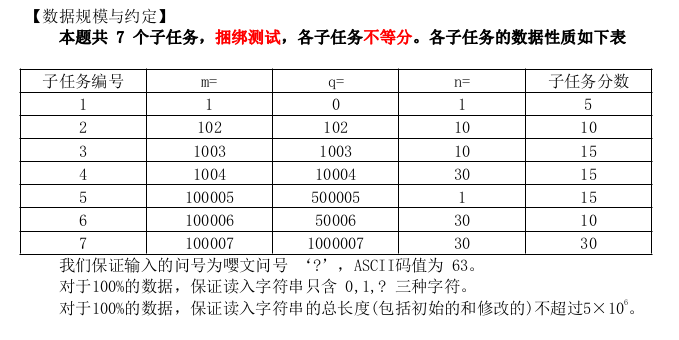
题解:因为是要求字符串k去匹配一个区间里的所有字符串,所以可以记录一下一个区间中的字符串每位的情况:是否全为0或全为1。对于问号,既可以把他看作0,也可以把他看作1。我们一位一位从前往后看,设当前k的可行情况有ans种。如果在这个区间里当前第w位既可以全是1又可以全是0(即全是问号),那么ans<<=1(相当与ans*=2。为什么要*2?因为k的第w位有两种情况:0或1,由乘法原理知要*2。)若全是0,则ans不变;若全是1,则ans也不变;若既一定有1又一定有0,显然k是不能匹配他们了,就让ans=0,直接break掉。
见到大数据的区间维护与询问,而且维护的信息不是常规维护的信息,就该想到线段数这一数据结构了。(基本查询贼多的题都是数据结构题 ————by 一扶苏一)对每一位,我们都建一个线段数进行维护,由于最多只需建30个不大的线段数,并不会爆空间。(头一次建这么多线段数,真是有点吓人)时间复杂度O(nq logm)(世界上没有什么事情是开一棵线段树不能解决的。如果有,那就开 30 棵——by 一扶苏 一)(但是开30棵线段树还是会TLE的说)。对于最后一个子任务,还是需要再优化一下。注意到n最大30,可以考虑状压。对每个线段树节点可以维护一个longlong型,long long 共有64个二进制位,每2个二进制位去确定一个字符串位,01代表确定全是0,10代表确定全是1,11代表确定既可以是1又可以是0,00代表都不可以。线段树维护时只要按位与就行,维护完毕后在O(n)扫一遍long long 出答案。时间复杂度O(nq + qlogm),就能AC这个题了。思路这么清楚,想必代码也能打出来了吧。把想法用代码实现出来,正是一个合格的OIer要锻炼的品质哟~。
最后在总结一下考试的小技巧:
有关大样例输出的比较,用肉眼看真是麻烦,有没有能让计算机来告诉我们是否一样的方法?有!只要在相应目录下按shift加鼠标右键,打开命令行,用fc命令对比两个文件就行了。有时fc不靠谱,就要自己写一个比较程序。
不要眼高手低,部分分能拿下来也是很好的。也就是说,对于不同的数据范围,我们可以应用不同的算法来拿分。为了避免重名的麻烦,可以定义若干个命名空间,还方便赋予意义。
最后就是交程序前一定要把注释去掉后再编译一遍,确保加文件后不会有因手残RE等被广大OIer痛恨的问题。