Python_网络爬虫——京东商城商品列表
最近在拓展自己知识面,想学习一下其他的编程语言,处于多方的考虑最终选择了
Python,Python从发布之初就以庞大的用户集群占据了编程的一席之地,python用最少的语言完成最多的工作量,丰富的代码库供学习使用。现行的python涉及了:大数据、机器学习、web开发、人工智能等众多方面
什么是网络爬虫
网络爬虫是一个从web资源获取所需要数据的过程,即直接从web资源获取所需的信息,而不是使用网站提供的线程的API访问接口。
网络爬虫也称为网页数据资源获取,是一种数据获取技术,通过该技术我们可以直接从网站的HTML获取所需的数据其中包含与web资源进行通讯、剖解文件获取所需数据整理成信息,及转换成所需的数据格式。
简单一点:就是通过网站的web界面获取我们想要的数据,并以一定的格式存储。每一次获取就是请求一次网页资源的过程,根据返回网页的信息,通过解析工具找到我们想要的数据信息,并加以保存便于后续使用。
网络爬虫一般分为下面几步:
- 确定访问站点地址
- 分析HTML找到目标标签
- 发送请求获取资源
- 使用工具剖析HTML页面
- 获取所需资源
- 保存获取资源
网络爬虫可以用来做什么
网络爬虫用的方面很多,比如做大数据分析网络数据源的获取,收集一些文章,为了满足内心猎奇现在一些美女写真等。
网络爬虫有一定的版权纠纷问题,所以开发者要有一定的判断意识把握住心中的底线,如果出现越界行为只有法律来规定你的底线了。
网络爬虫实战案例——获取京东商城列表
- 确定请求网址
本次实战案例为京东商城查询列表
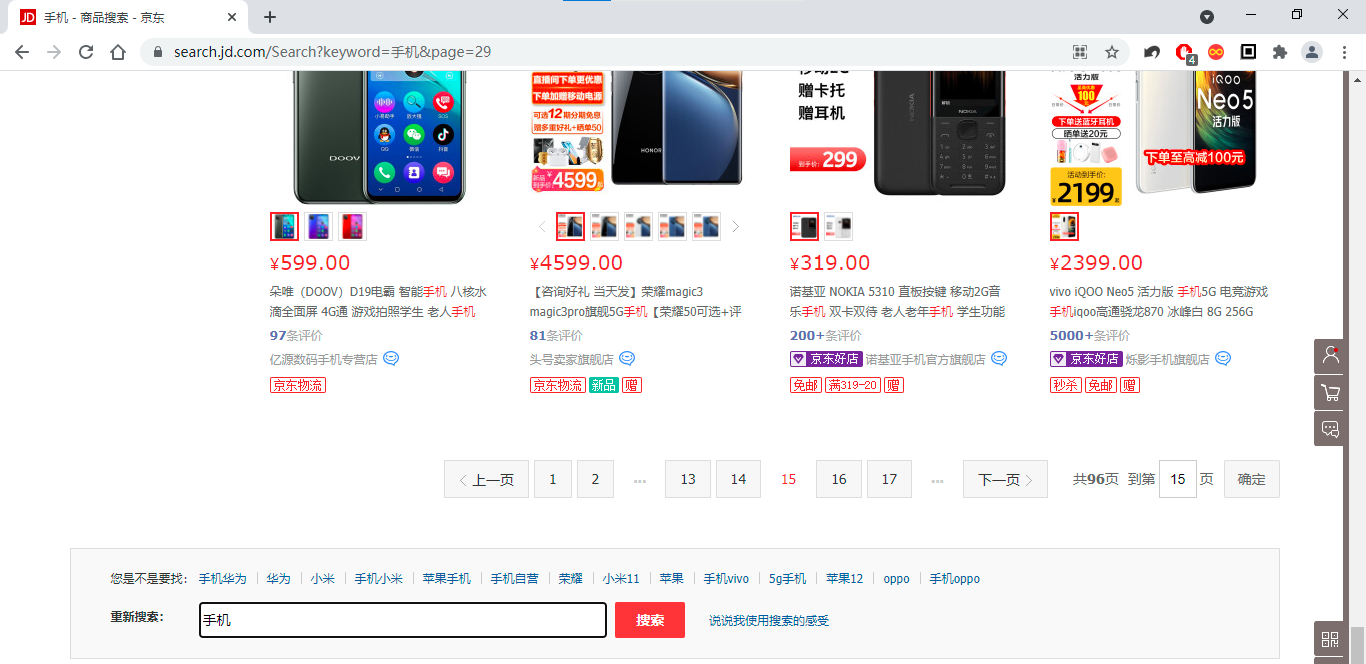
分析网站地址 url:https://search.jd.com/Search?keyword=手机&page=1
可以从网站地址中分析要传入的参数:
keyword:搜索关键字
page:页码
每页的产品数:30
这里在京东商城页码上有一个迷惑行为:在浏览器上切换页码是page的数为page*2-1的数字,实则每页显示用户浏览到底部时又加载了一页,故在浏览器上网页资源上显得有 60 条商品,每页的实际大小为30
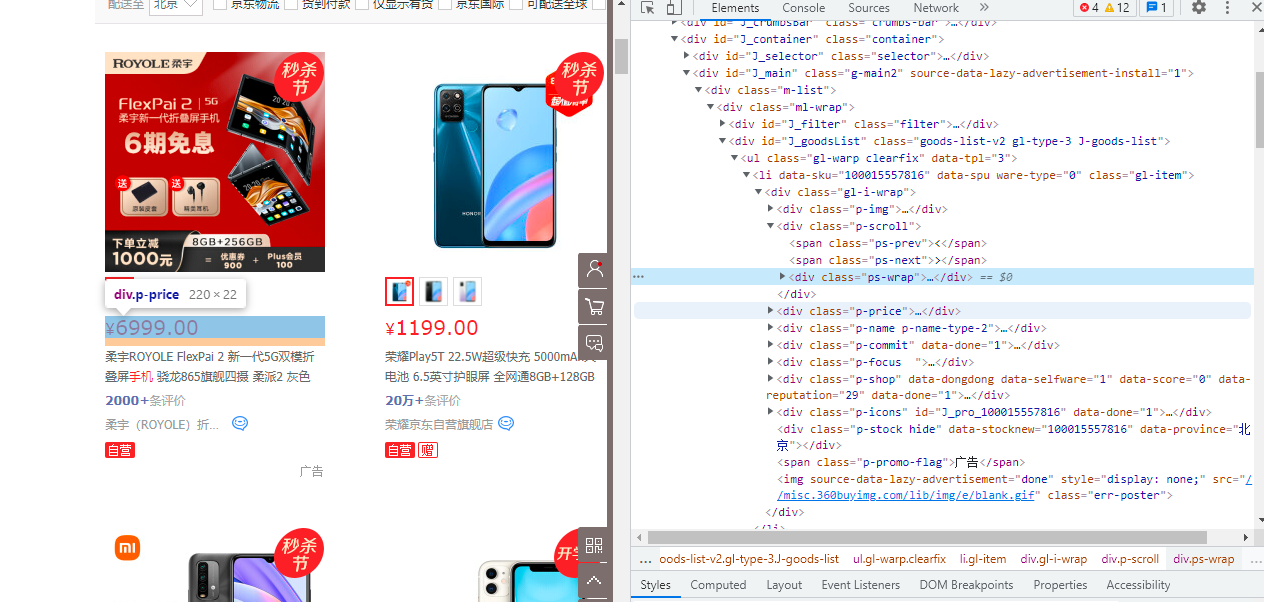
- 分析网站HTML找到目标标签
利用谷歌浏览器的F12或鼠标右键检查标签,找到之际想要的标签
程序需要引入的包
import requests as rq
from bs4 import BeautifulSoup as bfs
import json
import time
- 发送请求获取资源
根据参数编写生成产品列表方法
def get_urls(num):
URL = "https://search.jd.com/Search"
Param="?keyword=手机&page={}"
return [URL+Param.format(index) for index in range(1,num+1)]
发送请求,为请求方法添加请求头
#访问网址
def get_requests(url):
header={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
}
return rq.get(url,headers=header)
- 使用工具剖析HTML页面
将请求信息转义需要格式
def get_soup(r):
if r.status_code ==rq.codes.ok:
soup=bfs(r.text,"lxml")
else:
print("网络请求失败...")
soup=None
return soup
- 获取所需资源
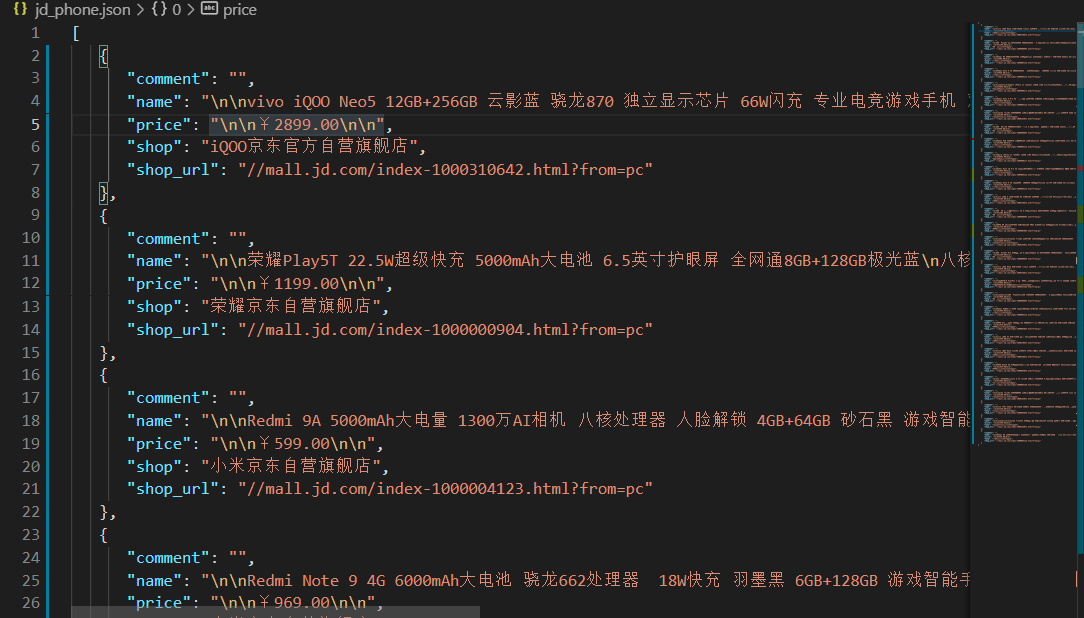
该页面中查找需要信息,商品列表中的名称、价格、店铺名称、店铺链接、评论数
#获取商品信息
def get_goods(soup):
goods=[]
if soup !=None:
tab_div=soup.find('div',id="J_goodsList")
tab_goods=tab_div.find_all('div',class_="gl-i-wrap")
for good in tab_goods:
name=good.find('div',class_="p-name").text
price=good.find('div',class_="p-price").text
comment=good.find('div',class_="p-commit").find('strong').select_one("a").text
shop=good.find('div',class_="p-shop").find('span').find('a').text
shop_url=good.find('div',class_="p-shop").find('span').find('a')['href']
goods.append({"name":name,"price":price,"comment":comment,"shop":shop,"shop_url":shop_url})
return goods
- 保存获取资源
保存文件格式为json格式,这里可以替换成保存其他格式,或保存到业务库中
def save_to_json(goods,file):
with open(file,"w",encoding="utf-8") as fp:
json.dump(goods,fp,indent=2,sort_keys=True,ensure_ascii=False)
程序主方法,将上面各功能组合在一起。实现解析全站
if __name__=="__main__":
goods=[]
a=0
for url in get_urls(30):
a+=1
print("当前访问页码{},网址为:{}".format(a,url))
response=get_requests(url)
soup=get_soup(response)
page_goods= get_goods(soup)
goods+=page_goods
print("等待10秒进入下一页...")
time.sleep(10)
for good in goods:
print(good)
save_to_json(goods,"jd_phone2.json")
运行程序,查看保存文件是否符合格式