Neural Collaborative Subspace Clustering(ICML 2019)
Abastract:
l discovers clusters of data points drawn from a union of low dimensional subspaces
l runs without the aid of spectral clustering, This makes our algorithm one of the kinds that can gracefully scale to large datasets
l At its heart, our neural model benefits from a classifier which determines whether a pair of points lies on the same subspace or not
Essential to our model is the construction of two affinity matrices, one from the classifier and the other from a notion of subspace self-expressiveness, to supervise training in a collaborative scheme.
Related work
l Subspace clustering 大数据和非线性的解决方法
Subspace Clustering (aim to cluster data points drawn from a union of low-dimensional subspaces in an unsupervised manner)
在子空间上应用谱聚类的关键挑战之一是构造合适的相似矩阵。我们可以根据相似矩阵的构造方法将算法分为三大类:基于因子分解的方法,基于模型的方法,基于自我表达的方法,其基本思想是一个点可以用同一子空间中其他点的线性组合表示。与其他方法相比,该方法具有以下几个优点:对噪声和异常值具有更强的鲁棒性;计算复杂度不随子空间的数目及其维数呈指数增长;它也利用非本地信息,而不需要指定邻域的大小
针对数据点不是线性子空间而是非线性子空间的问题,提出了若干解决方案。核稀疏子空间聚类(KSSC)得益于预定义的Kernel函数,如多项式或径向基函数(RBF),将问题投射到高维(可能是无限的)可再生Kernel Hilbert空间中。然而,如何为不同的数据集选择合适的核函数仍然不清楚,也不能保证由核技巧生成的特征空间非常适合于线性子空间聚类。
最近研究:DSC:解决了非线性问题但是还是使用了谱聚类在大数据集上不适用。
The SSC-Orthogonal Matching Pursuit:用OMP算法代替大规模的凸优化过程来表示关联矩阵。但是,为了加快计算速度,SSC-OMP牺牲了clustering performance,当数据点数量非常大时,它仍然可能失败
k-Subspace Clustering Networks:可以将子空间聚类技术应用在大数据集上,避免构造相似矩阵避免使用谱聚类,提出iterative method of k-subspace clustering into a deep structure 虽然k-SCN开发了两种方法来更新子空间和网络,但它与迭代方法有相同的缺点,例如,它需要良好的初始化,并且对于异常值似乎很脆弱
l In this paper:特点:非线性、可伸缩
我们首先将子空间聚类表示为一个分类问题,然后将谱聚类步骤从计算中去除。我们的神经模型由两个模块组成,一个用于分类,一个用于相似度学习。这两个模块在学习过程中相互协作。在训练过程和每次迭代中,我们使用子空间自表达生成的相似矩阵来监督分类部分计算的相似矩阵。同时,利用分类部分提高自表达能力,通过协同优化构建更好的相似矩阵。
Model fitting
In learning theory, distinguishing outliers and noisy samples from clean ones to facilitate training is an active research topic
例如:
经典的做法是Random Sample Consensus: fitting a model to a cloud of points corrupted by noise
Curriculum Learning:开始从简单的样本中学习模型,并逐步使模型适应更复杂的样本
Ensemble Learning:尝试通过训练不同的模型来提高机器学习算法的性能,然后将它们的预测集合起来
distilling knowledge: learned from large deep learning models can be used to supervise a smaller model
l Deep clustering
许多研究论文都探索了利用深度神经网络进行聚类,例如:
DEC: pre-train a stacked auto-encoder, and fine-tune the encoder with a regularizer based on the student-t distribution to achieve cluster-friendly embeddings. 缺点是,DEC对网络结构和初始化很敏感
各种形式的GAN:
Info-GAN和ClusterGAN等算法进行聚类,都是为了增强潜在空间的判别特征,同时生成和聚类图像
The Deep Adaptive image Clustering (DAC):
使用全卷积神经网络作为初始化进行自监督学习,取得了显著的效果。但对网络结构的敏感
In this paper:
通过图像分类和子空间关联学习两个模块的协同学习,将子空间聚类问题转化为分类问题。我们没有对整个数据集进行谱聚类,而是以随机的方式训练模型,从而得到一个可伸缩的子空间聚类。
Proposed Method
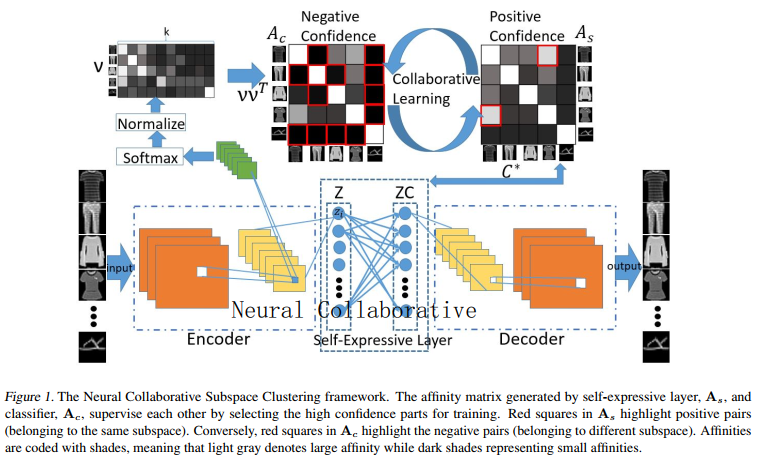
To design a scalable SC algorithm, our idea is to identify whether a pair of points lies on the same subspace or not 在获得这些知识之后(对于足够大的一组对),一个深度模型可以优化它的权重来最大化这些关系(是否位于子空间)。这可以很好地转换为一个二元分类问题。
由于没有标签信息我们使用两个置信度图作为监督信号
l Binary classification
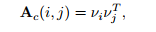
We propose to use a multi-class classifier which consists of a few convolutional layers (with non-linear rectifiers) and a softmax output layer然后将其转化为基于相似性的神经协同子空间聚类
通过分类器得到样本的i、j的one-hot 分类向量,两向量相乘得到两样本的相似度,如此,我们就学到了相似矩阵,因为分类器最后一层为softmax层(得到属于每一类的概率向量长度为1),所以可以将解释为、的余弦相似度介于[0,1]
l Self-Expressiveness affinity
概念:从线性子空间中提取的一个数据点xi可以由同一子空间中其他点的线性组合表示将所有点叠加到数据矩阵X的列中,其自表达性可以简单地描述为X = XC,其中C为系数矩阵。

为了解决子空间的非线性映射,一种解决方式是使用全卷积网络将data X映射到 Z, 并将自表达性转化为一个线性层(无非线性激活和偏置参数),称为自表达层 ;在Z空间中子空间表达还是线性的
但因为样本X做了非线性映射,所以在 X 空间,样本属于非线性子空间映射。这使得我们可以利用自编码器端对端地学习到子空间相似度,C为自表达权值矩阵
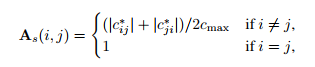
l Collaborative learning
协作学习的目的是充分利用不同模块的优势,分类模块倾向于提取更抽象、更具鉴别性的特征,而自表达模块更侧重于捕捉数据样本之间的成对相关性;通过分类模块计算的两样本相似度接近于0 说明有很大地可能两样本属于不同子空间;而自表达模块计算出的两样本相似度接近于1 表明两样本有可能属于同一子空间。所以我们用来增强negtive ,用来增强postive关系;u、l为阈值

l Loss function
网络由四个主要部分组成:(i)一个卷积编码器,它将输入数据X映射为一个潜在的表示Z;(ii)通过权值C学习子空间相似矩阵线性自表达层;(iii)将数据映射到自表达层之后的卷积解码器,即,ZC,回到输入空间;(iv)输出k维预测向量的多类分类器,利用k维预测向量构造分类相似矩阵。
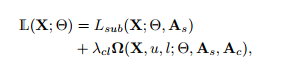
总损失:collaborative learning loss + subspace learning loss
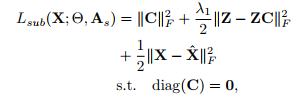
subspace learning loss=自表达损失+重构误差+惩罚项
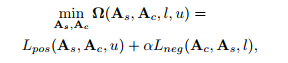
collaborative learning loss
训练结束后可以用分类层结果作为最终聚类结果,不需要做谱聚类,所以在大数据集适用(不过还是生成相似度矩阵,内存消耗没有避免)
Optimization and training
1.通过最小化重构误差对自编码进行预训练,从而获得良好的子空间聚类初始化效果
2.基于子空间的独立性假设,自表达矩阵具有块对角结构,为了说明这一点,我们确保潜在空间(Z)的维数大于(子空间固有维数)×(簇数),对图像进行降采样,同时增加图层上的通道数,保持潜在空间维数较大。
3.由于我们已经对自动编码器进行了预训练,所以在执行协作学习时,我们在自动编码器中使用更小的学习率
4. 我们采用了三阶段训练策略:首先,利用subspace learning loss中的损耗对自编码器和自表达层进行训练,更新;其次,我们训练分类器最小化collaborative learning loss。(5);第三,我们对整个网络进行联合训练,使总损失最小化。