- BeautifulSoul
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
通过定位 HTML 标签来格式化和组织复杂的网络信息,用简单易用的 Python 对象为我们展现 XML 结构信息。 它包含三个对象:
- BeautifulSoup
- Tag
- NavigableString
使用方法:
1>导入bs4库和urllib库(用于打开html网页):
from bs4 import BeautifulSoup from urllib.request import urlopen
2>创建一个BeautifulSoup对象:
from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html") bsObj = BeautifulSoup(html)
其中,http://www.pythonscraping.com/pages/page3.html 是一个简单的用于测试爬虫程序的网页:
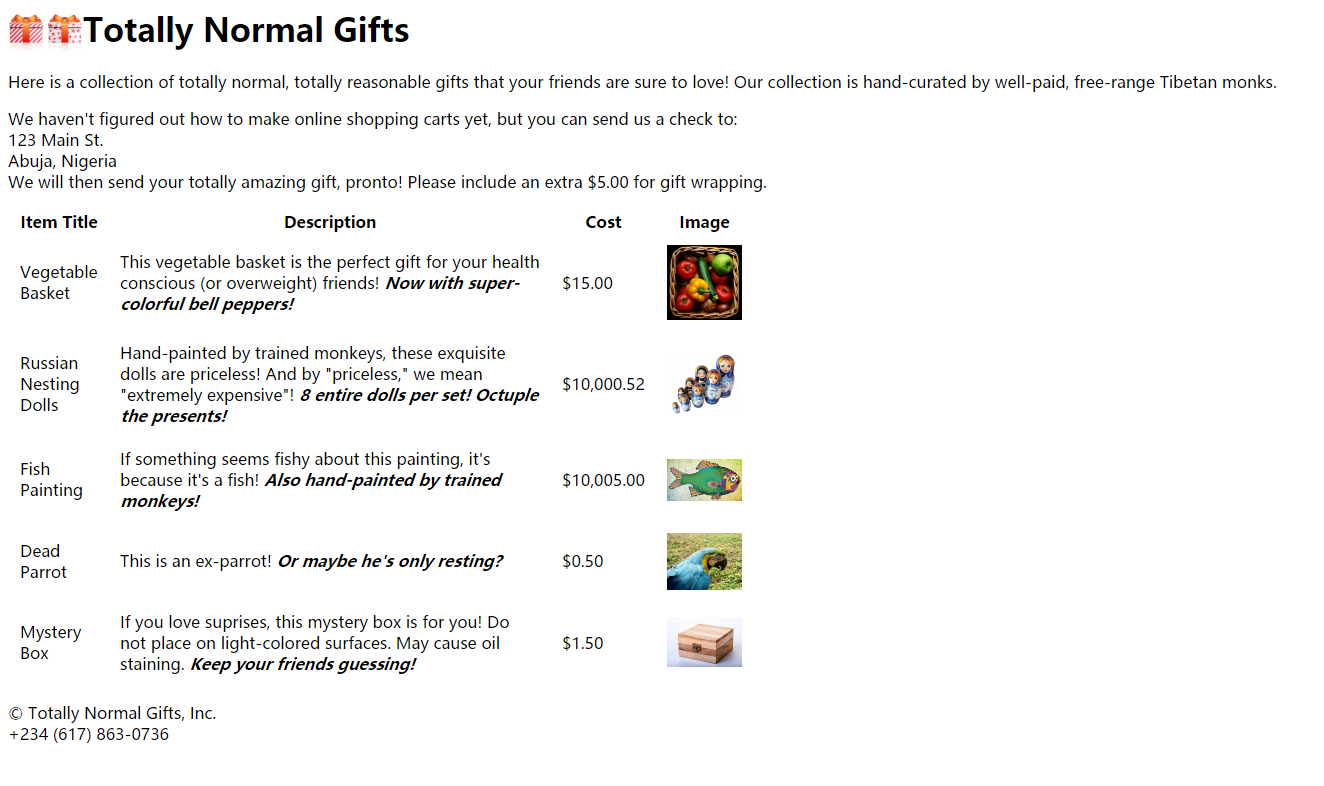
3>.find() 与 .findAll() 函数
例如:nameList = bsObj.findAll("span", {"class":"green"}) ;抽取所有属性为 green的span标签内的文字,find()和findAll()是最常用的两个函数,借助它们,利用标签的不同属性轻松地过滤HTML页面,查找需要的标签组或者标签。
用法:
- findAll(tag, attributes, recursive, text, limit, keywords)
- find(tag, attributes, recursive, text, keywords)
多数情况下可能只需要用到前两个参数,tag和attributes,attributes指HTML标签的属性,递归参数 recursive 是一个布尔变量。你想抓取 HTML 文档标签结构里多少层的信息?如果recursive 设置为 True, findAll 就会根据你的要求去查找标签参数的所有子标签,以及子标签的子标签。如果 recursive 设置为 False, findAll 就只查找文档的一级标签。 findAll默认是支持递归查找的( recursive 默认值是 True);一般情况下这个参数不需要设置,除非你真正了解自己需要哪些信息,而且抓取速度非常重要,那时你可以设置递归参数
text参数用于匹配标签的文本内容,如:nameList = bsObj.findAll(text="the prince")
keword可以选择具有制定属性的标签。
2. 第一个爬虫程序:
先贴代码:
from urllib.request import urlopen from urllib.error import HTTPError from bs4 import BeautifulSoup def getTitle(url): try: html = urlopen(url) except HTTPError as e: return None try: bsObj = BeautifulSoup(html.read(),'lxml') title = bsObj.body.h1 except AttributeError as e: return None return title title = getTitle("http://www.pythonscraping.com/pages/page1.html") if title == None: print("Title could not be found") else: print(title)
输出目标网页内title标签内的文本:<h1>An Interesting Title</h1>,getTitle()函数返回网页的标题,如果获取网页遇到问题就返回一个 None 对象。 如果服务器不存在, html 就是一个 None 对象,html.read() 就会抛出 AttributeError 。