Coursera课程《Using Python to Access Web Data》 密歇根大学
Week5 Web Services and XML
13.1 Data on the Web
在网络上我们需要用一种固定的模板进行交流,python将我们的内容serialize成这种模板,然后再de-serialize让另外一种语言读懂。
现在有两种交流模板:XML和JSON。
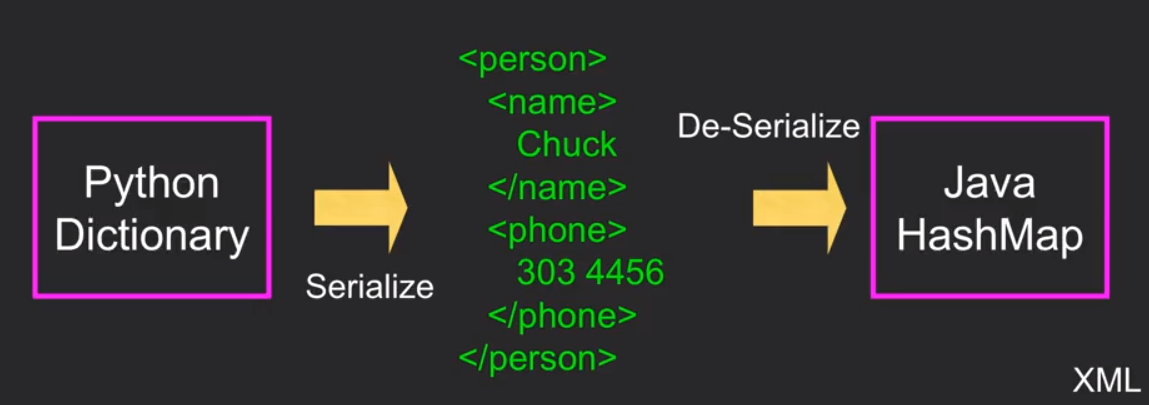

13.2 Extensible Markup Language(XML)
XML也就是可扩展标记语言(Extensible Markup Language),很类似HTML。
<people>
<person>
<name>Chuck</name>
<phone>303 4456</phone>
</person>
<person>
<name>Noah</name>
<phone>622 7421</phone>
</person>
</people>
和HTML一样,它有start tag和end tag。
而<name>Chuck</name>这种叫Simple Element,<person></person>这种叫Complex Element。

而对于XML来说,空格和缩进并不是很有关系。缩进仅仅是为了更好的阅读。
XML的术语
- 标签(Tag)表示元素的起始。
- 属性(Attribute)- 在XML的开放标签中的关键词或值
- Serialize/De-Serialize - 将数据从一种程序转换到一种通用模板中的过程
XML是树形结构的。
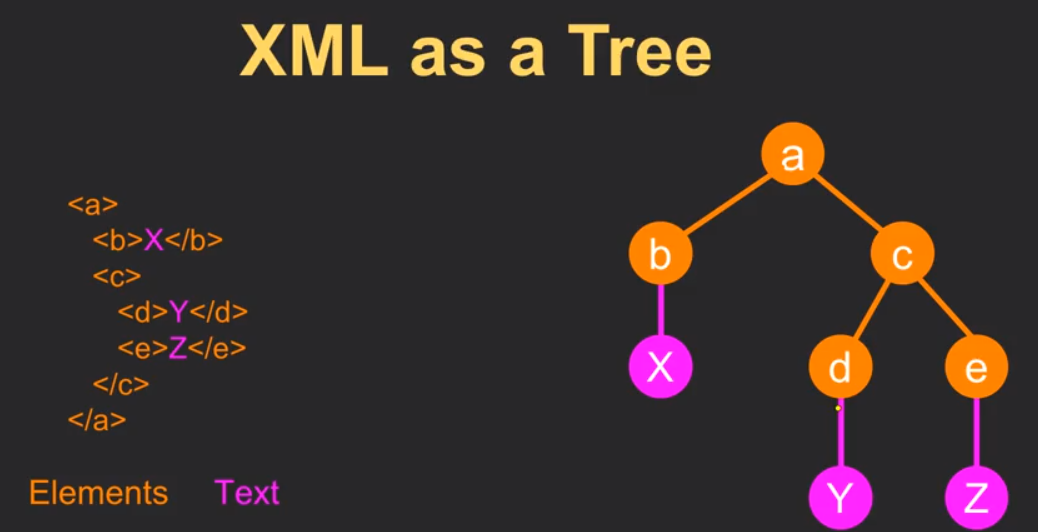
所以我们如果要把XML解析为路径。上图中的结果就是。
/a/b为X,/a/c/d为Y,/a/c/e为Z。
13.3 XML Schema
XML纲要描述了一个合法的XML文档的模板。

目前有很多种XML纲要语言,比如说Document Type Definition(DTD), Standard Generalized Markup Language(ISO 8879:1986 SGML), XML Schema from W3C - (XSD)。
以下就是XSD的结构。

XSD的限制。

比如说上图的蓝色部分,minOccurs="1" maxOccurs="1"意思就是这个tag只能出现一次,而且必须出现一次。而橙色部分minOccurs="0" maxOccurs="10"也就是说,这个tag可以出现大于等于0小于等于10次。
XSD的数据类型有string, date, date Time, decimal, integer五种类型。

13.4 Parsing XML
import xml.etree.ElementTree as ET
data = '''<person>
<name>Chuck</name>
<phone type="int1">
+1 734 303 4456
</phone>
<email hide="yes"/>
</person>'''
tree = ET.fromstring(data)
print('Name:', tree.find('name').text)
print('Attr:', tree.find('email').get('hide'))
fromstring()这个函数是把XML组织成树状结构,方便后面使用find()查找。
以下是更复杂的一个XML文档情况。
import xml.etree.ElementTree as ET
input = '''<stuff>
<users>
<user x="2">
<id>001</id>
<name>Chuck</name>
</user>
<user x="7">
<id>009</id>
<name>Brent</name>
</user>
</users>
</stuff>'''
stuff = ET.fromstring(input)
lst = stuff.findall('users/user')
print('User count:', len(lst))
for item in lst:
print('Name', item.find('name').text)
print('Id', item.find('id').text)
print('Attribute', item.get("x"))
作业代码
import urllib.request, urllib.parse, urllib.error
import xml.etree.ElementTree as ET
url = input('Enter location: ')
print('Retrieving', url)
uh = urllib.request.urlopen(url)
data = uh.read()
print('Retrieved', len(data), 'characters')
tree = ET.fromstring(data)
results = tree.findall('comments/comment')
sum = 0
count = 0
for item in results:
sum = sum + int(item.find('count').text)
count += 1
print('count:',count)
print('sum:',sum)