//所依赖的jar
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.bw</groupId> <artifactId>sparkstreaming</artifactId> <version>1.0-SNAPSHOT</version> <properties> <scala.version>2.11.8</scala.version> <spark.version>2.2.0</spark.version> <kafka.version>2.0.0</kafka.version> </properties> <dependencies> <!--添加 SparkCore 依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <!--添加 SparkStreaming sql 依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>${spark.version}</version> </dependency> <!--添加 SparkStreaming 依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>${spark.version}</version> </dependency> <!--添加 kafka 依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-flume_2.11</artifactId> <version>2.2.0</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.5</version> </dependency> </dependencies> </project>
累加器和广播变量
累加器(Accumulators)和广播变量(Broadcast variables) 不能从Spark Streaming的检查点中恢复逻辑单词计数 中间宕机,7*2不间断运行
如果用了累加器 从1 累加到10 宕机 数据不能从缓存中拿数据 只能重新计算 创建的时候 要使用单例模式
如果你启用检查并也使用了累加器和广播变量,那么你必须创建累加器和广播变量的延迟单实例从而在驱动因失效重启后他们可以被重新实例化。
案例:
package com.bw.streaming.day03 import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.broadcast.Broadcast import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.util.LongAccumulator //使用广播变量和累加器来监控敏感词汇出现次数 object WordBlakList { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(s"${this.getClass.getSimpleName}").setMaster("local[2]") val ssc = new StreamingContext(conf,Seconds(2)) //获取socket流 val stream = ssc.socketTextStream("linux04",9999) //业务处理 stream.foreachRDD(r=>{ //从广播变量中获取敏感词汇 val words: Seq[String] = WordBlackListBC.getInstance(r.sparkContext).value //使用累加器计算敏感词汇出现的次数 val accum: LongAccumulator = WordBlackListAccum.getInstance(r.sparkContext) r.foreach(t => { if (words.contains(t)) { accum.add(1) } }) println("敏感词汇:"+accum.value) }) ssc.start() ssc.awaitTermination() } } //object 是单例模式 object WordBlackListBC{ @volatile private var instance:Broadcast[Seq[String]]=null def getInstance(sc:SparkContext):Broadcast[Seq[String]]={ if(instance==null){ synchronized{ if(instance==null){ instance= sc.broadcast(Seq("a","c")) } } } instance } } //累加器 object WordBlackListAccum{ @volatile private var instance: LongAccumulator = null def getInstance(sc: SparkContext): LongAccumulator = { if (instance == null) { synchronized { if (instance == null) { instance = sc.longAccumulator("WordsInBlacklistCounter") } } } instance } }
2.DataFream ans SQL Operations
你 可 以 很 容 易 地 在 流 数 据 上 使 用 DataFrames 和 SQL 。 你 必 须 使 用 SparkContext 来创建 StreamingContext 要用的 SQLContext。此外,这一过程可 以在驱动失效后重启。我们通过创建一个实例化的 SQLContext 单实例来实现
这个工作。如下例所示。我们对前例 word count 进行修改从而使用 DataFrames和 SQL 来产生 word counts。每个 RDD 被转换为 DataFrame,以临时表格配置并用 SQL 进行查询。
***
你也可以从不同的线程在定义于流数据的表上运行 SQL 查询(也就是说,异步运行 StreamingContext)。仅确定你设置 StreamingContext 记住了足够数
量的流数据以使得查询操作可以运行。否则,StreamingContext 不会意识到任何异步的 SQL 查询操作,那么其就会在查询完成之后删除旧的数据。例如,
如果你要查询最后一批次,但是你的查询会运行 5 分钟,那么你需要调用streamingContext.remember(Minutes(5))(in Scala, 或者其他语言的等价操作)。
注:要导入SQL 的 jar
案例:
package com.bw.streaming.day03
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamingWithSql {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(s"${this.getClass.getSimpleName}").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(2))
//获取socket流
val stream = ssc.socketTextStream("linux04", 9999)
stream.foreachRDD(r=>{
val session = SparkSession.builder().config(r.sparkContext.getConf).getOrCreate()
import session.implicits._
val wordSDataFrame = r.toDF("word")
wordSDataFrame.createOrReplaceTempView("words")
session.sql("select word,count(*) from words group by word").show()
})
ssc.start()
ssc.awaitTermination()
}
}
结果

Caching / Persistence
和 RDDs 类似,DStreams 同样允许开发者将流数据保存在内存中。也就是 说,在 DStream 上使用 persist()方法将会自动把 DStreams 中的每个 RDD 保存 在内存中。当 DStream 中的数据要被多次计算时,这个非常有用(如在同样数 据上的多次操作)。对于像 reduceByWindowred 和 reduceByKeyAndWindow 以 及基于状态的(updateStateByKey)这种操作,保存是隐含默认的。因此,即使开 发者没有调用 persist(),由基于窗操作产生的 DStreams 会自动保存在内存中。
如下图:

7x24 不间断运行
检查点机制
检查点机制是我们在 Spark Streaming 中用来保障容错性的主要机制。与应 用程序逻辑无关的错误(即系统错位,JVM 崩溃等)有迅速恢复的能力. 它 可 以 使 Spark Streaming 阶 段 性 地 把 应 用 数 据 存 储 到 诸 如 HDFS 或 Amazon S3 这样的可靠存储系统中, 以供恢复时使用。具体来说,检查点机 制主要为以下两个目的服务。
1) 控制发生失败时需要重算的状态数。SparkStreaming 可以通 过转化图 的谱系图来重算状态,检查点机制则可以控制需要在转化图中回溯多 远。
2) 提供驱动器程序容错。如果流计算应用中的驱动器程序崩溃了,你可以 重启驱动器程序 并让驱动器程序从检查点恢复,这样 Spark Streaming 就可以读取之前运行的程序处理 数据的进度,并从那里继续。
了实现这个,Spark Streaming 需要为容错存储系统 checkpoint 足够的信息 从而使得其可以从失败中恢复过来。有两种类型的数据设置检查点。 Metadata checkpointing:将定义流计算的信息存入容错的系统如 HDFS。 元数据包括: 配置 – 用于创建流应用的配置。
DStreams 操作 – 定义流应用的 DStreams 操作集合。不完整批次 – 批次的工作已进行排队但是并未完成。Data checkpointing: 将产生的 RDDs 存入可靠的存储空间。对于在多批次间合并数据的状态转换,
这个很有必要。在这样的转换中,RDDs 的产生基于之前批次的 RDDs,这样依赖链长度随着时间递增。为了避免在恢复期这种无限的时间增长(和链长度成比例),状态转换中间的 RDDs 周期性写入可靠地存储空间
(如 HDFS)从而切短依赖链。
总而言之,元数据检查点在由驱动失效中恢复是首要需要的。而数据或者RDD 检查点甚至在使用了状态转换的基础函数中也是必要的。出于这些原因,检查点机制对于任何生产环境中的流计算应用都至关重要。
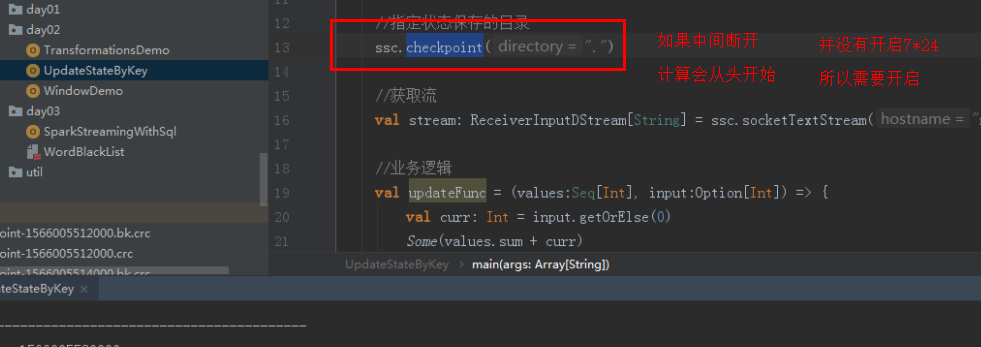
你可以通过向 ssc.checkpoint() 方法传递一个路径参数(HDFS、S3 或者本地路径均可)来配置检查点机制,同时你的应用应该能够使用检查点的数据
1. 当程序首次启动,其将创建一个新的 StreamingContext,设置所有的流并调用 start()。
2. 当程序在失效后重启,其将依据检查点目录的检查点数据重新创建一个 StreamingContext。 通过使用 StraemingContext.getOrCreate 很容易获得这个性能。
如下图:以前写的程序
案例:
package com.bw.streaming.day03 import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} //开启7*24小时 使用checkpoinment机制 让spark steaming应用程序 //在宕机之后重新启动拥有容错功能 object StateWordCount { //提供 方法 程序首次启动的时候创建Streamingcontext 并且包含了业务处理的能力 def createStreamingContext()={ val conf = new SparkConf().setMaster("local[*]").setAppName("StateWordCount") val ssc = new StreamingContext(conf,Seconds(2)) //设置检查点 ssc.checkpoint(".") //获取流 val stream = ssc.socketTextStream("linux04",9999) //业务逻辑 val updateFunc=(values:Seq[Int],input:Option[Int])=>{ val curr:Int=input.getOrElse(0) Some(values.sum+curr) } stream.flatMap(_.split(" ")).map((_,1)).updateStateByKey(updateFunc).print() ssc } def main(args: Array[String]): Unit = { //获取StreamingContext val ssc: StreamingContext = StreamingContext.getOrCreate(".",createStreamingContext) ssc.start() ssc.awaitTermination() } }
如果检查点目录(checkpointDirectory)存在,那么 context 将会由检查点数据重新创建。如果目录不存在(首次运行),那么函数 functionToCreateContext将会被调用来创建一个新的 context 并设置 DStreams。注意 RDDs 的检查点引起存入可靠内存的开销。在 RDDs 需要检查点的批次里,处理的时间会因此而延长。所以,检查点的间隔需要很仔细地设置。在小尺寸批次(1 秒钟)。每一批次检查点会显著减少操作吞吐量。反之,检查点设置的过于频繁导致“血统”和任务尺寸增长,这会有很不好的影响对于需要 RDD 检查点设置的状态转换,默认间隔是批次间隔的乘数一般至少为 10 秒钟。可以通过 dstream.checkpoint(checkpointInterval)。通常,检查点设置间隔是 5-10 个 DStream 的滑动间隔。
驱动器程序容错
驱动器程序的容错要求我们以特殊的方式创建 StreamingContext。我们需 要把检查 点目录提供给 StreamingContext。
与直接调用 new StreamingContext 不同,应该使用 StreamingContext.getOrCreate() 函数。
def createStreamingContext() = {
...
val sc = new SparkContext(conf) // 以 1 秒作为批次大小创建 StreamingContext val ssc = new
StreamingContext(sc, Seconds(1)) ssc.checkpoint(checkpointDir)
}
...
val ssc = StreamingContext.getOrCreate(checkpointDir, createStreamingContext _)
工作节点容错
为了应对工作节点失败的问题,Spark Streaming 使用与 Spark 的容错机制 相同的方法。
所有从外部数据源中收到的数据都在多个工作节点上备份。所有 从备份数据转化操作的过程 中创建出来的 RDD
都能容忍一个工作节点的失 败,因为根据 RDD 谱系图,系统可以把丢 失的数据从幸存的输入数据备份 中重算出来。
接收器容错 receiver 挂了怎么办?
运行接收器的工作节点的容错也是很重要的。如果这样的节点发生错误, Spark Streaming 会在集群中别的节点上重启失败的接收器。
然而,这种情况会 不会导致数据的丢失取决于数据源的行为(数据源是否会重发数据)以及接收器 的实现(接收器是否会向数据源确认收到数据)。
举个例子,使用 Flume 作为 数据源时,两种接收器的主要区别在于数据丢失时的保障。在“接收器从数据 47 池中拉取数据”的模型中,Spark 只会在数据已经在集群中备份时才会从数据 池中移除元素。而在“向接收器推数据”的模型中,
如果接收器在数据备份之前 失败,一些数据可能就会丢失。总的来说,对于任意一个接收器,
你必须同时 考虑上游数据源的容错性(是否支持事务)来确保零数据丢失。 总的来说,接收器提供以下保证。
• 所有从可靠文件系统中读取的数据(比如通过 StreamingContext.hadoopFiles 读取的) 都是可靠的,因为底层的文件系统是有 备份的。
Spark Streaming 会记住哪些数据存放到 了检查点中,并在应用崩溃 后从检查点处继续执行。
• 对于像 Kafka、推式 Flume、Twitter 这样的不可靠数据源,Spark 会把输 入数据复制到其他节点上,但是如果接收器任务崩溃,
Spark 还是会丢失数据。 在 Spark 1.1 以及更早的版 本中,收到的数据只被备份到执行器进程的内存 中,
所以一旦驱动器程序崩溃(此时所 有的执行器进程都会丢失连接),数据也 会丢失。在 Spark 1.2 中,
收到的数据被记录到诸如 HDFS 这样的可靠的文 件系统中,这样即使驱动器程序重启也不会导致数据丢失。
综上所述,确保所有数据都被处理的最佳方式是使用可靠的数据源(例如 HDFS、拉式 Flume 等)。
如果你还要在批处理作业中处理这些数据,使用可 靠数据源是最佳方式,因为 这种方式确保了你的批处理作业和流计算作业能 读取到相同的数据,
因而可以得到相同的 结果。
处理保证 精确一次的执行语义 内部 通过checpoint来保证的 如果经过kafka在发送 就不能保证
由于 Spark Streaming 工作节点的容错保障,Spark Streaming 可以为所有的 转化操作提供 “精确一次”执行的语义,即
使一个工作节点在处理部分数据时 发生失败,最终的转化结 果(即转化操作得到的 RDD)仍然与数据只被处理一次得到的结果一样。
然而,当把转化操作得到的结果使用输出操作推入外部系统中时,写结果 的任务可能因故障而执行多次,一些数据可能也就被写了多次。
由于这引入了 外部系统,因此我们需要专门针对各系统的代码来处理这样的情况。我们可以 使用事务操作来写入外部系统
(即原子化地将一个 RDD 分区一次写入),或者 设计幂等的更新操作(即多次运行同一个更新操作仍生成相同的结果)。
比如 Spark Streaming 的 saveAs...File 操作会在一个文件写完时自动 将其原子化 地移动到最终位置上,
以此确保每个输出文件只存在一份。
性能考量
最常见的问题是 Spark Streaming 可以使用的最小批次间隔是多少。
总的来 说,500 毫秒已经被证实为对许多应用而言是比较好的最小批次大小。
寻找最 小批次大小的最佳实践是从一个比较大的批次大小(10 秒左右)开始,不断使用 更小的批次大小。
如果 Streaming 用户界面中显示的处理时间保持不变,你就 可以进一步减小批次大小。
如果处理时间开始增加,你可能已经达到了应用的 极限。相似地,对于窗口操作,计算结果的间隔(也就是滑动步长)对于性能也有 巨大的影响。
当计算代价巨大并成为系统瓶颈时,就应该考虑提高滑动步长 了。减少批处理所消耗时间的常见方式还有提高并行度。
有以下三种方式可以提高 并行度:
• 增加接收器数目 有时如果记录太多导致单台机器来不及读入并分发的 话,接收器会成为系统瓶颈。
这时 你就需要通过创建多个输入 DStream(这样 会创建多个接收器)来增加接收器数目,然 后使用 union 来把数据合并为一个 数据源。
• 将收到的数据显式地重新分区 如果接收器数目无法再增加,你可以通 过使用 DStream.repartition 来显式重新分区输
入流(或者合并多个流得到的 数据流)来重新分配收到的数据。 • 提高聚合计算的并行度 对于像 reduceByKey() 这样的操作,
你可以在第 二个参数中指定并行度,我们在介绍 RDD 时提到过类似的手段。