创建topic:./kafka-topics.sh --create --topic JsonData --partitions 3 --replication-factor 1 --zookeeper linux04
删除:bin/kafka-topics.sh --delete --zookeeper sentos01:2181 --topic topicName
启动:./kafka-server-start.sh -daemon ../config/server.properties
1.上传2.0
2.解压tar -zxvf kafka_2.11-2.0.0.tgz
3.进入2.0目录 libs 下面 查看内置zookeeper
输入命令 ll zoo*
如下图:

4.在bin目录下面
输入命令:
./zookeeper-server-start.sh ../config/zookeeper.properties
./kafka-server-start.sh ../config/server.properties
5.在连接一台机器 然后查看进程
输入命令:jps

注意:zookeeper启动的是单机版的zk
6.在bin目录下 创建主题命令
|
./kafka-topics.sh --create --topic test --replication-factor 1 --partitions 1 --zookeeper localhost:2181 |

--bootstrap-server 是主机地址
--replication-factor 副本数
--partitions 分区数
--topic test 名字叫test

7. 在bin目录下面 查看消息队列
|
./kafka-topics.sh --list --zookeeper localhost:2181 |

//这台单机版的kafka 叫做broker 代理
队列名字叫做topic 存储数据的 消息分类的 可以建立多个topic
|
./kafka-topics.sh --create --topic test1 --replication-factor 1 --partitions 1 --zookeeper localhost:2181 |
|
生产数据 的方式有很多 java方式、 flume、也可以是内置的producer.sh 往外拿也有很多中 java客户端、sparksteaming |

|
生产者 ./kafka-console-producer.sh 查看命令 ./kafka-console-producer.sh --broker-list localhost:9092 --topic test 放数据 那台机器 那个toplic 里面放数据 |

|
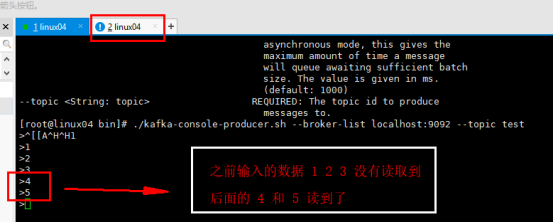
消费者命令 ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test 如下图: 上图和下图做对比 消费的是最新的数据 |

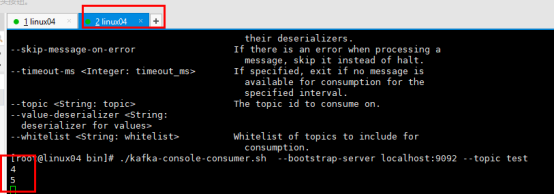
|
如果想消费之前的数据 1.生产者 ./kafka-console-producer.sh --broker-list localhost:9092 --topic test01 2.消费者 消费的是之前的数据 ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test01 --from-beginning |



Broker代理 安装kafka的
Producer------topic====consumer
生产者 放数据 消费者
以上是单机版的kafka
下面安装集群版的kafka
1.进入conf目录
|
vim server.properties 修改配置文件 必须修改下面三个地方 |




2.上传到别的机器上面
|
scp -r kafka_2.11-2.0.0 linux05:$PWD scp -r kafka_2.11-2.0.0 linux06:$PWD 将配置文件里面的vim server.properties 的 broker.id 修改了 三台不一样的数据 |
|
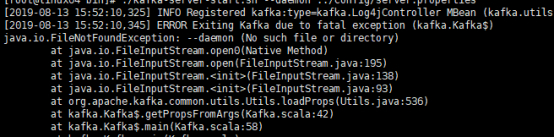
3.在kafka-----》bin目录下启动 //前台命令 ./kafka-server-start.sh ../config/server.properties ------------------------------------------------------------------- //后台命令 ./kafka-server-start.sh --daemon ../config/server.properties 会报错如下图: 正确的命令是: ./kafka-server-start.sh -daemon ../config/server.properties |
4 搭建完成
生产topic
|
1 这个 指定副本的数量是错误的 ./kafka-topics.sh --create --topic t1807a1 --partitions 2 --replication-factor 5 --zookeeper linux04:2181 2 设置三个副本也错了 ./kafka-topics.sh --create --topic t1807a1 --partitions 2 --replication-factor 3 --zookeeper linux04:2181 3 两个副本创建出来了 ./kafka-topics.sh --create --topic t1807a1 --partitions 2 --replication-factor 2 --zookeeper linux04:2181 4 查看分区数据 在自己创建的data中
5 bin---》 ./kafka-topics.sh --describe --topic t1807a1 --zookeeper linux04:2181 两个分区 0分区 0是机器名称 0,1 0号机器放的一个 1号机器放的一个 1 分区 1是机器名称 Kafka的组件 |



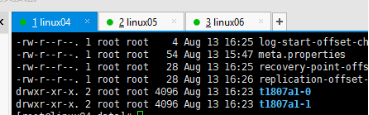
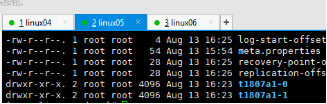

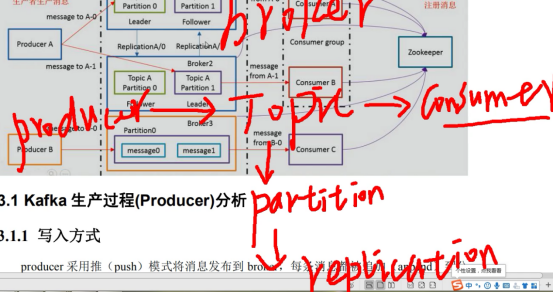
|
往分区放数据 如果两个分区 先后顺序是什么? 分区的具体目录 |
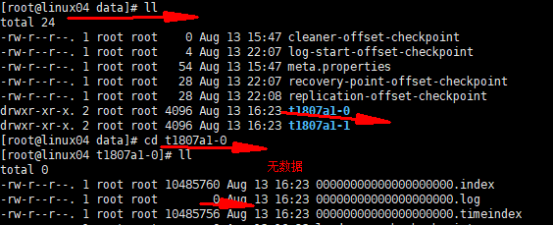
|
监控写入分区的数据 1.下图是两个分区的具体信息 2.第一台机器 0号分区的监控 主文件 3.第一台机器 1号分区的监控 主文件 |

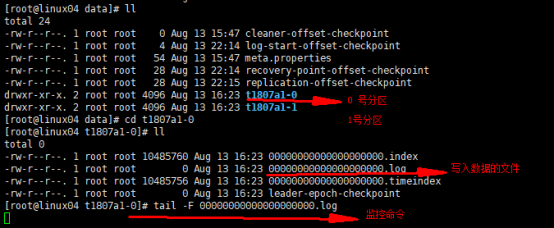
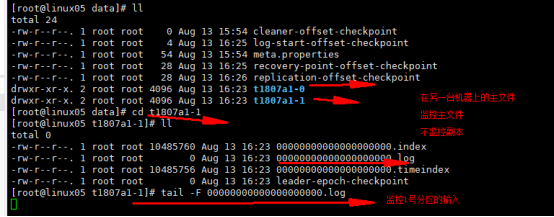
t1807a1是topic的名称
如上:监控完成 往topic ---- 》t1807a1里面写数据 做测验 到底先往那个分区写数据
如下图:
|
|
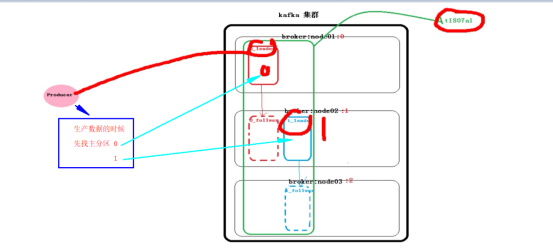
|
测试:
./kafka-console-producer.sh --topic t1807a1 --broker-list linux04:9092 先往那个分区放数据不一定 但一定是轮询的放入数据 一个分区放一条数据 也可以指定分区 放数据 |
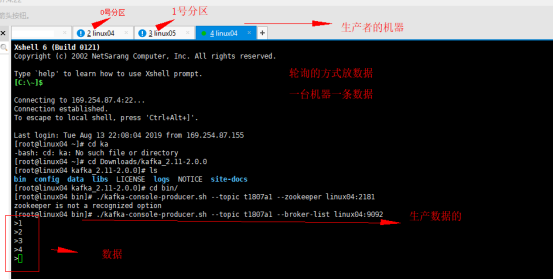
写入数据的方式:
Producer 采用推(push)模式将消息发布到broker 每条消息都被追加(append)到分区中(partition)中,属于顺序写磁盘想(顺序写磁盘)
数据存储形式是kv
属性有三个 区号 id(offset)偏移量 时间戳
存数据底层是 hash表

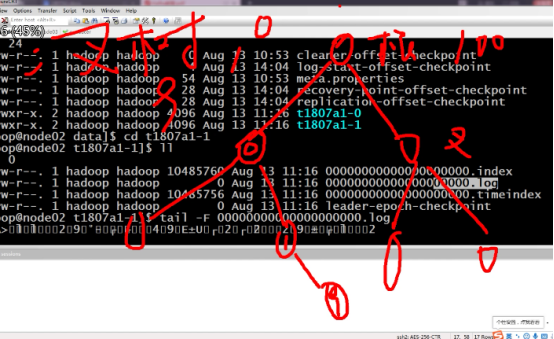
分区的原则
1,指定了partition 直接使用
2,未指定partition但指定了key,通过对key的value进行hash出一个partition
3,Partition和key都未指定 使用轮询选出一个partition
4,
5 存储策略
基于时间
基于大小
|
1.进入zookeeper的bin目录 启动命令 2.
|

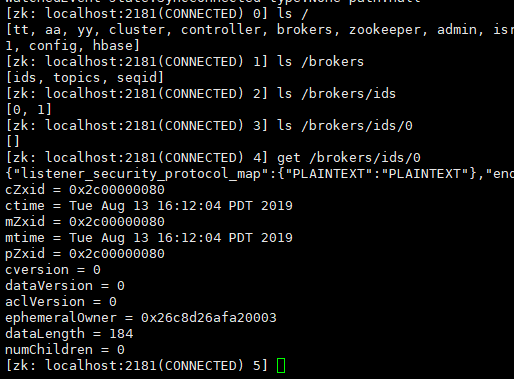
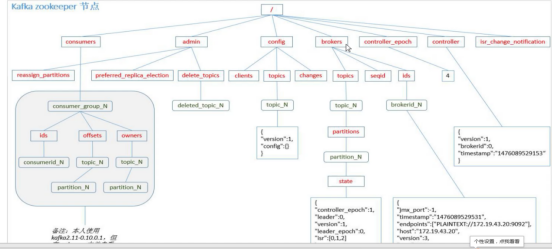
消费组案例
|
第一种情况 1.一个生产者 和两个消费者==(两个组) 两个消费者同时消费一个topic的数据 和分组没有关系
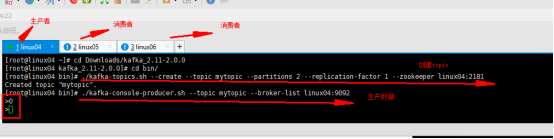
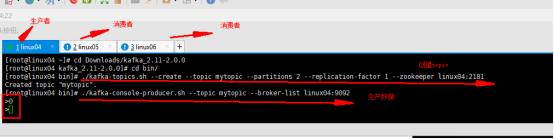
命令 创建topic [root@linux04 bin]# ./kafka-topics.sh --create --topic mytopic --partitions 2 --replication-factor 1 --zookeeper linux04:2181 01机器生产者的命令 在kafka的bin目录 [root@linux04 bin]# ./kafka-console-producer.sh --topic mytopic --broker-list linux04:9092 02机器消费者的命令 [root@linux05 bin]# ./kafka-console-consumer.sh --topic mytopic --bootstrap-server linux04:9092 03机器消费者的命令 [root@linux06 bin]# ./kafka-console-consumer.sh --topic mytopic --bootstrap-server linux04:9092 第二种情况 2.两个分区 两个消费者 (一个组里 参数 --group XXX) 生产者的命令不变 01机器生产者的命令 在kafka的bin目录 [root@linux04 bin]# ./kafka-console-producer.sh --topic mytopic --broker-list linux04:9092
02机器消费者的命令: [root@linux05 bin]# ./kafka-console-consumer.sh --topic mytopic --bootstrap-server linux04:9092 --group aaa 03机器的消费者命令: [root@linux06 bin]# ./kafka-console-consumer.sh --topic mytopic --bootstrap-server linux04:9092 --group aaa
消费数据的时候是 一个消费者一条 ,轮询消费 第三种情况 当只有两个分区 三个消费者其中一个消费者没有数据 (一个组里 三个消费者) 在上面的基础上再添加一个消费者 [root@linux06 bin]# ./kafka-console-consumer.sh --topic mytopic --bootstrap-server linux04:9092 --group aaa 第四种情况 当只有两个分区 一个消费者的时候 自己消费所有的数据 |


|
|

|
拦截器 第一个interceptor会在消息发送前将时间戳信息加载到消息value的最前部 第二个 interceptor会在消息发送后更新成功发送消息数和失败发送消息数 1.写生产者类 2.写第一个拦截器timeInterceptor //将时间戳加到value前面 实现ProducerInterceptor<String,String>接口 实现4个方法 onSend(ProducerRecord<String,String> record) //发送数据之前调用 onAcknowledgement(RecordMetadata metadata, Exception exception) //发送确认之前调用 close() configure(Map<String, ?> configs)
//记录发送消息失败和成功的条数 实现4个方法 onSend(ProducerRecord<String,String> record) //发送数据之前调用 onAcknowledgement(RecordMetadata metadata, Exception exception) //发送确认之前调用 close() configure(Map<String, ?> configs) 3.在生产者类里面注册拦截器 拦截器的顺序要第一个和第二个不要写混了 4.注意
打印结果 |



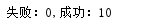
快捷键替换引号
Ctrl+f --->ctrl+r