
- 课程地址:http://web.stanford.edu/class/cs224n/
- 时间:2017年
- 主讲:Christopher Manning、Richard
Lecture 1: Introduction
NLP:Natural language processing
常见自然语言项目:(有一次面试问过)
- 微软 Cortana
- 苹果 Siri (消费级技术)
- 亚马逊 Alexa
- 小米 小爱
- 百度 小度
- 天猫 天猫精灵
人类语言的特点:
- 明确的指向性
- 语言是符号、符号不基于任何逻辑和AI
- 具有连续的载体 (以唠嗑就根本停不下来)
2015年之前的机器学习都是人在做大量的数据分析(比如:手动特征工程),而机器只是在做数值的优化(事实上电脑很适合做数值优化,人类不适合)。
这并不是我们所期望的机器学习。
深度学习(Deeplearning)是表征学习(Representation Learning)的一个重要分支。
表征学习的理念是,我们可以向电脑提供来自世界的原始信号,无论是视觉信息还是语言信息,然后 电脑可以自动得出好的中介表征 来很好的完成任务,从某种意义上来说,它是自己定义特征。
深度学习不只是基于神经网络,也可以是概率模型以及其他方法运用于深度架构中。(概率图模型)
利用深度学习学习词向量,高维空间成为了非常棒的语义空间。具有相同含义的词聚集成块,向量空间存在方向,它会透露关于成分和意义的信息。
然而人类不擅长解读高维空间的信息,人类跟习惯于2维度和3维度的信息表示。
Lecture 2: Word Vectors
单词简单的含义是一个单词代表一种东西。
离散化的东西难以表达出连续型的特征,而语义往往是连续化的,单词是离散化的。
离散化表示词向量不能体现词与词之间的相互关系。单词需要通过上下文来理解他的含义。
分布式表示:密集型词向量表示词汇
word2vec
word2vec两个模型:
- skip-gram(SG)给定一个中心词 某个单词在上下文中出现的概率
- Continuous Bag of Words (CBOW)
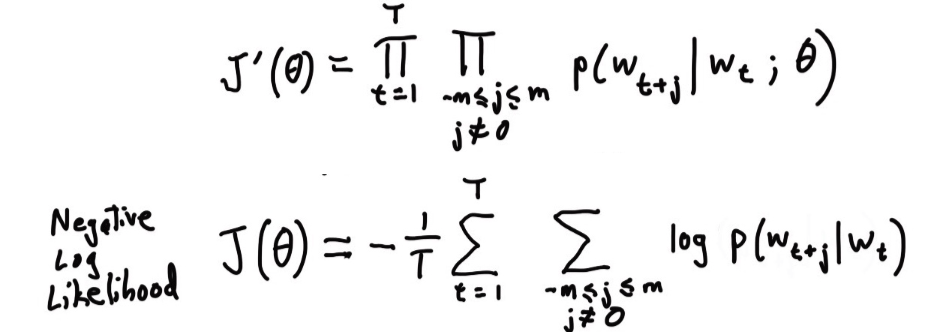
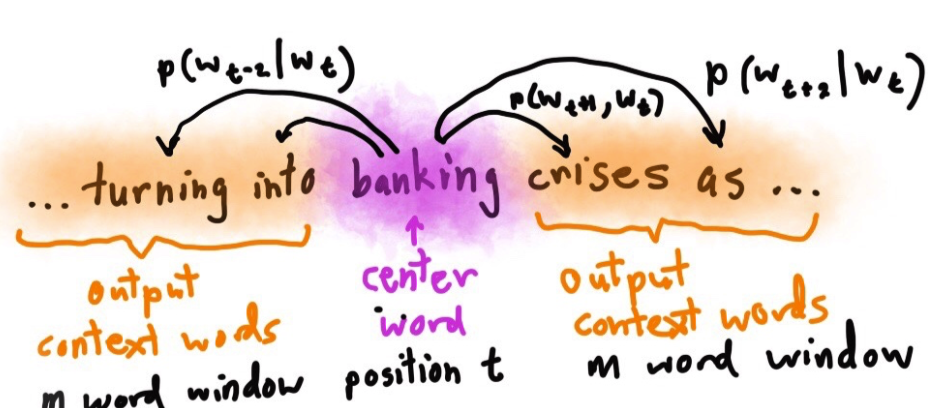
我们使用softmax来度量词向量的概率,这种求积类似于一种粗糙衡量相似性的方法。
两种向量表示有一种简单的,也有一种难。也有可能两种向量的一样简单,我们在做次向量的时候回选择简单的。
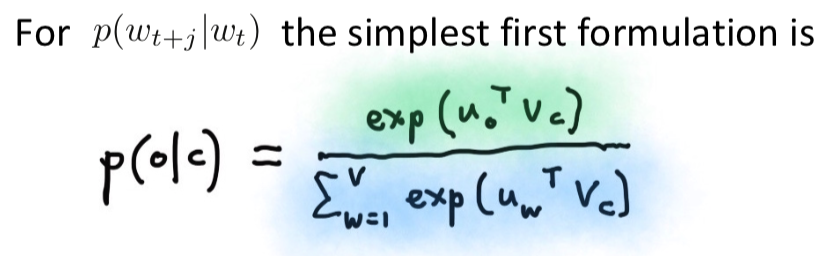
两个向量的相似性越大那么这两个的点积就越大。这是一种通过点积衡量相似性的方法。
(个人理解,点积就是一种空间向量的形式,我用这种形式来衡量两个向量的相似性)
我们得到点积的形式,然后把他转化成softmax的形式

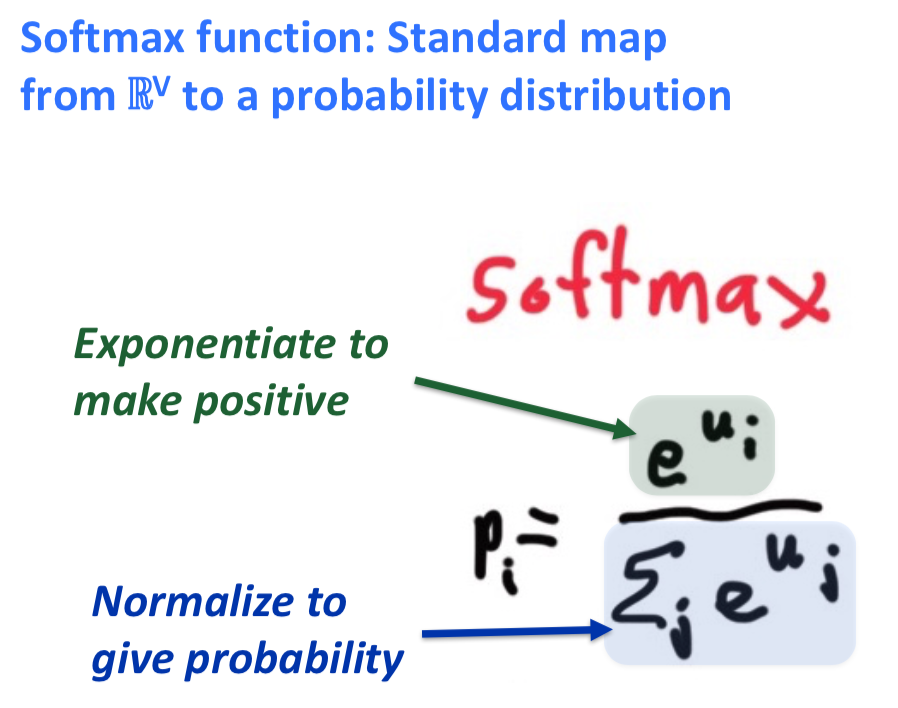
softmax 将数值转化成概率的标准方法
指数函数的值一定为正数,把正数转变成等比例的概率
两个高效训练方法:
- Hierarchical softmax
- Negative sampling
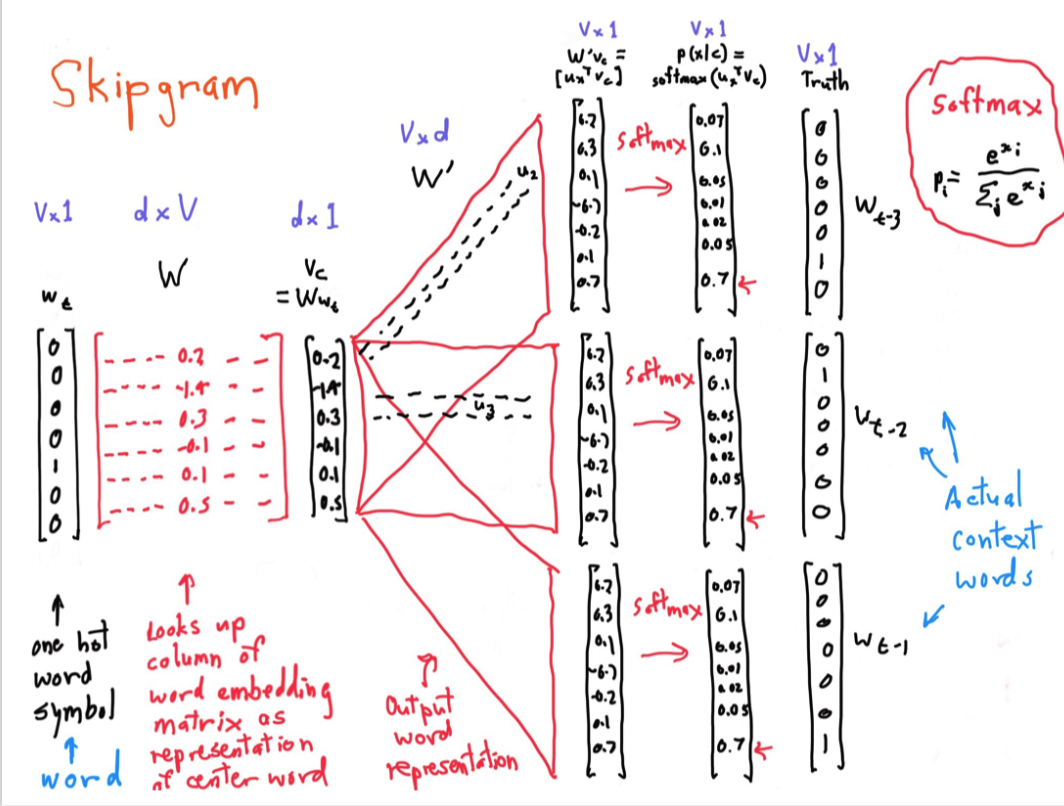
- W是所有中心词的向量矩阵
- wt是词向量表示
函数求导(向量)

链式求导法则

主义这里的long 是ln 的意思


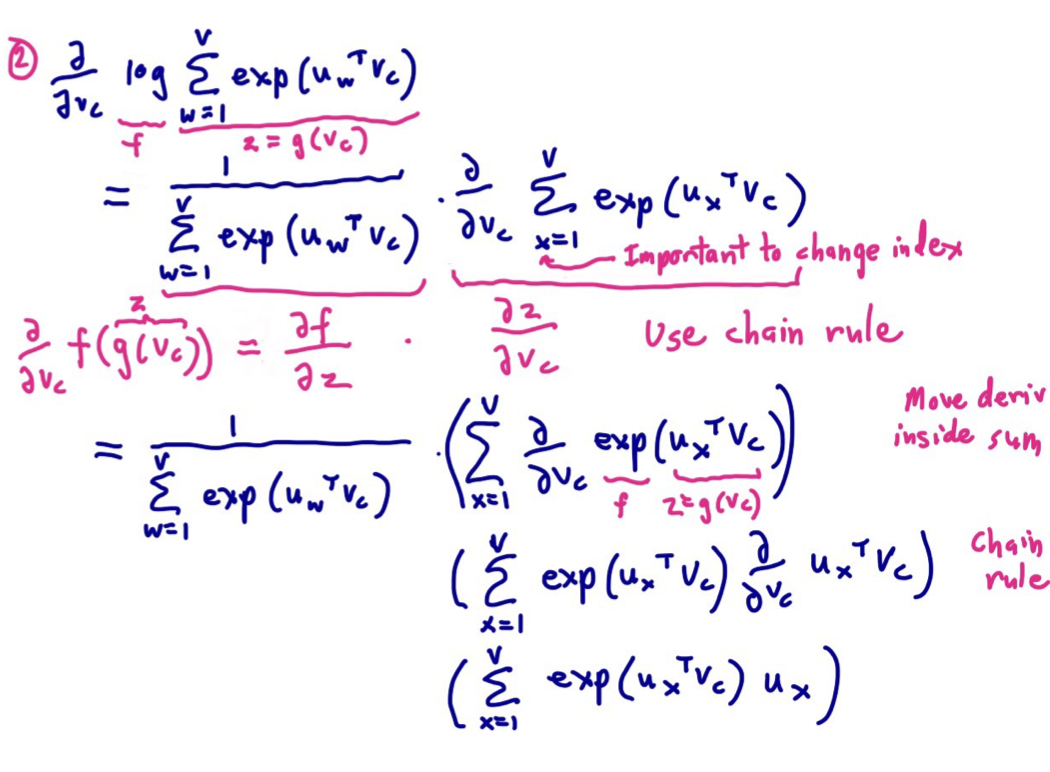

学生提问:我们为什么采用点积作为概率处理的基础?
回答:你也可以采用其他向量代数的形式,但是很明显点积最明显最简单。因为它衡量的是想关系和相似性的同一种方式。
随机梯度下降法:采用小批量的数据,进行算法权重的优化。而不是全批量的数据。这在实际中会使得训练更加快速。
实际证明神经网络算法喜欢噪音。
Lecture 3: More Word Vectors
- Then take gradients at each such window for SGD
- 两个词的向量表示:中心词向量 背景词向量
negative sampling
随机从语料库中挑选一些词,而不是全部语料库一起训练
他们称word2vec是一个软件software
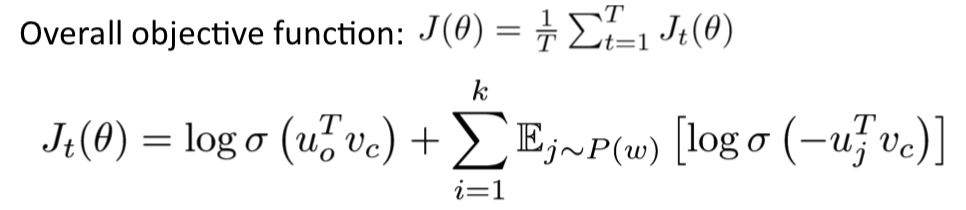
- T是每个windows的语料
- sigmoid是一个简单的逐个元素操作的函数,sigmoid仅仅把任意实数数值压缩至0到1之间,也就是概率化
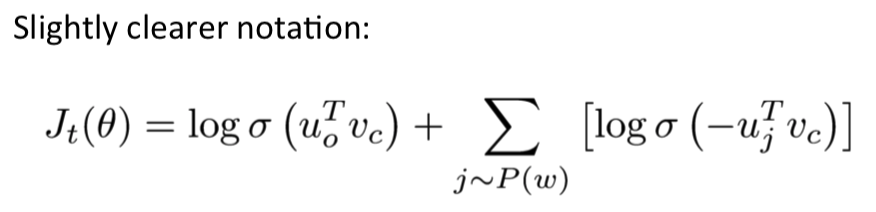
期望,一个负采样的概率。
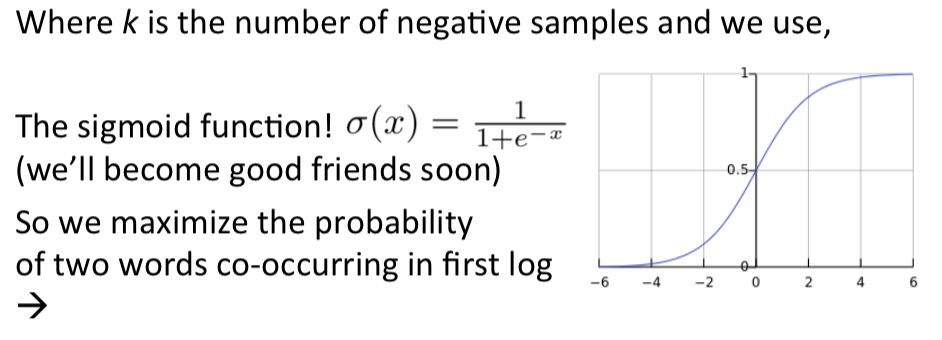
theta通常是所有变量的参数。
Window length 1 (more common: 5 - 10)
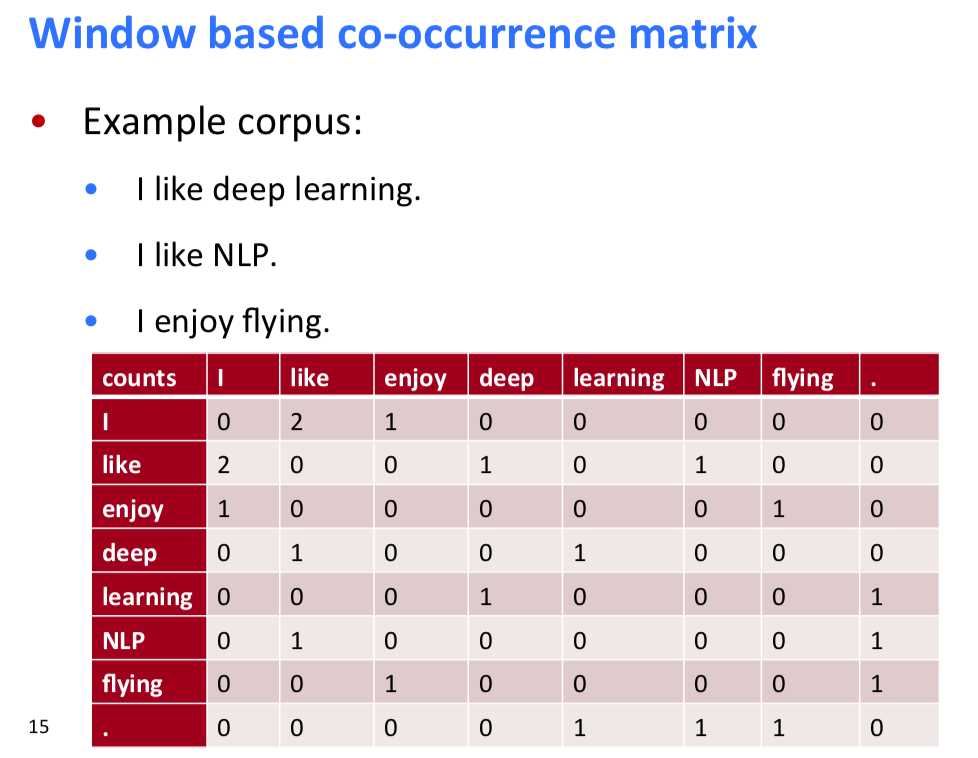
co-occurrence vectors的缺点:
- 有新的词需要跟新其他向量,下游机器学习要修改参数。
- 向量的维度比较高。
Solution: Low dimensional vectors: - Method 1: Dimensionality Reduction on X
SVD:

代码实现:

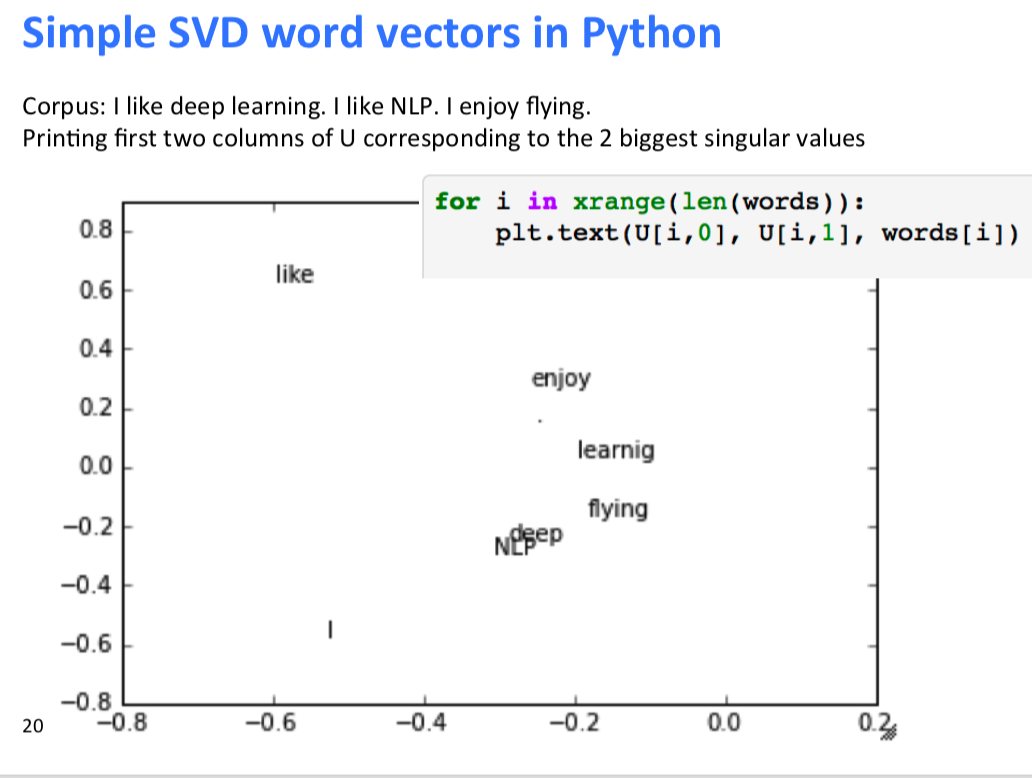
对于the, he, has我们一般会限制他的次数。
SVD在处理大量矩阵的时候不是很好。
PCA优点训练数据快,
两种自然语言训练的优缺点:
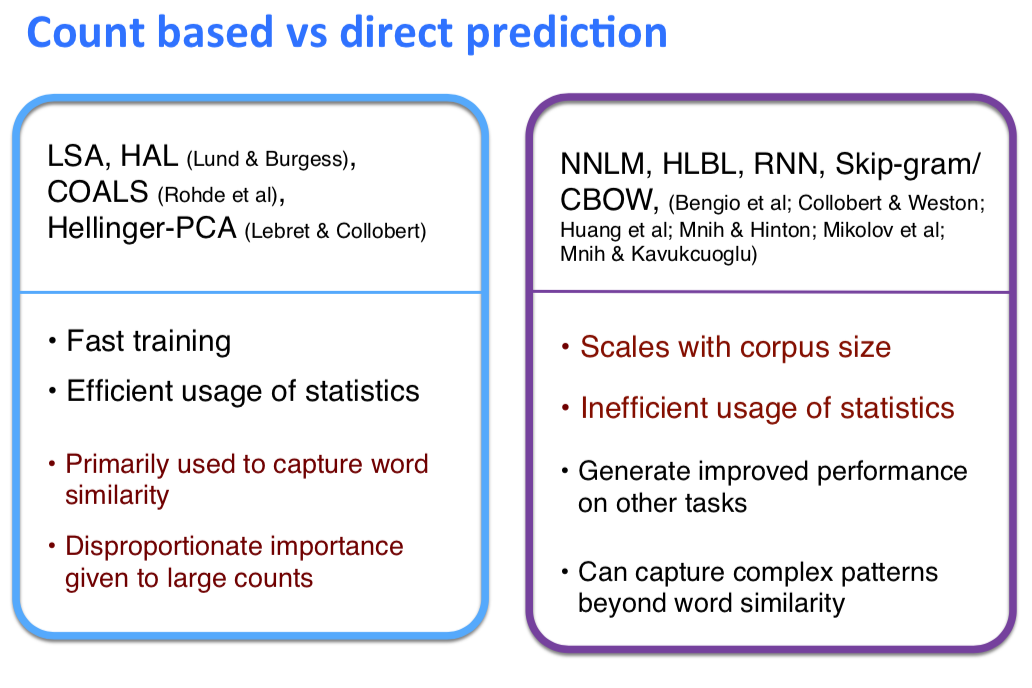
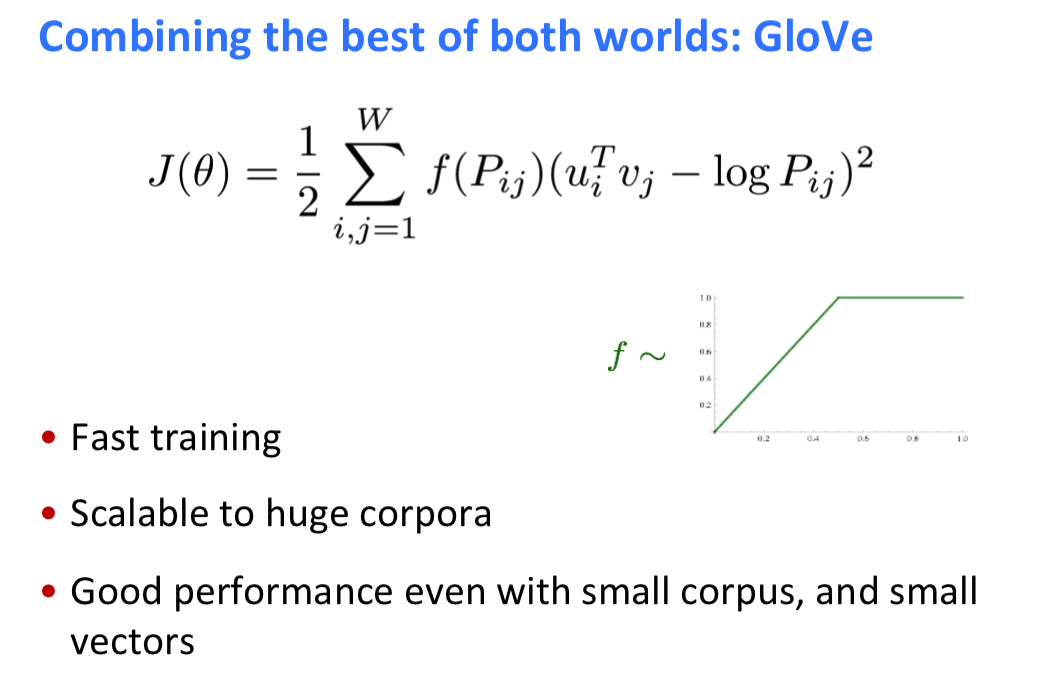
结合后产生了GloVe模型
GloVe
Lecture 4: Word Window Classification and Neural Networks
4.1 softmax

最大化联合概率密度,等于最小化它取负数

4.2 cross-entropy
用交叉熵来计算两个分布之间的距离,从而度量softmax结果的好坏,

- p正确的分类 one-hot
- q 使用softmax计算的分类
4.2.2 KL发散也是一种上面所述的两个分布度量机制,
交叉熵理解成尽可能地最小化两个分布之间的KL发散

根据cross-entropy交叉熵来构造损失函数:

正则化希望全职会尽可能的小,目的是为了防止过拟合,使得机器学习模型具有很好的泛化能力。

Softmax求导



Feed-forward 前馈
4.3 max-margin loss
超级强大的损失函数。比softmax的交叉熵误差更有鲁棒性 而且非常强大和有用。

s:正确窗口
sc:错误窗口

max-margin loss的求导没有看懂!!!
