堆与堆排序
一、什么是堆
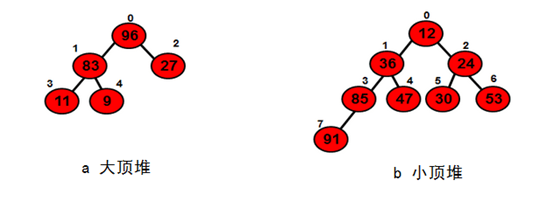
堆其实是一颗完全二叉树,除了树的最后一层不是满的,其他层从左到右都是满的。堆中除叶子节点外每个节点的关键字都大于等于(或小于等于)他的左右孩子的关键字,其中节点的关键字都大于等于左右孩子的关键字的堆称之为“大顶堆”或“最大化堆”,如下图a;节点的关键字都小于等于左右孩子的关键字的堆称之为“小顶堆”或“最小化堆”,如下图b。
二、堆的实现
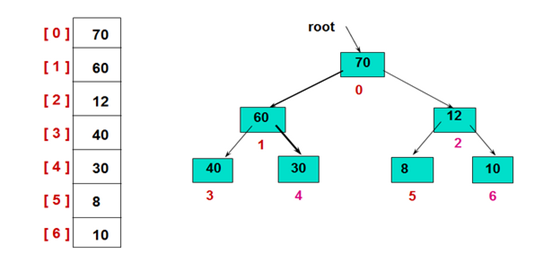
因为堆是完全二叉树的结构,所以常用数组来进行实现堆。一般把根节点放在数组下标是0的位置,则i位置节点的数组下标则是(i-1)/2;i节点的左右孩子节点的数组下标为2*i+1和2*i+2。(如果根节点从1开始,则左右孩子节点数组下标是2*i和2*i+1)。
如图是一种大顶堆的数组存储及结构图。
二、堆的调整操作
堆的调整分为向上筛选和向下筛选(都是以大顶堆为例)。
向上筛选:
如果对节点i进行向上筛选,就是比较i节点的值与其父节点值的大小,如果该节点值比其父节点的值大,则这两个节点交换,再拿交换后的这个节点与其父节点比较,依次往上,直到该节点的值比其父节点的值小时或者该节点成为了根节点时结束。
向下筛选:
如果对节点i进行向下筛选,就是比较i节点的值与其左右孩子节点值的大小,如果三者中最大的值不是i节点,则i节点与其中值最大的节点进行位置交换(如果只有一个孩子节点,则二者比较再交换),再拿交换后的该节点与其左右孩子节点比较,依次往下,直到该节点的值比起左右孩子的值都大时或者该节点成为叶子节点时结束。
三、堆的建立
两种建立方式(都是以大顶堆为例)
1、不断添加元素进行建堆
每添加一个元素需要进行一次堆的调整,以保证堆结构。添加到第n个节点时,就对n节点进行向上筛选,这样即使添加了一个较大的元素,通过向上筛选,会把其位置往上调整,这样就保证了堆的结构。
时间复杂度:添加第一个元素是最差情况下比较0次,第二个元素时最差情况下比较1次,第三个元素时比较1次……其实每添加一个元素就是比较该节点的深度-1次,即(根节点从0开始)第n个节点需要比较log2(n) 次,所以时间复杂度为O(log2(1)) + O(log2(2)) + O(log2(3))+…..O(log2(n)) = n log2(n)
证明过程我在纸上证明了,以下附上图片

2、把一个数组直接转换成堆
如果是将数组A转化成一个大顶堆。思想是,先找到堆的最后一个非叶子节点(即为第n/2个节点),然后从该节点开始,从后往前逐个调整每个子树,使之称为堆,最终整个数组便是一个堆。子数组A[(n/2)+1..n]中的元素都是树中的叶子,因此都可以看作是只含有一个元素的堆。
时间复杂度:第n/2 个节点最差情况下向下筛选比较1次,第n/2 – 1个及其节点最差情况下向下筛选比较其log2(n)- 其深度 次,所以时间复杂度与上类似,为(n/2)/2*1+(n/2)/4*2+….1*log2(n)=nlog(n)。所以两种插入方法的时间复杂度是相同的。
三、堆的移除操作
移除指的是移除堆的根节点(根节点的关键字是堆中所有节点关键字中的最大值或最小值),就是数组中索引为0的节点, 但是一旦移除根节点树就不是完全的了,数组中的0位置空出来了。所以为了在移除后仍然保持堆结构,我们需要做一定的调制操作。
概括移除操作分三步完成(以大顶堆为例):
第一步,移走根节点;
第二步,把最后一个节点移到根的位置;
第三步,向下筛选该节点。
这个过程也叫做“向下筛选”。
四、堆的插入节点操作
插入一个节点还是比较简单的。开始时把节点插入到数组中最后一个空着的单元中,而后向上筛选到合适位置,使得它在一个大于它的节点之下,在一个小于它的节点之上。
五、Java实现堆及其操作的代码
package data_structure;
import java.util.Random;
/**
* 堆的实现
* @author qihuijie
*/
public class Heap {
private Node[] heapArray; //存储堆节点的数组
private int maxSize; //堆节点的最大值
private int currentSize; //当前堆的大小
public Heap(int mx) { //完成一些初始化操作
maxSize = mx;
currentSize = 0;
heapArray = new Node[maxSize];
}
public boolean isEmpty() { //判断堆是否为空
return currentSize == 0;
}
//插入一个节点
public boolean insert(int key) {
if(currentSize == maxSize) return false; //已满 不能插入
Node newNode = new Node(key);
heapArray[currentSize] = newNode; //先插入到最后
trickleUp(currentSize++); //从该节点开始向上筛选,并把currentSize的值加1
return true;
}
//删除一个最大节点(根)
public Node remove() {
Node root = heapArray[0];//移除根节点
heapArray[0] = heapArray[--currentSize];//最后一个节点移动到根节点的位置
trickleDown(0); //向下筛选
return root;
}
//向上筛选
private void trickleUp(int index) {
int parent = (index-1)/2; //先找到父节点索引
Node bottom = heapArray[index];
while(index >0 && heapArray[parent].getKey() < bottom.getKey()) {
//只要index>0且父节点的数据项的值小于自己的值 就继续向上
heapArray[index] = heapArray[parent];
index = parent;
parent = (index-1)/2;
}
heapArray[index] = bottom;
}
//向下筛选
private void trickleDown(int index) {
int largeChild;
Node top = heapArray[index];
while(index < currentSize/2) { //只要不是叶节点 就继续向下筛选
//首先获得其左右孩子节点中数值大的那个节点的下标
int left = index*2+1;
int right = index*2+2;
if(right < currentSize && heapArray[left].getKey() < heapArray[right].getKey()) {
largeChild = right;
}else {
largeChild = left;
}
//进行值的比较,把值大的子节点与该节点互换,并对值最大的那个节点再继续向下筛选
if(top.getKey() >= heapArray[largeChild].getKey()) break;
else {
heapArray[index] = heapArray[largeChild];
index = largeChild;
}
}
heapArray[index] = top;
}
/**
* 测试堆的使用是否正常
*/
public static void main(String[] args) {
Heap heap = new Heap(10);
Random random = new Random();
//逐个节点进行插入
for (int i = 0; i < 10; i++) {
heap.insert(random.nextInt(100));
}
for (int i = 0; i < 10; i++) {
System.out.print(heap.heapArray[i].getKey()+" ");
}
System.out.println("这是逐个节点插入后的结果");
//对数组进行操作,使其成为堆
for (int i = 0; i < 10; i++) {
Node node =new Node(random.nextInt(100));
heap.heapArray[i] = node;
}
//对数组进行调整
for (int i = heap.currentSize/2-1; i >= 0; i--) {
heap.trickleDown(i);
}
for (int i = 0; i < 10; i++) {
System.out.print(heap.heapArray[i].getKey()+" ");
}
System.out.println("这是调整后的结果");
//堆的移除操作
for (int i = 0; i < 10; i++) {
System.out.print(heap.remove().getKey()+" ");
}
}
static class Node{
int key;
public Node(int key){
this.key = key;
}
int getKey(){
return key;
}
}
}
六、堆排序
堆排序(Heapsort)是利用堆所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。就大根堆而言,我们已经知道大根堆的要求是每个节点的值都不大于其父节点的值。在数组的非降序排序中,需要使用的就是大根堆,因为大根堆的最大的值一定在堆顶。
堆排序是利用删除堆的根节点和调整堆的过程实现的。首先是根据所要进行排序的数组元素构建堆。然后将堆的根节点(根节点为最大值)取出(一般是与最后一个节点进行交换),将前面len-1个节点继续进行堆调整的过程,然后再将根节点取出,这样一直到所有节点都取出。堆排序过程的时间复杂度是O(nlgn)。因为建堆的时间复杂度是O(n)(调用一次);调整堆的时间复杂度是lgn,调用了n-1次,所以堆排序的时间复杂度是O(nlgn)。
七、堆排序实现
第一步,将要排序的数组建成大顶堆。
第二步,将此大顶堆的根元素与最后一个元素交换,这样就把最大值放到数组最后一个位置去了,并且将新换的元素进行向下筛选,筛选完成后又恢复了堆结构。接着将根节点与倒数第二个节点交换,再重复上述步骤,这样就形成了在这个数组的前部分为无序区,后部分为有序区,一直将第一个元素(根节点)与无序区的最后一个元素进行交换,知道无序区的长度为2时截止,这时我们也就将整个数组进行排序完毕了。
Java代码实现:
public static int [] heapSort(int []s){
//第一步,建立大顶堆
for (int i = (s.length/2-1); i >= 0; i--) {
int index = i;
while(index<=s.length/2-1){
int left=index*2+1;
int right=index*2+2;
int large ;
if(right<s.length && s[right]>s[left]) large = right;
else large = left;
if(s[index]>s[large]) break;
else{
int temp = s[index];
s[index]=s[large];
s[large]=temp;
index = large;
}
}
}
//第二步,进行根节点与无序区最后一个元素交换
for (int i = s.length-1; i >= 0 ; i--) {
int temp = s[i];
s[i] = s[0];
s[0] = temp;
int index=0;
while(index < i/2){
int left = index*2+1;
int right = index*2+2;
int large;
if(right<i && s[right]>s[left]) large = right;
else large = left;
int index2=index;
if(s[index]>s[large]) break;
else {
int t = s[index];
s[index] = s[large];
s[large] = t;
index = large;
}
}
}
return s;
}