1. Linux内核源代码中子目录结构
所阅读的内核版本为linux-2.6.12.1,偶数版本为稳定版本。
首先使用tree命令对整个内核文件进行观察如下:
可以发现目录和文件规模相当巨大,难以详尽描述,所以下面仅仅列出一级目录中的directories:
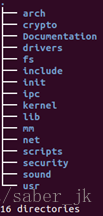
2. 主要子目录以及大致功能
从1中所说的目录中选出较为重要的11个如下:
(1)Documentation——内核方面的相关文档。
(2)arch——与体系结构相关的代码。 对应于每个支持的体系结构,有一个相应的目录如x86、 arm、alpha等。每个体系结构子目录下包含几个主要的子目录: kernel、mm、lib。
(3)include——内核头文件。 对每种支持的体系结构有相应的子目录,如asm-x86、 asm-arm、asm-alpha等。
(4)init——内核初始化代码。提供main.c,包含start kernel函数。
(5)kernel——内核管理代码。
(6)mm——内存管理代码。
(7)ipc——进程间通讯代码。
(8)net——内核的网络代码。
(9)lib——与体系结构无关的内核库代码,特定体系结构的库代码保存在arch/*/lib目录下。
(10)drivers——设备驱动代码。每类设备有相应的子目录,如char、 block、net等 fs 文件系统代码。每个支持文件系统有相应的子目录, 如ext2、proc等
(11)Scripts——此目录包含了内核设置时用到的脚本。
3. BIOS启动以及内核的加载
Linux引导过程大致可以分为几步:BIOS ->Boot loader->内核初始化->用户态初始化 ,这里我们主要讨论前两个环节。
BIOS:当PC的电源打开之后,PC寄存器被设置为0xFFFF0,开始自动执行的程序代码,这个地址通常是ROM-BIOS的地址,即BIOS开始执行。在这一阶段BIOS的大概工作为三部分:
1. 第一个部分是对系统硬件进行故障检测,也叫做加电自检(Power OnSelf Test,简称POST),功能是检查计算机系统是否良好。
2. 第二个部分是初始化,包括创建中断向量、设置寄存器、对一些外部设备进行初始化和检测等,其中很重要的一部分是读取BIOS配置,对系统硬件进行状态配置和检查。
3. 最后一个部分是启动自举程序,主要功能为读取引导设备第一个扇区的前 512 字节(MBR),将其读入到内存0x0000:7C00,并跳转至此处执行。
Boot loader:硬盘第一个扇区的前512 个字节是主引导扇区,由446 字节的MBR、64字节的分区表和2 字节的结束标志组成。MBR(MasterBoot Record)是 446 字节的引导代码,被 BIOS 加载到0x00007C00 并执行。
当它被执行时就会把自己移动到绝对地址0x90000处,并把启动设备中后2kb字节代码(boot/setup.s)读入到内存0x90200处,而内核的其他部分则被读入到从地址0x10000的开始处。然后将控制权传递给boot/setup.s中的代码.这是另一个实时模式汇编程序。最终调用init/main.c中的main程序。上述的操作的源代码在boot/head.s中。
汇编程序这里不作分析。
4. 进程管理
关于进程,我的阅读源码主要是是linux/sched.h。
我们学过,进程控制块(PCB)的是进程管理的关键。一个进程是由一个进程控制块来描述的。那么首先需要做的就是找到这部分代码。在linux/sched.h中可以找到task_struct结构体,下面是截取了一小部分代码:
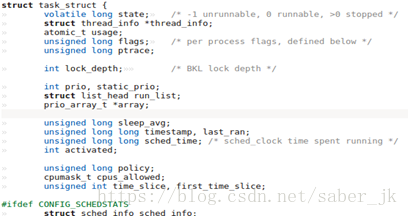
我们稍微看一下结构体内部结构变量的作用:
```
struct task_struct {
......
/* 进程状态 */
volatile long state;
/* 指向内核栈 */
void *stack;
/* 用于加入进程链表 */
struct list_head tasks;
......
/* 指向该进程的内存区描述符 */
struct mm_struct *mm, *active_mm;
........
/* 进程ID,每个进程(线程)的PID都不同 */
pid_t pid;
/* 线程组ID,同一个线程组拥有相同的pid,与领头线程(该组中第一个轻量级进程)pid一致,保存在tgid中,线程组领头线程的pid和tgid相同 */
pid_t tgid;
/* 用于连接到PID、TGID、PGRP、SESSION哈希表 */
struct pid_link pids[PIDTYPE_MAX];
........
/* 指向创建其的父进程,如果其父进程不存在,则指向init进程 */
struct task_struct __rcu *real_parent;
/* 指向当前的父进程,通常与real_parent一致 */
struct task_struct __rcu *parent;
/* 子进程链表 */
struct list_head children;
/* 兄弟进程链表 */
struct list_head sibling;
/* 线程组领头线程指针 */
struct task_struct *group_leader;
/* 在进程切换时保存硬件上下文(硬件上下文一共保存在2个地方: thread_struct(保存大部分CPU寄存器值,包括内核态堆栈栈顶地址和IO许可权限位),内核栈(保存eax,ebx,ecx,edx等通用寄存器值)) */
struct thread_struct thread;
/* 当前目录 */
struct fs_struct *fs;
/* 指向文件描述符,该进程所有打开的文件会在这里面的一个指针数组里 */
struct files_struct *files;
........
/*信号描述符,用于跟踪共享挂起信号队列,被属于同一线程组的所有进程共享,也就是同一线程组的线程此指针指向同一个信号描述符 */
structsignal_struct *signal;
/*信号处理函数描述符 */
structsighand_struct *sighand;
........
}
```
其中关于进程的状态分为两种,struct_task中成员state(关于运行的状态)和exit_state(关于退出的状态),参见下图:

5. 内存管理
首先,关于linux内存,Linux 把物理内存划分为3个层次来管理:存储节点(Node)、管理区(Zone)和页面(Page),并用3 个相应的数据结构来描述。
总的来说,有关内存管理的代码大部分都在mm中,但与特定体系结构相关的部分则保存在
arch/*/mm中,内存缺页处理代码在mm/memory.c中,内存映射和页缓冲代码在mm/filemap.c中,实现缓冲区缓存部分代码在mm/buffer.c中,页交换代码在mm/swap_state.c和mm/swapfile.c中。
下面我们把阅读重点放在这三个数据结构上。
a)page
正如处理器处理数据的基本单位是字,内核把页作为C管理的基本单位。线性地址被分成以固定长度为单位的组,称为page。
内核用struct page(定义在 include/linux/mm.h)结构体表示系统中的每一个物理页:

flags存放页的状态。 _count域表示该页的使用计数,如果该页未被使用,就可以在新的分配中使用它。
可以发现,page结构体描述的是物理页而非逻辑页,描述的是内存页的信息而不是页中数据。
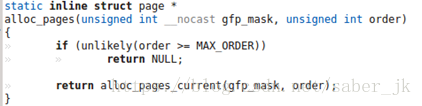
i) 获得页使用的接口是alloc_pages函数,我们来看下它的源码(位于linux/gfp.h中) :
ii) 当我们不再需要某些页时可以使用下面的函数释放它们:
__free_pages(struct page *page,unsigned int order)
__free_page
free_pages
free_page(unsigned longaddr, unsigned int order)
这些接口都在linux/gfp.h中。
b)zone
有些页是有特定用途的内核使用区的概念将具有相似特性的页进行分组。区是一种逻辑上的分组的概念,而没有物理上的意义。
区的实际使用和分布是与体系结构相关的。例如,在x86体系结构中主要分为3个区:ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM。
ZONE_DMA区中的页用来进行DMA时使用。ZONE_HIGHMEM是高端内存,其中的页不能永久的映射到内核地址空间,也就是说,没有虚拟地址。剩余的内存就属于ZONE_NORMAL区。
每个zone都用struct zone_struct 结构来表示,描述于include/linux/mmzone.h,具体定义见下面,笔者尝试注释了一些域的作用:
struct zone {
unsigned long free_pages; //在这个区中现有空闲页的个数
unsigned long pages_min, pages_low, pages_high;
//对这个区最少、此少及最多页面个数的描述
unsigned long lowmem_reserve[MAX_NR_ZONES];
struct per_cpu_pageset pageset[NR_CPUS];
spinlock_t lock; //用来保证对该结构中其它域的串行访问
struct free_area free_area[MAX_ORDER];
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
struct list_head active_list;
struct list_head inactive_list;
unsigned long nr_scan_active;
unsigned long nr_scan_inactive;
unsigned long nr_active;
unsigned long nr_inactive;
unsigned long pages_scanned;
int all_unreclaimable;
int temp_priority;
int prev_priority;
ZONE_PADDING(_pad2_)
wait_queue_head_t * wait_table;
unsigned long wait_table_size;
unsigned long wait_table_bits;
struct pglist_data *zone_pgdat; //本管理区所在的存储节点
struct page *zone_mem_map; //该管理区的内存映射表
unsigned long zone_start_pfn;
unsigned long spanned_pages;
unsigned long present_pages;
char *name; //该管理区的名字
}____cacheline_maxaligned_in_smp;
c)node
先看node的具体数据结构,描述于include/linux/mmzone.h:
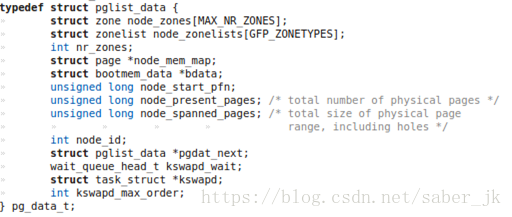
关于node,我查阅了一些资料,可以了解到node实际上和NUMA模型——非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型有关。
此处难以对此模型进行深究,简单摘要如下:
非一致存储器访问(NUMA)模式下,处理器被划分成多个”节点”(node), 每个节点被分配有的本地存储器空间. 所有节点中的处理器都可以访问全部的系统物理存储器,但是访问本节点内的存储器所需要的时间,比访问某些远程节点内的存储器所花的时间要少得多。
6. 虚拟文件系统
Linux虚拟文件系统(VFS)隐藏各种了硬件的具体细节,为所有的设备提供了统一的接口。而且,它独立于各个具体的文件系统,是对各种文件系统的一个抽象,它使用超级块super block存放文件系统相关信息,使用索引节点inode存放文件的物理信息,使用目录项dentry存放文件的逻辑信息。
我在include/linux/fs.h中找到了很多信息。
例如上述数据结构的定义

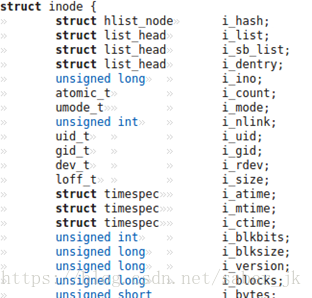
以及相关操作:

下面分析一下struct dentry的相关结构变量:
struct dentry {
unsigned int d_flags; //目录项缓存标识
seqcount_t d_seq;
struct hlist_bl_node d_hash;
struct dentry *d_parent;
struct qstr d_name;
struct inode *d_inode; //与该目录项关联的inode
unsigned char d_iname[DNAME_INLINE_LEN];
unsigned int d_count; //引用计数
spinlock_t d_lock;
conststruct dentry_operations *d_op; //目录项操作
struct super_block *d_sb; //这个目录项所属的文件系统的超级块
unsigned long d_time;
void *d_fsdata; //文件系统私有数据
struct list_head d_lru; //最近未使用的目录项的链表
union {
struct list_head d_child;
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; //本目录的所有孩子目录链表头
struct list_head d_alias;
};
Superblock:超级块,是文件系统最基本的元数据,它定义了文件系统的类型、大小、状态和其他信息等。Superblock对于文件系统是非常关键的,因此一般文件系统都会冗余存储多份。
inode:包含了一个文件的元数据,如文件所在数据块等。这里需要注意Linux中的所有对象均为文件:实际的文件、目录、设备等等。一个inode基本包含:所有权(用户、组)、访问模式(读、写、执行)和文件类型等,但不包含文件名。
dentry:将inode号和文件名联系起来,dentry还保存目录和其子对象的关系,用于文件系统的变量。dentry还起着缓存的作用,缓存最常使用的文件以便于更快捷的访问。
7. 总结
最初,拿到源码,感觉让人无从下手。内容多,代码长,各种意义不明的文件,看起来很十分吃力。然后,查阅了很多资料,不断浏览文件目录,走马观花地看了很多代码。就本人而言,虽然还是有很多不明白的地方,阅读报告也肯定有很多疏漏错误之处,但是还是学习到了很多东西。