LMDB介紹
Caffe使用LMDB來存放訓練/測試用的數據集,以及使用網絡提取出的feature(為了方便,以下還是統稱數據集)。數據集的結構很簡單,就是大量的矩陣/向量數據平鋪開來。數據之間沒有什麼關聯,數據內沒有復雜的對象結構,就是向量和矩陣。既然數據並不復雜,Caffe就選擇了LMDB這個簡單的數據庫來存放數據。
LMDB的全稱是Lightning Memory-Mapped Database,閃電般的內存映射數據庫。它文件結構簡單,一個文件夾,裡面一個數據文件,一個鎖文件。數據隨意複製,隨意傳輸。它的訪問簡單,不需要運行單獨的數據庫管理進程,只要在訪問數據的代碼裡引用LMDB庫,訪問時給文件路徑即可。
圖像數據集歸根究底從圖像文件而來。既然有ImageDataLayer可以直接讀取圖像文件,為什麼還要用數據庫來放數據集,增加讀寫的麻煩呢?我認為,Caffe引入數據庫存放數據集,是為了減少IO開銷。讀取大量小文件的開銷是非常大的,尤其是在機械硬盤上。 LMDB的整個數據庫放在一個文件裡,避免了文件系統尋址的開銷。 LMDB使用內存映射的方式訪問文件,使得文件內尋址的開銷非常小,使用指針運算就能實現。數據庫單文件還能減少數據集複製/傳輸過程的開銷。一個幾萬,幾十萬文件的數據集,不管是直接複製,還是打包再解包,過程都無比漫長而痛苦。 LMDB數據庫只有一個文件,你的介質有多塊,就能複制多快,不會因為文件多而慢如蝸牛。
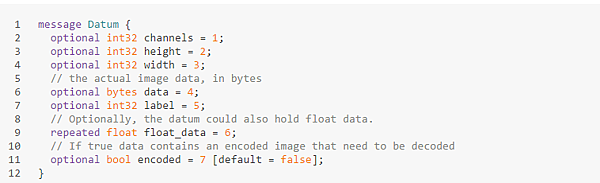
Datum數據結構
首先需要注意的是,Caffe並不是把向量和矩陣直接放進數據庫的,而是將數據通過caffe.proto裡定義的一個datum類來封裝。數據庫裡放的是一個個的datum序列化成的字符串。 Datum的定義摘錄如下:
所以要使用的話 首先要用pip 下載 lmdb
由於小編已經安裝過了
所以顯示already satisfied
![]()
程式碼:
1.從 array 做出 lmdb
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
import numpy as npimport lmdbimport caffeN = 1000# Let's pretend this is interesting dataX = np.zeros((N, 3, 32, 32), dtype=np.uint8)print "x shape is :",X.shape[1]y = np.zeros(N, dtype=np.int64)print "y shape is :",y.shape# We need to prepare the database for the size. We'll set it 10 times# greater than what we theoretically need. There is little drawback to# setting this too big. If you still run into problem after raising# this, you might want to try saving fewer entries in a single# transaction.map_size = X.nbytes * 10print "map_size is:3*32*32*1000*10 --",map_sizeenv = lmdb.open('mylmdb', map_size=map_size)with env.begin(write=True) as txn: # txn is a Transaction object for i in range(N): datum = caffe.proto.caffe_pb2.Datum() #set channels=3 datum.channels = X.shape[1] #set height =32 datum.height = X.shape[2] #set width = 32 datum.width = X.shape[3] datum.data = X[i].tobytes() # or .tostring() if numpy < 1.9 datum.label = int(y[i]) str_id = '{:08}'.format(i) # The encode is only essential in Python 3 txn.put(str_id.encode('ascii'), datum.SerializeToString()) |
產生的資料如下:

2.從lmdb讀取資料:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import caffeimport lmdblmdb_env = lmdb.open('mylmdb')lmdb_txn = lmdb_env.begin()lmdb_cursor = lmdb_txn.cursor()datum = caffe.proto.caffe_pb2.Datum()i=0for key, value in lmdb_cursor: i=i+1 datum.ParseFromString(value) label = datum.label data = caffe.io.datum_to_array(datum) print "This is counter:",i print "This is data: ",data.shape print "This is label:",label,"
" |
運行結果如下:
參考資料:
http://darren1231.pixnet.net/blog/post/328463403-%E5%AD%B8%E6%9C%83%E5%81%9A%E5%87%BA%E8%87%AA%E5%B7%B1%E7%9A%84%E6%95%B8%E6%93%9A%E9%9B%86%28imdb%29--caffe
http://deepdish.io/2015/04/28/creating-lmdb-in-python/
http://rayz0620.github.io/2015/05/25/lmdb_in_caffe/
https://lmdb.readthedocs.io/en/release/
http://stackoverflow.com/questions/33117607/caffe-reading-lmdb-from-python