http://blog.csdn.net/l281865263/article/details/50278745
本栏目(Machine learning)包括单参数的线性回归、多参数的线性回归、Octave Tutorial、Logistic Regression、Regularization、神经网络、机器学习系统设计、SVM(Support Vector Machines 支持向量机)、聚类、降维、异常检测、大规模机器学习等章节。内容大多来自Standford公开课machine learning中Andrew老师的讲解和其他书籍的借鉴。(https://class.coursera.org/ml/class/index)
第十四讲. 机器学习应用举例之——Photo OCR
=============================
(一)、Photo OCR Pipeline
(二)、滑动窗 Sliding Window
(三)、人造数据 Artificial Data
(四)、Ceiling Analysis
=====================================
算法流程:
Image ----> Text Detection ---->Character Segmentation ---->Character Recognition
有些还会有Spelling Correction,比如下图中当把“Clean”中的字母“l”识别成数字“1”时,可通过单词上下文纠正回来。

=====================================
(二)、滑动窗 Sliding Window
一、滑动窗概念
滑动窗是一种遍历图像从而获取正负样本的方法。可根据正样本的size,来选取不同尺度的滑动窗,如下图:

二、Text Detection
1、训练阶段
通过滑动窗,可获取如下图所示的Text Detection算法训练所需的正负样本。当滑动窗所采样本正中间位置是某个字符,就认为是正样本,否则为负样本。

2、测试阶段
如下图
首先,用滑动窗遍历图像,并用上面训练的classifer对滑动窗所选的样本进行二分类,会得到左下角的confidence map,每个像素的灰度值大小描述了该像素是字符的可能性/概率/confidence。但这并非我们要的输出,我们要输出的是表示字符边界的bounding box。
然后,为了得到上述bounding box,用到一个操作叫做expansion,扩张。目的是为了把断续的单个字符串联起来便于画bounding box,如右下图所示。举例一个简单的策略是,对于左下图每个白色的像素,将其周围5或10个pixel范围内的pixel全都染成白色。
最后,如右下图所示,将每个连通域标一个bounding box出来,规则是高度和宽度符合一行字符的大小,比如最下面两个case因为太窄而被去掉,最终输出三个box。

三、Character Segmentation
用滑动窗(只需要在一个维度上进行滑动)对上面输出的detection结果进行遍历,如下图所示,滑动窗中间可做字符分割的为正样本,否则为负样本。

四、Character Recognition
这个理解起来很简单,就不详述了。
=====================================
(三)、人造数据 Artificial Data
增加数据量是在模型具有low bias的前提下继续提高模型性能的一个有效方法。
增加数据量的办法:一是让人去标注更多的数据,二是产生一些人造数据。
人造数据又有两种生成方式,一是前景背景合成法,二是数据畸变扰动。
一、前景背景合成法
如下图所示,左边是真实数据,右边是由背景和前景合成的数据。所谓背景前景合成法,指的是拿真实的字符前景和真实的非字符背景,贴合在一起,就生成一个假数据。这个假数据看起来和左边的真数据并无太大差异,完全可以参与模型训练。

二、数据畸变扰动
如下图所示,对原始真实数据做一些类似旋转、缩放等畸变变换,增加数据扰动,也可以生成一些数据。这样做不仅可以增大数据量,而且可以让模型具有例如旋转不变的鲁棒性,从而对数据畸变具有很强的适应性。
一定要注意一点,所增加的数据扰动类型,一定要是测试数据中存在的,如果只是加一些随机的无意义的噪声,对模型性能的提高并无帮助。比如,测试数据中并没有字符上下或左右倒置的case,如果硬是人造出一些这样的训练数据做正样本,势必会让模型感到困惑confused(如果负样本中恰好有长得像倒置的字符的)。

=====================================
(四)、Ceiling Analysis
Ceiling Analysis,可以直观地将其等同于最优分析,即找到这件事情的最好情况,你就可以知道现在这种条件下能达到的上限。如果对上限满意,那么就优化当前的方案,逼近上限;如果对上限都不满意,那就不用在当前的方案上浪费时间了,另谋他路。
我们可以用Ceiling Analysis这种方法分析Photo OCR pipeline里的各个模块,发现系统的短板,以决定接下来做什么。下面说说Ceiling Analysis的分析思路,如下图所示。
首先要知道,每个模块都有自身的准确率,这个准确率是独立的,与其他模块无关。
当前整个系统的输出准确率是72%(character recognition)
1、首先,确保text detection模块100%的准确率(人为的标定好这是text文本区域),即该模块的输出就是ground truth。这时测试系统的准确率,即在最优的text detection模型的前提下,系统可以达到的准确率上限,为89%,上涨17%。说明当前的text detection模块性能还有较大的提升空间。
2、然后,确保character segmentation模块100%的准确率(人工给出正确的字符分割结果),同上。在最优的text detection模型和character segmentation模型的前提下,系统可以达到的准确率上限,为90%,仅上涨1%。说明当前的character segmentation模型就算优化到100%的准确率,也只对系统准确率造成1%的影响,可见系统短板并不在这里。
3、最后,确保character recognition模块100%的准确率,同上。当所有模块都输出ground truth时,系统输出准确率自然达到100%,上涨10%. 这说明当前的character recognition模型的性能也有着一定的提升空间。
分析完毕,那么接下来的工作,在text detection和character recognition这两个模块上下工夫就好了。

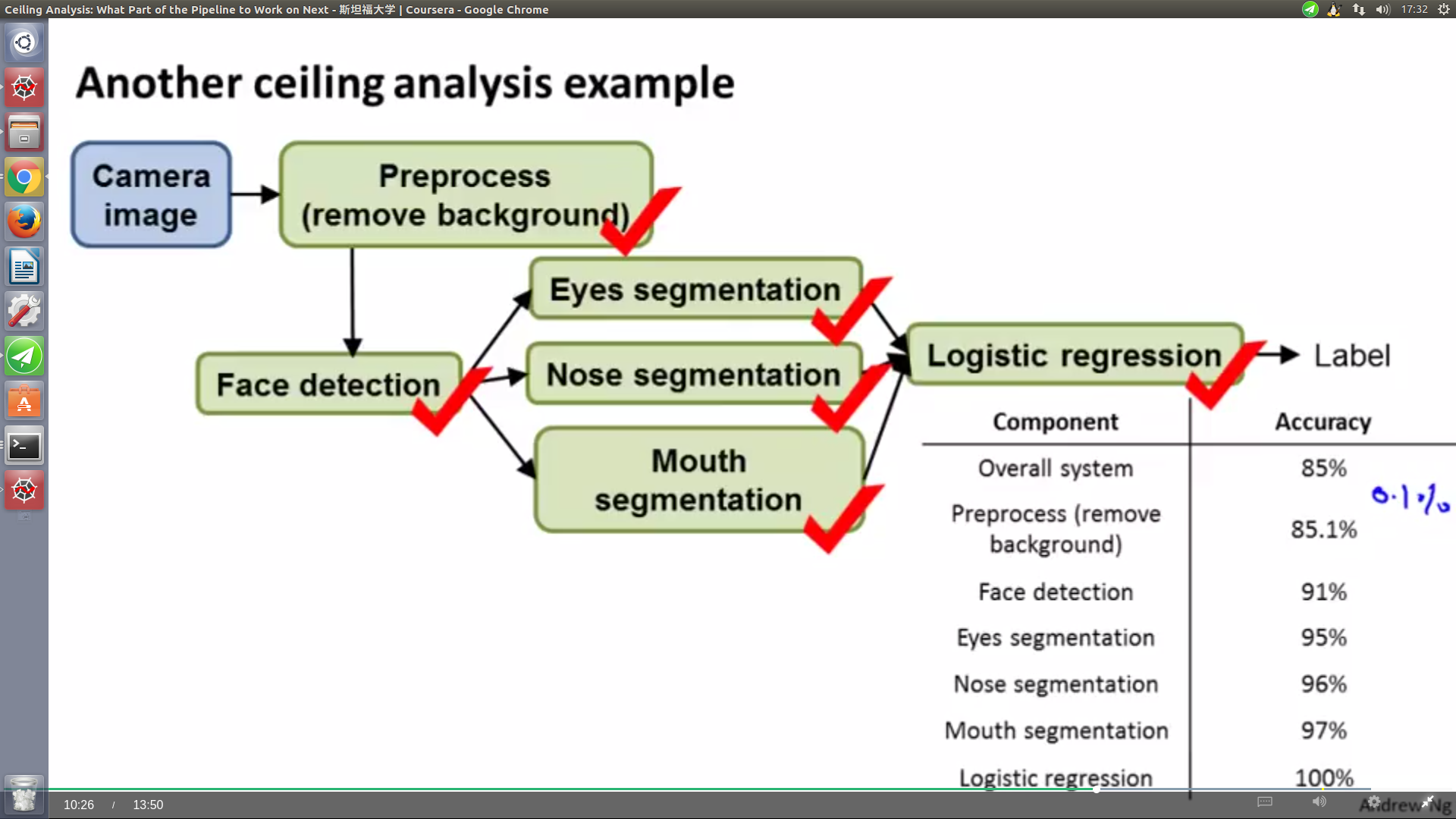 人脸识别:
人脸识别:
1. 整个系统的准确性达到了85%;
2. 预处理,对前景和背景进行分割(手动把背景删掉),观察准确率提高多少==>0.1%===>说明即使你把背景分割做到极致,也只能提高一点点性能;
3. 再遍历测试集,给出正确的脸部检测区域,然后分别进行眼镜嘴巴和鼻子的分割,再给出最终正确逻辑回归分类====>100%
4. 随着给测试集提供的正确标签越来越多,整个系统的表现越来越好,也可以看出提高哪一部分的性能可以对整个系统性能提供最大化的价值。