问题:从食品伙伴网上爬取txt,先爬取了<a>标签下的链接url,保存在txt中,然后遍历txt中的url,通过selenium.webdriver.Chrome().get(url)得到url页面的内容(就是get(url)出错了),然后取所需要的。错误如下:
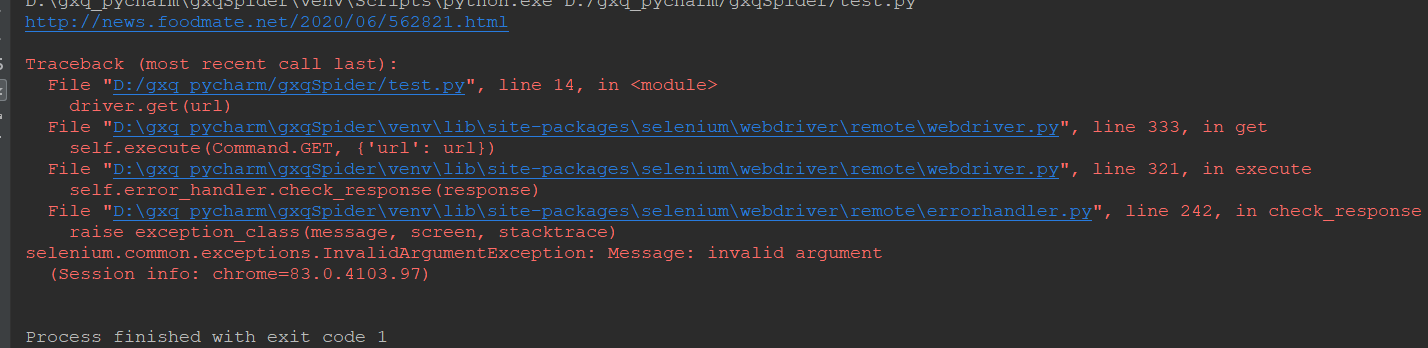
百度解决啊,找到了一个类似问题的博客还解决不了我的问题,只能自己捣鼓。
遍历url,get(url)关键代码如下:
urls = open("finalUrls.txt", 'r', encoding="utf8")
driver = webdriver.Chrome("E:\chromedriver_win32\chromedriver.exe")
for url in urls:
driver.get(url)
这始终发现不了错误,找到个解决方法,就是取出来的url放在一个list中,然后遍历这个列表取get,结果还是不行。代码如下:
urls = open("finalUrls.txt", 'r', encoding="utf8")
urls = urls.read().split() # 加了此行,就是放在了list中 driver = webdriver.Chrome("E:\chromedriver_win32\chromedriver.exe") for url in urls: driver.get(url)
接着调,自己捣鼓,是不是把url转成str就行了,好像本就是str,试试吧,不怕啥。结果不行。
接着试:在for循环里加入了split,即url = url.split()
错误依旧,但是发现一个好玩意,如下:
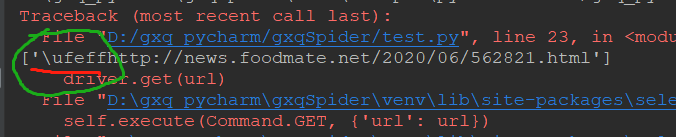
然后就想啊,是不是因为这么个东西搞得我get不了啊。百度去, https://www.cnblogs.com/chongzi1990/p/8694883.html
说是编码的问题,我一开始保存的时候是utf8啊,就按照人家的试试呗,utf-8-sig,然后问题解决。。。
urls = open("finalUrls.txt", 'r', encoding="utf-8-sig")
driver = webdriver.Chrome("E:\chromedriver_win32\chromedriver.exe")
for url in urls:
driver.get(url)
总结:就是ufeff这么个东西搞我