简介
随机梯度下降


一般梯度(最陡下降方向)

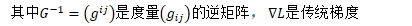
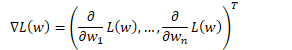
当参数面具有隐含的特定结构时,最陡的方向并非一般梯度,而是自然梯度。
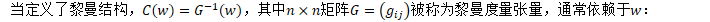
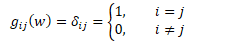
在欧几里得正交空间中,G是单位矩阵I。
自然梯度
自然梯度表示延着雷曼(Riemannian)参数面的梯度迈出一步,这相当于在常规参数空间的一条弯曲路径,并且很难计算。

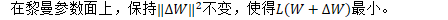
《基于自然梯度以及模型平均的DNNs并行训练》的部分章节翻译与补充
将替换SGD中的标量学习率替换为矩阵形式
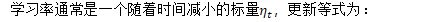
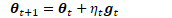
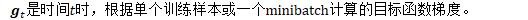
可以将该标量替换为一个对称正定矩阵:
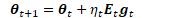

通常,学习率矩阵不应该是当前训练样本的函数,否则将收敛至局部最优。例如,对于特定类型的训练数据,过小的矩阵将使得数据权重降低,导致学习出现偏差。
逆Fisher矩阵是合适的学习率矩阵
Fisher矩阵的定义与 学习一个分布 十分相关。
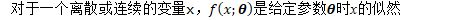
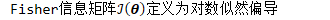
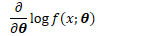
的外积期望
在信息论中,该偏导被称为"得分"。
使用Fisher矩阵的部分理由是,在某些条件下,Fisher矩阵等价于Hessian矩阵:
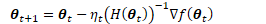
这相当于牛顿法,这也是为什么逆Fisher矩阵表示一个好的梯度下降方向。

但即使上述条件无法满足,在某种维度的意义上,Fisher信息矩阵与Hessian矩阵相同
即,考虑参数化的变换,对梯度的转换方式是相同的,这样,Fisher信息矩阵的逆任然是一个好的学习率矩阵。
需要对Fisher矩阵进行近似
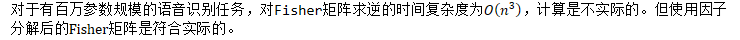
Roux et al., 2007将Fisher矩阵分解为多个对角块,其中每个对角块用一个低秩矩阵来近似。
Bastian et al., 2011也使用了对角块的思想,一个对角块对应于一个权重矩阵;本文的方法使用了相同的思想。
在Yang & Amari, 1997未发表的手稿中,在某些假设情况下,单隐层神经网络的Fisher矩阵有克罗内克积的形式。
克罗内克积也出现在本文的 Fisher矩阵的因子分解中
注意:若接受每次迭代中显著增加的时间,也可以使用若干种不对Fisher信息矩阵进行因子分解的自然梯度方法。比如,Pascanu & Bengio, 2013使用了截断牛顿法对 与Fisher矩阵的逆相乘 进行近似。
需要对Fisher矩阵进行近似。
对Fisher矩阵进行因子分解


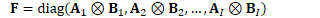

如何估计Fisher矩阵
- 简单方法:根据当前训练的minibatch中的其他样本估计Fisher矩阵(这意味着要往minibatch中添加额外的样本,用于估计Fisher矩阵);
- 在线方法:根据所有之前的minibatches估计Fisher矩阵,使用一个遗忘因子降低较早的minbatches的权重;
对向量的计算
虽然我们将Fisher矩阵描述为一个克罗内克积,但是,在代码中,我们无需显式地构建这一乘积。
对于一个线性映射,第i个样本的前向计算与梯度反向传播可表示为(以行为主序,与Kaldi一致):
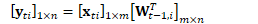
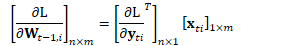

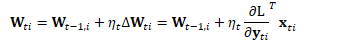
其中
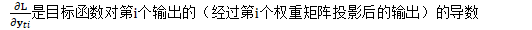
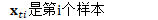
在自然梯度方法中,上式被修改为:
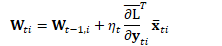
其中:
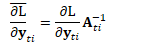

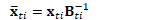

即:
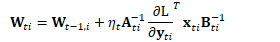

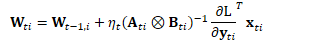
由于两个向量的外积可看作是矩阵的克罗内克积的特殊情况:
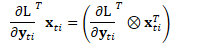
因此,上式可写为:
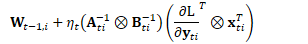
根据克罗内克积的混合乘积性质:
如果A、B、C和D是四个矩阵,且矩阵乘积AC和BD存在,那么:
|
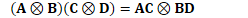
上式可写为:
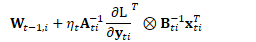
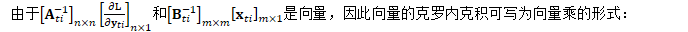

对minibatches的计算
实际上,并不是一次处理一个训练样本,而是以minibatch为单位进行处理。
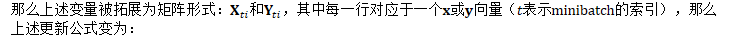
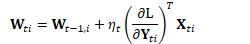
在自然梯度方法中:
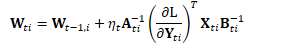
或可简化为:
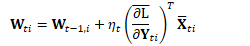
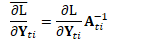
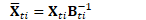
用编程术语,我们可以将自然梯度的核心代码接口描述为:

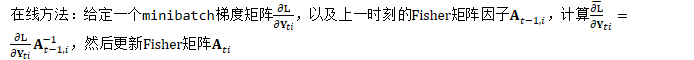
这相当于调用OnlineNaturalGradient::PreconditionDirections(CuMatrixBase<BaseFloat> *X_t, BaseFloat *scale)

Y与A的计算类似。对于每个minibatch,需要调用上述接口2I次。
对因子进行缩放
在上述两种自然梯度更新方法中,都需要避免Fisher矩阵乘过度影响更新的尺度(与标注SGD相比)。原因如下:
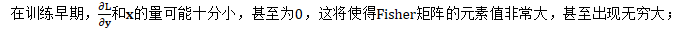
- 对于传统的收敛证明方法,要求提前知道 学习率矩阵的组分的特征值的上界和下界,但对于未修改的Fisher矩阵,无法保证其上下界;
- 从经验上,若使用未缩放的实数Fisher矩阵,难以避免参数出现发散;

但这也带来了一个收敛证明上的问题。缩放后,每个样本能够对自身的学习率矩阵产生影响(由样本尺度影响缩放因子,进一步影响学习率矩阵),文献的前面章节提到过,不能使得 逐样本学习率 是 样本本身的函数。然而,我们不认为这个问题会影响实际的训练,因为我们从不使用小于100的minibatch,因此对结果造成的偏差很小。
对Fisher矩阵通过单位矩阵进行平滑
在上述两种自然梯度更新方法中,在对因子进行取逆之前,会加上若干倍的单位矩阵,以实现对因子矩阵的平滑处理。在简单方法中,这是有必要的,因为从minibatch中估计的Fisher矩阵可能不是满秩的(非满秩矩阵没有对应的逆矩阵);而在在线方法中则不需要这么做,因为Fisher矩阵中已经包含了数倍的单位矩阵。不过,我们发现,加上数倍的单位矩阵后,能提升SGD训练的收敛性。

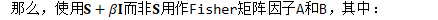
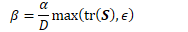
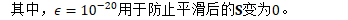
也就是说,我们以S的对角元素的平均的α倍,对单位矩阵进行缩放,然后对Fisher矩阵进行平滑。

实验结果与结论
与SGD相比,NG-SGD能使得训练收敛得更好,识别率上好2个点。
当多机数N小于4时,参数平均方法能取得线性的训练速度提升
当多机数N大于4时,参数平均方法能取得次线性的训练速度提升
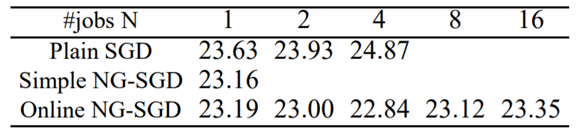
在单机或多机的情况下,在线NG-SGD均优于普通SGD
单机训练时,NG-SGD比SGD好1.86%
多机训练时,NG-SGD比SGD好3.89-8.16%
NG-SGD比SGD好的原因:
NG避免产生较大尺度的梯度,且对训练集的使用顺序更鲁棒。
Pascanu & Bengio, 2013
参考文献
- Amari, Shun-Ichi. "Natural gradient works efficiently in learning." Neural computation 10.2 (1998): 251-276.
- Povey, Daniel, Xiaohui Zhang, and Sanjeev Khudanpur. "Parallel training of DNNs with natural gradient and parameter averaging." arXiv preprint arXiv:1410.7455 (2014).