简介
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也因此而产生。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
Tess4J是对Tesseract OCR API.的Java JNA 封装。使java能够通过调用Tess4J的API来使用Tesseract OCR。支持的格式:TIFF,JPEG,GIF,PNG,BMP,JPEG,and PDF
Tesseract 的github地址:https://github.com/tesseract-ocr/tesseract
Tess4J的github地址:https://github.com/nguyenq/tess4j
Tess4J API 提供的功能:
- 直接识别支持的文件
- 识别图片流
- 识别图片的某块区域
- 将识别结果保存为 TEXT/ HOCR/ PDF/ UNLV/ BOX
- 通过设置取词的等级,提取识别出来的文字
- 获得每一个识别区域的具体坐标范围
- 调整倾斜的图片
- 裁剪图片
- 调整图片分辨率
- 从粘贴板获得图像
- 克隆一个图像(目的:创建一份一模一样的图片,与原图在操作修改上,不相 互影响)
- 图片转换为二进制、黑白图像、灰度图像
- 反转图片颜色
创建maven项目
pom中引用jar包
<dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>4.5.1</version> </dependency>
下载语言库文件
语言库下载地址:https://github.com/tesseract-ocr/tessdata
其中chi_sim.traineddata为中文语言库,eng.traineddata为英文语言库。
在任意地方创建一个文件夹tessdata,将下载的chi_sim.traineddata 和 eng.traineddata语言包存放在该目录下,也可以直接存放到自己项目的resources/tessdata目录下。
PS:后期的OCR样本训练,实际上就是制作生成自己的语言库文件
代码示例
// 识别图片的路径(修改为自己的图片路径) String path = "D:\test.png"; File file = new File(path); ITesseract instance = new Tesseract(); //获得Tesseract的文字库,设置语言库位置 URL tessdataPath = ClassLoader.getSystemResource("tessdata"); instance.setDatapath(tessdataPath.getPath().substring(1)); //chi_sim :简体中文, eng:英文 根据需求选择语言库 instance.setLanguage("eng"); String result = null; try { long startTime = System.currentTimeMillis(); result = instance.doOCR(file); long endTime = System.currentTimeMillis(); System.out.println("Time is:" + (endTime - startTime) + " 毫秒"); } catch (TesseractException e) { e.printStackTrace(); } System.out.println("result: "); System.out.println(result);
测试图片:
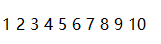
结果:
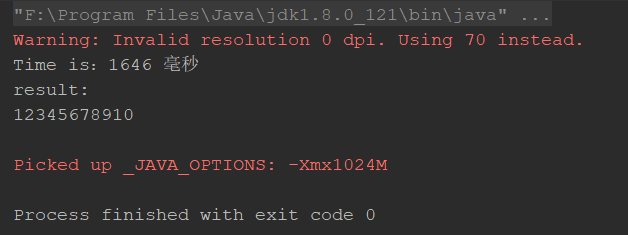
参考: