简介
Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。 Tesseract最初由HP公司开发,后来由Google维护。
下载
从https://github.com/UB-Mannheim/tesseract/wiki下载tesseract安装包。
从https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/下载jTessBoxEditor训练工具。
ps:由于jTessBoxEditor是用Java开发的,需要安装Java虚拟机才能运行。
使用默认语言库识别
Tesseract安装成功后会在相应磁盘上生成一个Tesseract-OCR目录。通过目录下的tesseract.exe程序就可以对图像字符进行识别了。
准备待识别的图像

打开cmd命令行,定位到Tesseract-OCR目录,输入命令:
tesseract.exe test.jpg output_test -l eng
【语法】: tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…]
imagename为目标图片文件名,需加格式后缀;outputbase是转换结果文件名;lang是语言名称(在Tesseract-OCR中tessdata文件夹可看到以eng开头的语言文件eng.traineddata),如不标-l eng则默认为eng(英语)。
打开识别结果

识别率还不是很高,那有没有什么方法来提供识别率呢?Tesseract提供了一套训练样本的方法,用以生成自己所需的识别语言库。
样本训练
安装jTessBoxEditor
将之前下载的安装包解压安装即可。
准备样本图片
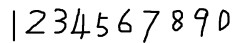
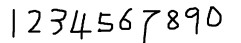
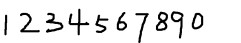
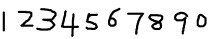

合并样本图像
运行jTessBoxEditor工具,在点击菜单栏中Tools--->Merge TIFF。在弹出的对话框中选择样本图像(按Shift选择多张),合并成num.font.exp0.tif文件
生成Box File文件
将num.font.exp0.tif文件复制到Tesseract-OCR安装目录,执行命令
tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
生成的BOX文件为num.font.exp0.box,BOX文件为Tessercat识别出的文字和其坐标。

注:Make Box File 文件名有一定的格式,不能随便乱取名字,命令格式为:
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
文字校正
运行jTessBoxEditor工具,点击菜单栏中Box Editor--->Open,在弹出的对话框中选择之前生成的num.font.exp0.tif,点击打开(必须将上一步生成的.box和.tif样本文件放在同一目录)。
如下图所示。可以看出有些字符识别的不正确,可以通过该工具手动对每张图片中识别错误的字符进行校正。校正完成后保存即可。

定义字体特征文件
Tesseract-OCR3.01以上的版本在训练之前需要创建一个名称为font_properties的字体特征文件。
font_properties不含有BOM头,文件内容格式如下:
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
其中fontname为字体名称,必须与[lang].[fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
这里在样本图片所在目录下创建一个名称为font_properties的文件,用记事本打开,输入以下下内容:
font 0 0 0 0 0
这里全取值为0,表示字体不是粗体、斜体等等。
生成语言文件
在Tesseract-OCR目录下创建一个批处理文件,输入如下内容:
rem 执行改批处理前先要目录下创建font_properties文件 echo Run Tesseract for Training.. tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train echo Compute the Character Set.. unicharset_extractor.exe num.font.exp0.box mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr echo Clustering.. cntraining.exe num.font.exp0.tr echo Rename Files.. rename normproto num.normproto rename inttemp num.inttemp rename pffmtable num.pffmtable rename shapetable num.shapetable echo Create Tessdata.. combine_tessdata.exe num.
num.traineddata便是最终生成的语言文件,将生成的num.traineddata拷贝到Tesseract-OCR-->tessdata目录下。可以用它来进行字符识别了。
使用训练后的语言库识别
用训练后的语言库识别test.jpg文件, 打开命令行,定位到Tesseract-OCR目录,输入命令:
tesseract.exe test.jpg result -l num
识别结果如如图所示,可以看到识别率提高了不少。

参考: