- 什么是Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。本质是将SQL转换为MapReduce程序。
- 适用场景
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
- Hive与传统数据库对比
| Hive | RMDBS | |
| 查询语言 | HQL | SQL |
| 数据存储位置 | HDFS | Raw Device 或 Local FS |
| 数据格式 | 用户定义 | 系统决定 |
| 数据更新 | 不支持 | 支持 |
| 索引 | 无 | 有 |
| 执行 | MapReduce | Executor |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高 | 低 |
| 数据规模 | 大 | 小 |
- Hive架构图
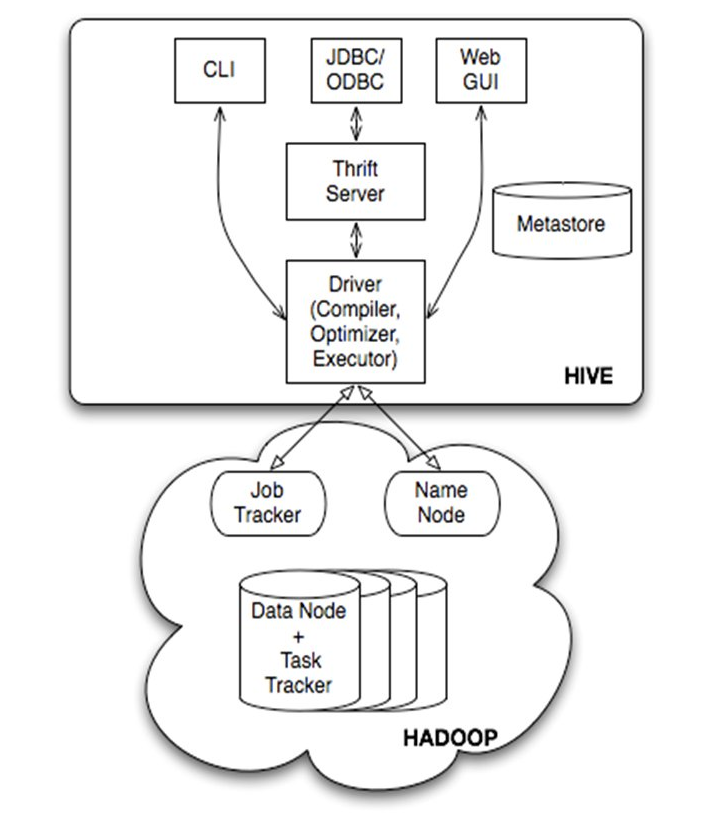
- Hive基本组件
用户接口
用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
元数据存储
Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
Hadoop
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)。
- Hive的特点
- 关系数据库里,表的加载模式是在数据加载时候强制确定的(表的加载模式是指数据库存储数据的文件格式),如果加载数据时候发现加载的数据不符合模式,关系数据库则会拒绝加载数据,这个就叫“写时模式”,写时模式会在数据加载时候对数据模式进行检查校验的操作。Hive在加载数据时候和关系数据库不同,hive在加载数据时候不会对数据进行检查,也不会更改被加载的数据文件,而检查数据格式的操作是在查询操作时候执行,这种模式叫“读时模式”。在实际应用中,写时模式在加载数据时候会对列进行索引,对数据进行压缩,因此加载数据的速度很慢,但是当数据加载好了,我们去查询数据的时候,速度很快。但是当我们的数据是非结构化,存储模式也是未知时候,关系数据操作这种场景就麻烦多了,这时候hive就会发挥它的优势。
- 关系数据库一个重要的特点是可以对某一行或某些行的数据进行更新、删除操作,hive不支持对某个具体行的操作,hive对数据的操作只支持覆盖原数据和追加数据。Hive也不支持事务和索引。更新、事务和索引都是关系数据库的特征,这些hive都不支持,也不打算支持,原因是hive的设计是海量数据进行处理,全数据的扫描时常态,针对某些具体数据进行操作的效率是很差的,对于更新操作,hive是通过查询将原表的数据进行转化最后存储在新表里,这和传统数据库的更新操作有很大不同。
- Hive也可以在hadoop做实时查询上做一份自己的贡献,那就是和hbase集成,hbase可以进行快速查询,但是hbase不支持类SQL的语句,那么此时hive可以给hbase提供sql语法解析的外壳,可以用类sql语句操作hbase数据库。
参考:
《hadoop海量数据处理技术详解与项目实战》
http://www.cnblogs.com/sharpxiajun/archive/2013/06/02/3114180.html
私塾在线中关于Hive的文章