Compute Shader 可以在通常的渲染管线之外运行,执行一些大量的通用计算(GPGPU algorithms),因此可以联想到把一些大量相互之间没有关联的计算转移到GPU中进行,以减轻CPU的工作量。
Compute Shader 实例
#pragma kernel FillWithRed
RWTexture2D<float4> res;
[numthreads(1,1,1)]
void FillWithRed (uint3 dtid : SV_DispatchThreadID)
{
res[dtid.xy] = float4(1,0,0,1);
}以上是一个简单的Compute Shader,大概解释一下就是,
#pragma kernel FillWithRed声明了主函数叫 FillWithRed,有点类似VF Shader的#pragma vertex vertRWTexture2D<float4> res;声明了一个可读写的Texture2D对象,RW是Read Write的缩写,这个对象用来存储Compute Shader的计算结果,这里计算结果是float4类型的数据。在C#代码中对应的也要有一个可读写的Texture对象,一般情况是定义一个RenderTexture,通过ComputeShader.SetTexture方法把RenderTexture和RWTexture2D关联起来。Compute Shader 执行结束后,C#中的RenderTexture也相应被改变。[numthreads(1,1,1)]声明XYZ三个维度线程组中的线程数量,即 thread number per group。对应的C#代码中在调用Compute Shader时也会指定XYZ三个维度的线程组的数量,即 group number。这行代码意思是xyz线程组上都只有1个线程。res[dtid.xy] = float4(1,0,0,1);存储计算结果到Texture2D对象的像素中,这里所有像素都存储同一个数值float4(1,0,0,1),那么在C#中如果读取对应的RenderTexture对象应该会得到一张纯红色的图片。注意这里的dtid.xy并不是纹理坐标,范围不是[0,1],dtid.xy的范围是,x在[0,XGroupNumThreadNumPerXGroup],y在[0, YGroupNumThreadNumPerYGroup],XGroupNum在C#中指定,ThreadNumPerXGroup在Shader中指定。
Compute Shader 的使用
计算结果保存到Texture中
Compute Shader 大概能做的事情已经很清晰了,现在就来实际试用下,先从简单一点的开始,刚才实例里的shader只是给所有像素存储了同一个float4数值,并没有进行什么计算,这样并不符合Compute Shader的名号,所以这里加一点简单的计算,实现在Compute Shader中给一个贴图设置颜色,然后在C#中把这张图设置到一个Cube上。
效果如图: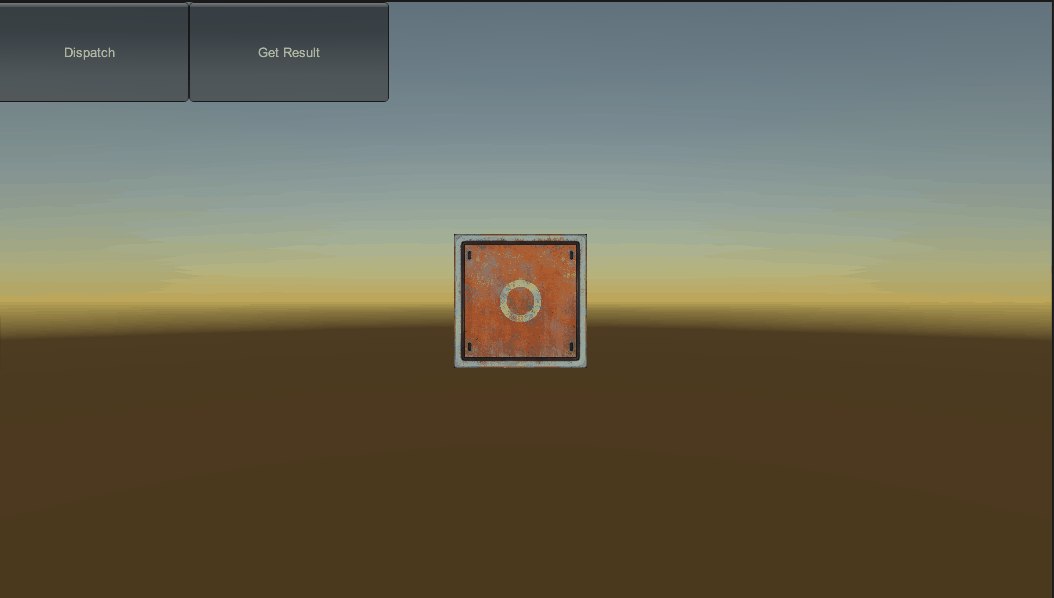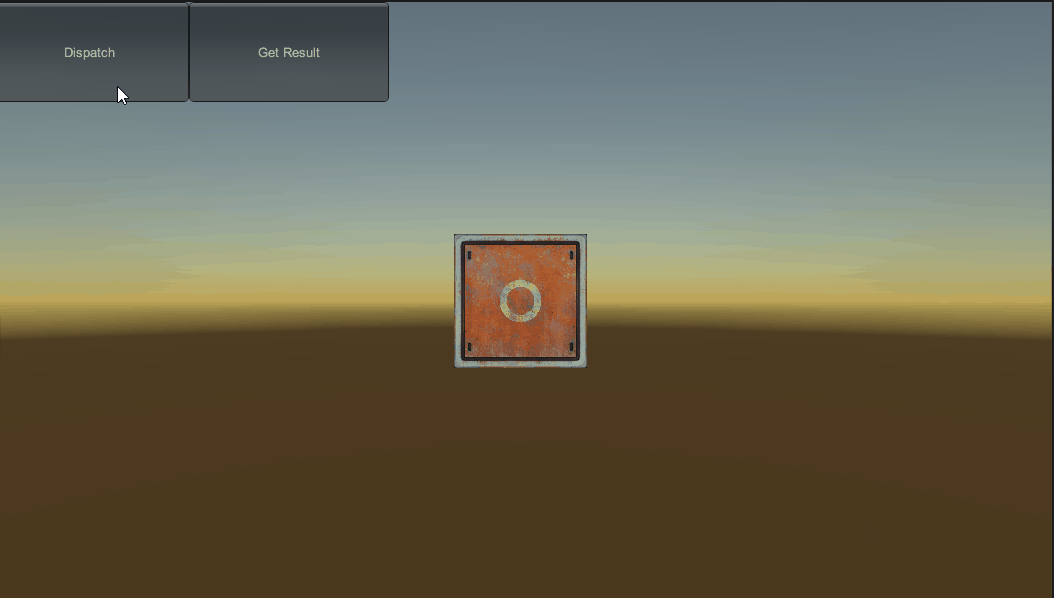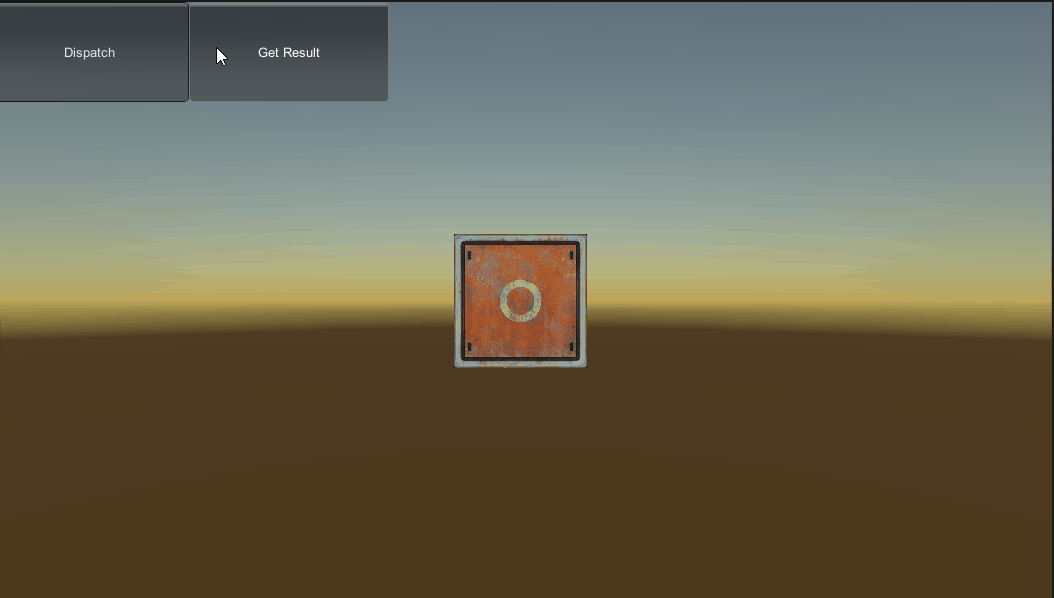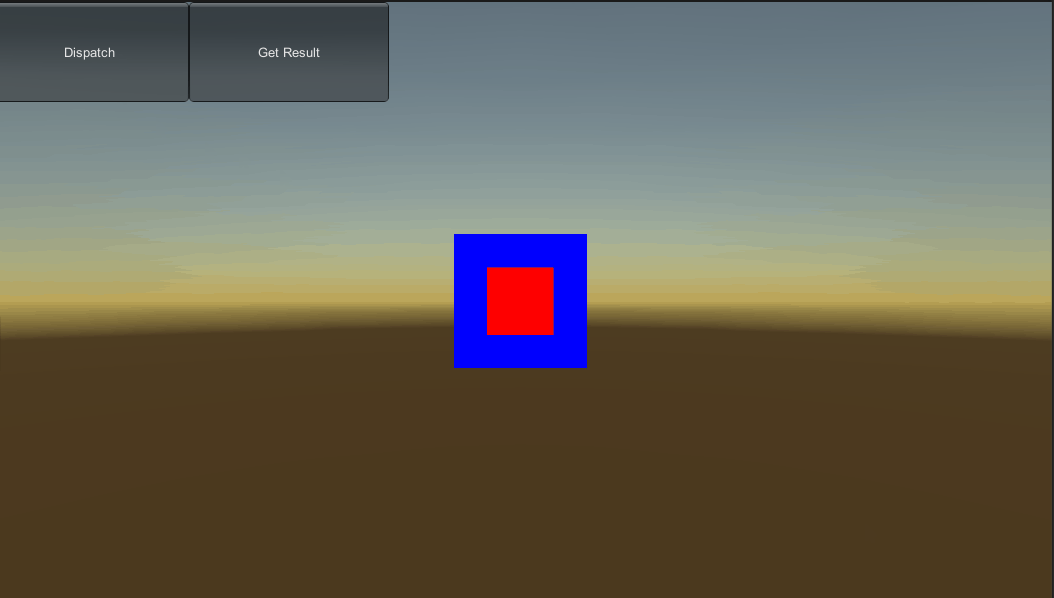
C# 部分:
m_rt = new RenderTexture(Width, Height, 0, RenderTextureFormat.ARGB32);
m_rt.enableRandomWrite = true;
m_rt.Create();
computeShader.SetTexture(kernelIndex, "ResultTex", m_rt);
// 在Shader中需要用到X维和Y维的数据作为坐标去读取和设置Texture2D的像素,因此需要给X维和Y维的thread group设置数值,Z维的thread group数量为1即可 //
computeShader.Dispatch(kernelIndex, 32, 32, 1);Shader 部分:
#pragma kernel CSMain_Texture
RWTexture2D<float4> ResultTex;
[numthreads(32,32,1)]
void CSMain_Texture (uint3 id : SV_DispatchThreadID)
{
float r = (id.x > 256 && id.x < 768 && id.y > 256 && id.y < 768) ? 1 : 0;
float b = 1 - r;
ResultTex[id.xy] = float4(r, 0, b, 1);
}以上代码中需要注意的地方有:
- 创建的RenderTexture尺寸为1024*1024
- C#中的
computeShader.Dispatch(kernelIndex, 32, 32, 1);结合Shader中的[numthreads(32,32,1)],可以计算出 X维度一共有 3232个线程,Y维也是3232个线程,这样就能保证id.xy的范围可以在[0,1024]之间,能够确保所有像素点都被设置了颜色 - 需要设置
m_rt.enableRandomWrite = true并且一定要执行create方法m_rt.Create();,否则Shader执行结束像素也不会被修改
计算结果保存到Buffer中
相比于把计算结果保存到一张Texture中,可能把计算结果保存到一个Buffer中会更灵活些,因为可以在Buffer中存储你自定义的结构体(struct),操作是这样:
- 在C#中顶一个结构体,其中声明了希望放到Compute Shader中取计算的数据,比如位置信息 float4 pos,matrix4x4 之类的
- 定义一个ComputeBuffer对象,用来把构体数据传递给Shader
- 调用
ComputeShader.SetBuffer方法把ComputeBuffer对象传递给指定的Kernel,并指定thread group num - 在Compute Shader中也定义这样一个结构体,不必名称一样,但是结构体中数据的形式必须和C#中的保持一致,即数据类型应该是Shader中对应的类型,比如 float4,float4x4之类的。这篇文章 里的描述可能更能准确的表达意思:
We also need to define this data type inside our shader, but HLSL doesn’t have a Matrix4x4 or Vector3 type. However, it does have data types which map to the same memory layout.
- Compute Shader中同时定义一个
RWStructuredBuffer<Data>对象,即可读写的buffer,其中<Data>就是上一步中定义的结构体 - 然后根据主函数的参数作为索引,对
RWStructuredBuffer<Data>对象进行操作,在C#中通过ComputeBuffer.GetData(Array);方法获取Shader的计算结果,用于后续使用
说完了大致流程下面开始具体实现一下,这个测试要实现这样一个功能:定义100个物体,在C#端构造好100个matrix4x4矩阵(包含位置和缩放),然后传给Compute Shader,在Compute Shader中完成矩阵和向量的计算,然后在C#端获取计算结果,把位置和缩放设置给100个物体。
效果图: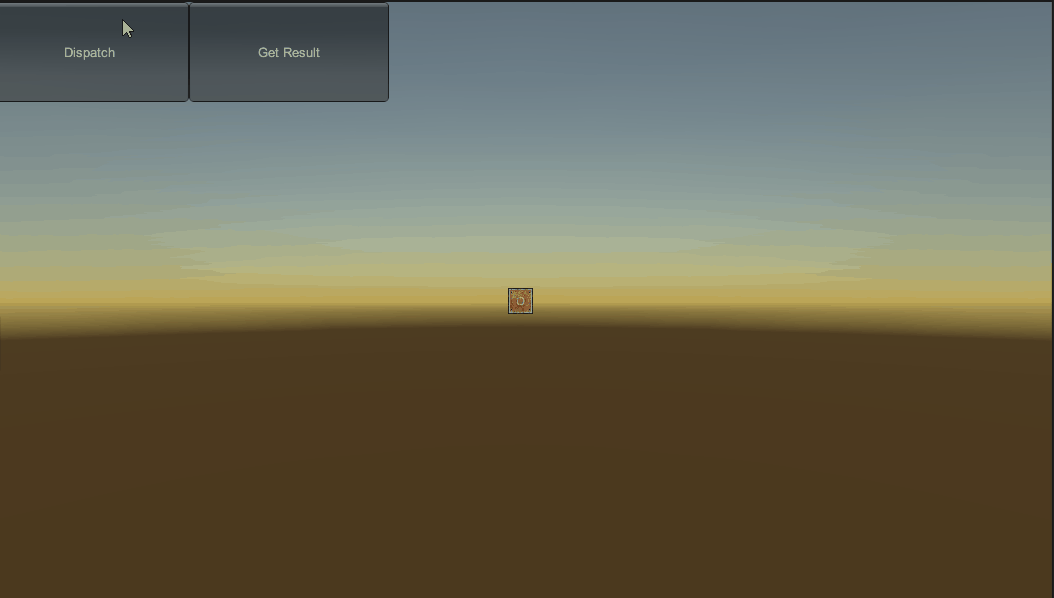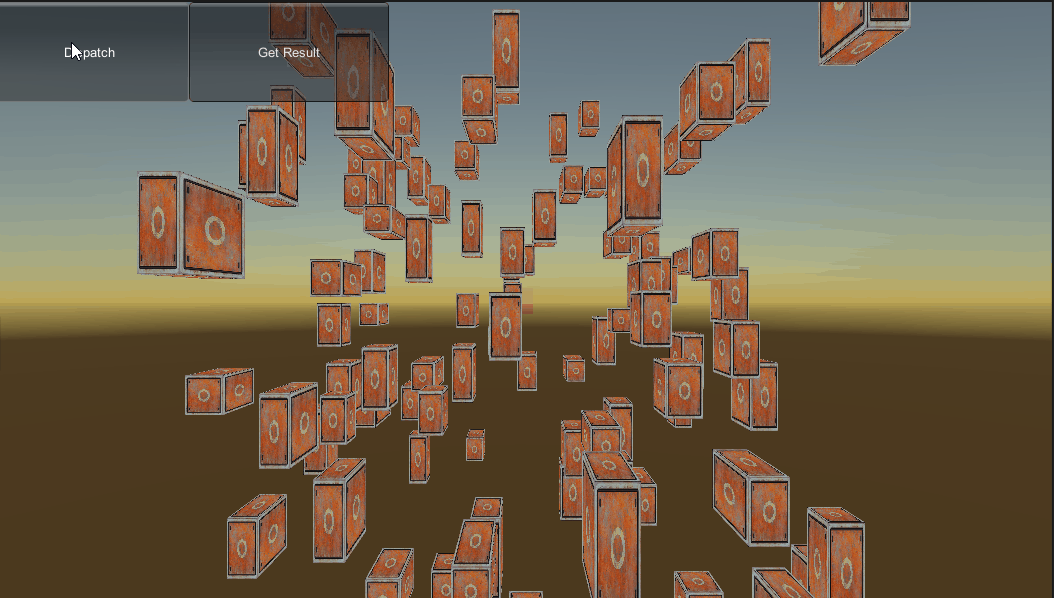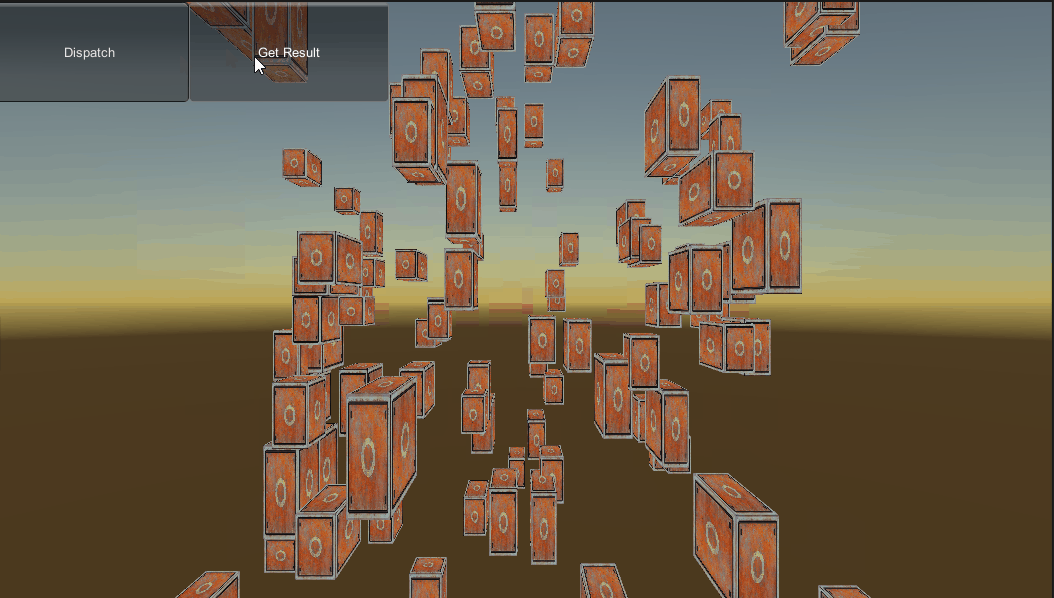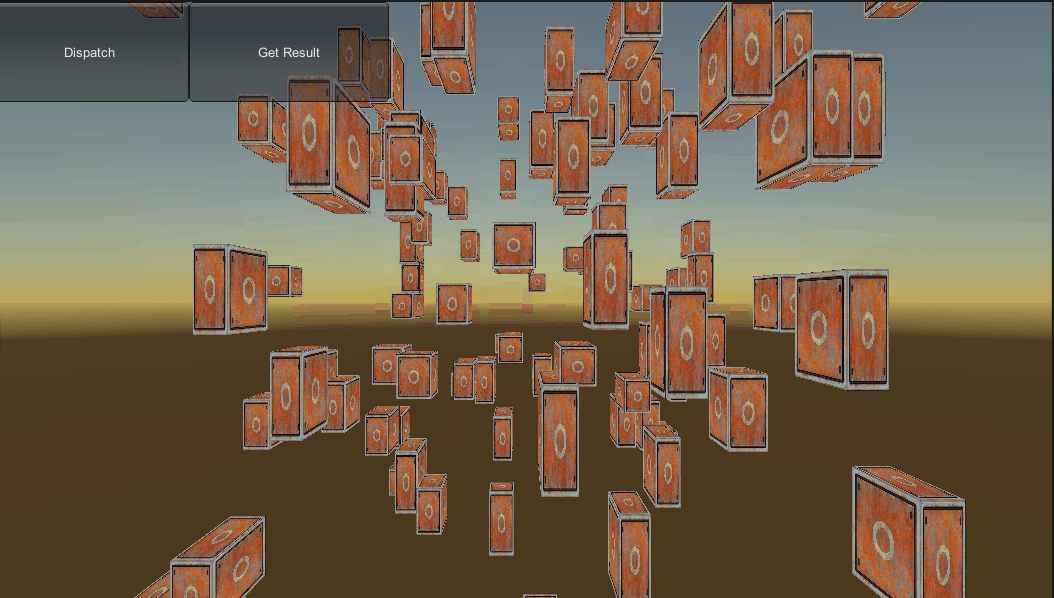
Sounds cool hum? Let’s do this.
C# 主要代码:
// 初始化m_dataArr //
InitDataArr();
m_comBuffer = new ComputeBuffer(m_dataArr.Length, sizeof(float) * Stride);
m_comBuffer.SetData(m_dataArr);
computeShader.SetBuffer(kernelIndex, "ResultBuffer", m_comBuffer);
// 在Shader中只需要用到X维的数据作为数组索引,因此只需要给X维的thread group设置数值,Y维和Z维的thread group数量为1即可 //
computeShader.Dispatch(kernelIndex, 32, 1, 1);
// 初始化传给GPU的数据 //
void InitDataArr()
{
if (m_dataArr == null)
{
m_dataArr = new DataStruct[MaxObjectNum];
}
const int PosRange = 10;
for (int i = 0; i < MaxObjectNum; i++)
{
m_dataArr[i].pos = new Vector4(0, 0, 0, 1);
m_dataArr[i].scale = Vector3.one;
Matrix4x4 matrix = Matrix4x4.identity;
// 位移信息 //
matrix.m03 = (Random.value * 2 - 1) * PosRange;
matrix.m13 = (Random.value * 2 - 1) * PosRange;
matrix.m23 = (Random.value * 2 - 1) * PosRange;
// 缩放信息 //
matrix.m11 = Random.value * 2 + 1; // 从[0,1]映射到[1,3] //
matrix.m22 = Random.value * 2 + 1;
matrix.m33 = Random.value * 2 + 1;
m_dataArr[i].matrix = matrix;
}
}Shader 代码:
#pragma kernel CSMain_Buffer
// Create a RenderTexture with enableRandomWrite flag and set it
// with cs.SetTexture
RWTexture2D<float4> ResultTex;
struct Data
{
float4 pos;
float3 scale;
float4x4 matrix_M;
};
[numthreads(16,1,1)]
void CSMain_Buffer (uint3 id : SV_DispatchThreadID)
{
ResultBuffer[id.x].pos = mul(ResultBuffer[id.x].matrix_M, ResultBuffer[id.x].pos);
ResultBuffer[id.x].scale = mul((float3x3)ResultBuffer[id.x].matrix_M,
ResultBuffer[id.x].scale);
}C#中线程组数量为 32,computeShader.Dispatch(kernelIndex, 32, 1, 1);,Shader中X线程组中线程数量是 16,[numthreads(16,1,1)],32*16 = 512,而我们只有100个物体,所以其实X组里设置4个线程就可以满足需求,4*32=128,大于100,即写成 [numthreads(4,1,1)] 也可以完成任务。
完整代码
最后把两部分结合到一起
C#部分:
using System;
using UnityEngine;
using Random = UnityEngine.Random;
public class ComputeShaderTest : MonoBehaviour
{
public ComputeShader computeShader;
public EMethod method;
public Transform prefab;
// KernelName //
private const string KernelName_Texture = "CSMain_Texture";
private const string KernelName_Buffer = "CSMain_Buffer";
// 方式1要用到的变量 //
private RenderTexture m_rt;
private const int Width = 1024;
private const int Height = 1024;
private Material m_material;
private Transform m_object;
// 方式2要用到的变量 //
private const int MaxObjectNum = 100;
private ComputeBuffer m_comBuffer;
private DataStruct[] m_dataArr;
private Transform[] m_objArr;
private Material[] m_materialArr;
public enum EMethod : int
{
RenderTexture = 0, // 方式1: 使用 RenderTexture 来存储结算结果 //
ComputerBuffer = 1, // 方式2: 使用 ComputeBuffer 来存储结算结果 //
}
struct DataStruct
{
public Vector4 pos;
public Vector3 scale;
public Matrix4x4 matrix;
}
private const int Stride = sizeof(float) * (4 + 3 + 16);
void Start()
{
switch (method)
{
case EMethod.RenderTexture:
m_object = Instantiate(prefab);
m_object.position = Vector3.zero;
m_object.localScale = Vector3.one*5;
MeshRenderer render = m_object.GetComponent<MeshRenderer>();
if (render != null)
{
m_material = render.material;
}
break;
case EMethod.ComputerBuffer:
GameObject parent = new GameObject("Parent");
parent.transform.position = Vector3.zero;
// 初始化物体数组 //
m_objArr = new Transform[MaxObjectNum];
for (int i = 0; i < MaxObjectNum; i++)
{
Transform obj = Instantiate(prefab);
obj.transform.SetParent(parent.transform);
obj.transform.localPosition = Vector3.zero;
obj.transform.localScale = Vector3.one;
m_objArr[i] = obj;
}
break;
}
//uint x = 0;
//uint y = 0;
//uint z = 0;
获取的是shader文件中的数值, 即 [numthreads(X, X, X)] 中的数值 //