Abstract
Open set domain adaptation的主要目标就是通过源域与目标域之间的共享类来减少跨域造成的域间差异。而之前的相关处理思路没有考虑到开放集数据的语义结构,这可能会引入偏差,混淆决策边界附近的分类器。
本文从两个思路来探讨开放数据集的语义结构:
-
语义分类对齐:其目的是通过分类对齐目标域和源域的共享类来获得已知类的良好可分性
-
Introduction
问题引入
测试数据通常来自与训练数据不同的分布,而且目标域存在未知类,未知样本的存在阻碍了跨域比对,而且跨域类间的不匹配也使得未知样本的区分更加困难。未知类的存在也导致为封闭集域适配而开发的方法不能简单地转移到这样的开放集设置。
本文目标
在没有目标域标签的情况下,同时处理域转移和未知对象的识别(这里的识别只是从目标域中的已知类中区分推离,而不是对未知类进行类别的详细识别)。
方法
引入开放集数据的语义结构,使未知类更易分离,从而提高了模型对目标领域数据的预测能力。
具体思路⭐
扩大两种边界:
边界一:已知类之间的边界,目标是使已知的类更加可分
手段
1.源域与目标域之间的已知类:
使用语义类别对齐(semantic categorical alignment (SCA)),通过将目标域已知类与源域的已知类进行匹配对齐,间接提高二者的可分性。
2.源域之间的已知类:
已知类之间的差别可以使用交叉熵所示来实现,但是作者使用了对比中心损失(contrastive-center loss)来进一步增强类别之间的可分离性。
边界二:未知样本和已知类之间的边界,期望将未知的类推离决策边界
手段
使用了语义对比映射( semantic contrastive mapping (SCM) )将未知类推离边界:设计对比损失,使未知类和已知类之间的差值大于已知类之间的差值
⭐由于目标标签不可用,作者使用每次迭代的网络预测作为目标标签的假设来执行语义分类对齐和语义对比映射。
图释
在训练过程中,来自不同领域但在同一类别中的样本(例如蓝色圆圈和红色圆圈)彼此“吸引”。对于每个域,不同已知类别(例如蓝圈和蓝星)之间的边界被扩大。此外,未知类别中的样本(例如不规则多边形)被从已知类别的样本中“分散”。
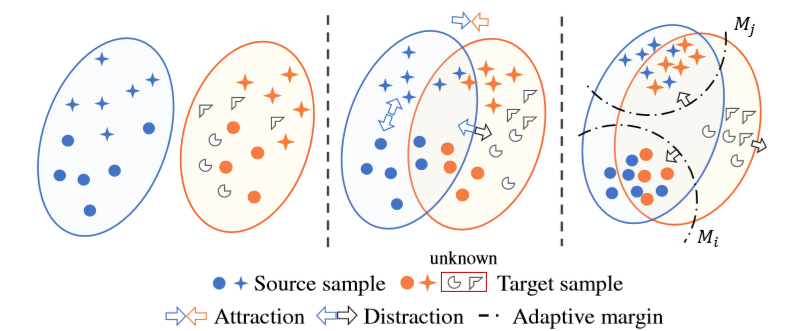
左图:表示为自适应前的数据,存在域偏移以及未知样本
中间:表示来自同一个类的数据拉近,而未知的样本被推开
右图:来自目标域中的已知类别可以更好的与源域中的相应的数据对齐,而目标域中的未知类的样本则与已知类区分开来
Related work
(基于距离的学习)Distribution-based learning
许多手段是通过计算源域与目标域之间的域间差异来衡量域不变的特征,比如KL散度、最大平均差异(MMD)、瓦瑟斯坦距离……就比如说MMD,本质上是要找到一个变换函数,使得变换后的源域数据和目标域数据的距离是最小的。但是目标域可以与源域不同,但是要相关,而当目标域存在过多的未知类的话,会严重影响这些手段的准确性。
任务导向学习
以对抗的方式调整领域差异,通过使用反向损耗(在反向传播期间反转梯度)来学习域不变特征。
开放域识别 Open Set Domain Adaptation (OSDA)
Busto等人提出了通过学习目标样本分配问题的跨域映射来解决这个问题。如上所述,不可能用选定的类别覆盖所有未知样本。
Saito等人提出源域不存在未知类的设定,并将未知视为不同的类别,它们使网络能够在已知类别之间对齐特征,同时拒绝未知样本。
作者的方法就是将未知样本视为“未知”类。不同的是,作者致力于通过增强表示的区分性来解决开集域自适应问题,将目标域中的相似样本与源域对齐,同时将未知样本从所有已知类中推开。
Method
Overall Architecture
为了解决以下问题,作者提出三种相应的处理模型。
问题
问题一:将目标域中的已知类样本与源域的已知类样本对齐
问题二:将目标域中的已知类与未知类分开
处理模型
1.对抗域适应( Adversarial Domain Adaptation (ADA))
将目标域的样本与源域的一直样本进行对齐,或者将其归类为未知样本
2.语义类别对齐(Semantic Categorical Alignment (SCA))
(1)基于对比中心损失,拉近来自同一类别的样本的表示
(2)基于跨域的中心损失,将目标域已知类与源域的已知类进行匹配对齐
3.语义对比映射(Semantic Contrastive Mapping (SCM))
基于中心损失,使得目标域中的已知类向源域的相应中心移动,而将目标域中的未知类从已知类中分离出来
整体框架
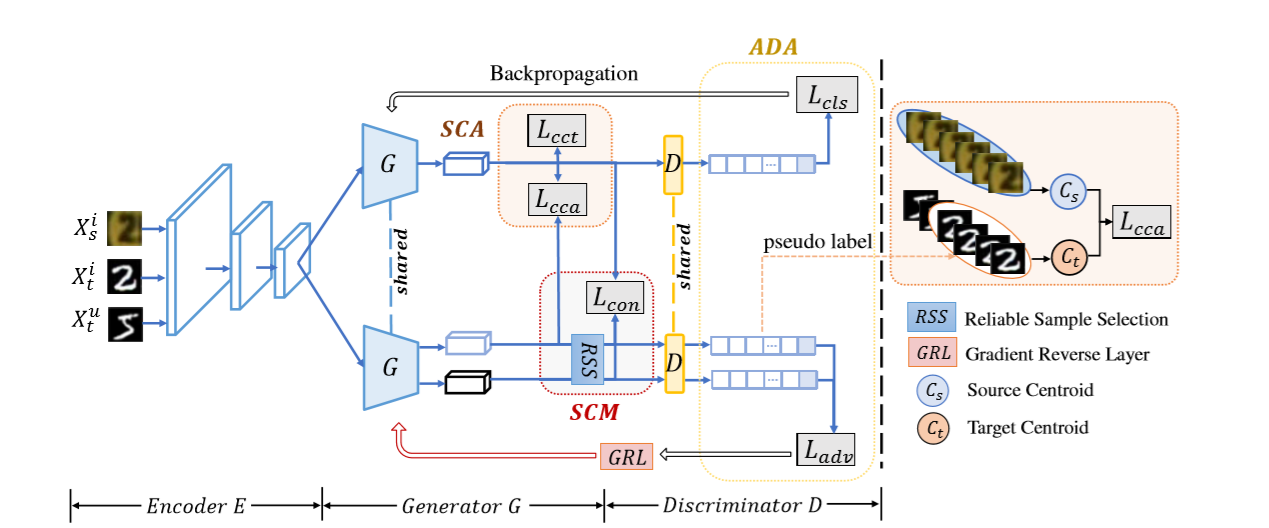
它由一个编码器E、一个生成器G和一个鉴别器D组成。
图像编码器E是一个预处理的CNN网络,用于提取可能涉及到域变化的语义特征。
生成器G由一组全连接层组成。其目的是将图像表示转换成面向任务的特征空间
鉴别器D将每个具有通用表示的样本分类到一个类别中
Adversarial Domain Adaptation
开放集域自适应的目标是将输入信息分类为N + 1类,其中N表示已知类的数量。来自未知类别的所有样本被分配给未知类别N + 1。(将目标域中所有的未知样本扔到一起看作一个类:未知类)
⭐特征生成器与鉴别器相辅相成,特征生成器来最小化源域与目标域之间的差异,当鉴别器无法分辨样本来自哪个域的时候,生成器就掌握了域不变的表示。
在源域中区分相应类别:使用交叉熵损失函数+softmax
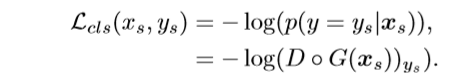
区分目标域中的已知类与未知类:使用了二值交叉熵损失函数
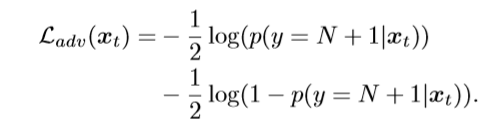
在梯度反向层更新生成器G以及鉴别器D的参数
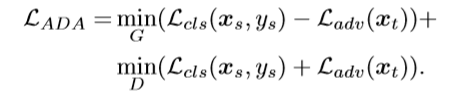
ADA模块将目标域与源域放入样本对齐,并形成目标域中已知样本与未知样本的边界
Semantic Categorical Alignment
SCA使每个已知类更加集中,源和目标之间的对齐更加准确:拉近已知类内部的表示,而加大各个已知类之间的区分
步骤
⭐1.采用对比中心损失(contrastive center loss)来增强源域样本的生成特征的区分性。
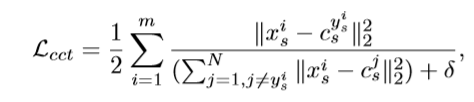
(m是训练集中一个小batch的样本个数;表示来自源域的第i个样本;si表示源域该类别的中心; δ防止分母为0)
⭐2.来自目标的已知类的每个中心将与源域中相应的类的中心对齐。
由于每个小batch有随机性、偏移性,所以使用全局中心来代替局部中心,而全局中心又是从每次局部中心的迭代中更新生成的。
全局中心的初始化:
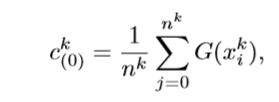
作者在源域数据上使用预训练的模型进行训练,对于目标样本,使用预测结果作为伪标签。在每次迭代计算一次局部中心(所有样本的平均值),并对源域以及目标域的中心进行加权更新:
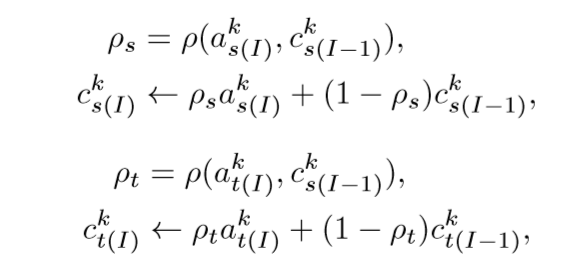
其中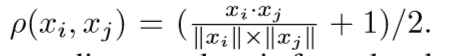
最终的分类中心对齐损失(categorical center alignment loss)为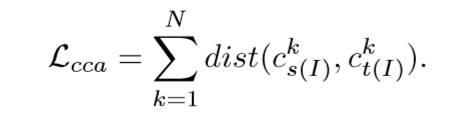
而其中的表示源域的分类k的中心,而表示目标域中的分类k的中心
SCA优点
1.对比中心损失(contrastive center loss)增强了表示的紧凑性,也扩大了类间的边界。
2.分类中心对齐损失(categorical center alignment loss)保证同一类的质心在源域和目标域之间对齐。
3.动态更新一起保证SCA将全局和最新的分类分布对齐
4.重新加权技术削弱了不正确的伪标签,因此可以减轻伪标签的累积误差
Semantic Contrastive Mapping
对于目标域中的非中心样本,作者使用对比损失函数来鼓励已知样本向其中心靠近,并强制未知样本远离所有已知类的中心
从而缩小已知样本与其中心之间的距离,同时扩大未知样本与所有中心之间的距离。
由于目标样本的伪标签不完全正确,作者选择分类概率超过阈值(1/n+1)的可靠样本。
对比损失(contrastive loss)
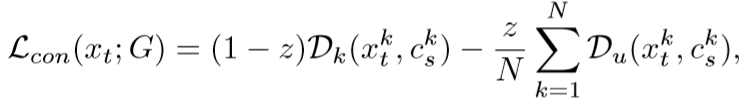
(z当是已知类的时候值为0,而当为未知类的时候值为1,表示目标域已知类与对应源域类别的距离,表示目标域未知类与对应源域所有类别的距离)
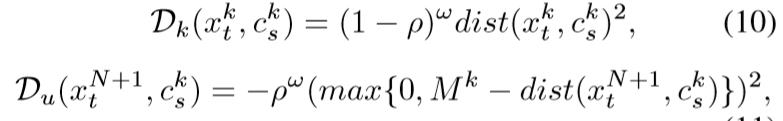
(其中ρ表示余弦相似度,超参数ω对损耗中计算的距离进行重新加权)
是测量k类邻域半径的分类自适应余量:
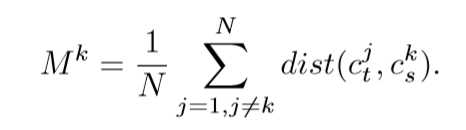
Objective
总loss:
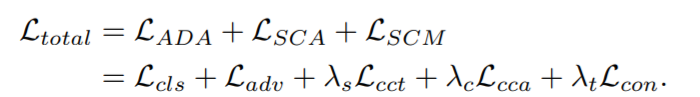
总算法:
1.预训练对抗网络中的生成器与鉴别器
2.在类别未聚集时计算全局中心;再迭代batch更新(源域的分类k的中心)与(目标域中的分类k的中心);计算二者距离;选择何适合的目标域样本计算与的距离;最后计算总loss,更新,
Experiments
Setup
baseline模型
OSVM:将预测概率低于阈值的测试样本分类为未知类,OSVM要求源域中不存在未知类。
MMD+OSVM:MMD与OSVM结合,其中MMD用来衡量域间距离。
BP+OSVM:在OSVM的基础上添加一个域分类层,这是对抗式学习在无监督领域适应中的一个典型应用
数据集
digits
SVHN:32*32大小,一张图可能出现多个数字
MNIST :28*28大小,灰度图像
USPS:16*16灰度图像
场景假设:SVHN 到 MNIST, USPS 到 MNIST, MNIST 到 USPS.
Office-31
Amazon来自商场的2817张办公室用品图片;webcam795张低分辨率的图片与DSLR498张高分辨率的图片。
各个域间共享31个分类,按字典顺序的前10个类被分为已知类,而剩下的就是未知类。
场景假设: A → D, A → W, D → A, D → W, W → A, W → D
Implementation
digits
0~4设为已知类,而剩下的设为未知类。
训练CNN时使用Adam提取源域的类别特征
Office-31
分别使用AlexNet、VGGNet提取特征,使用在ImageNet上预训练的模型初始化特征提取器
Results on Digit Dataset
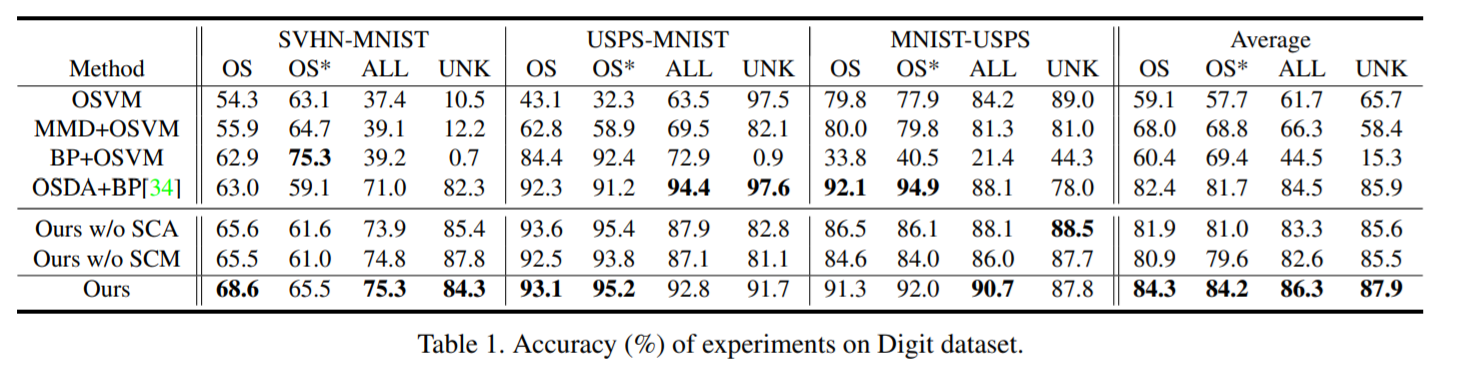
作者的方法在SVHN → MNIST, MNIST → USPS 中优势突出,而SVHN → MNIST的语义鸿沟较大,因为SVHN可能一张图中有多个数字。
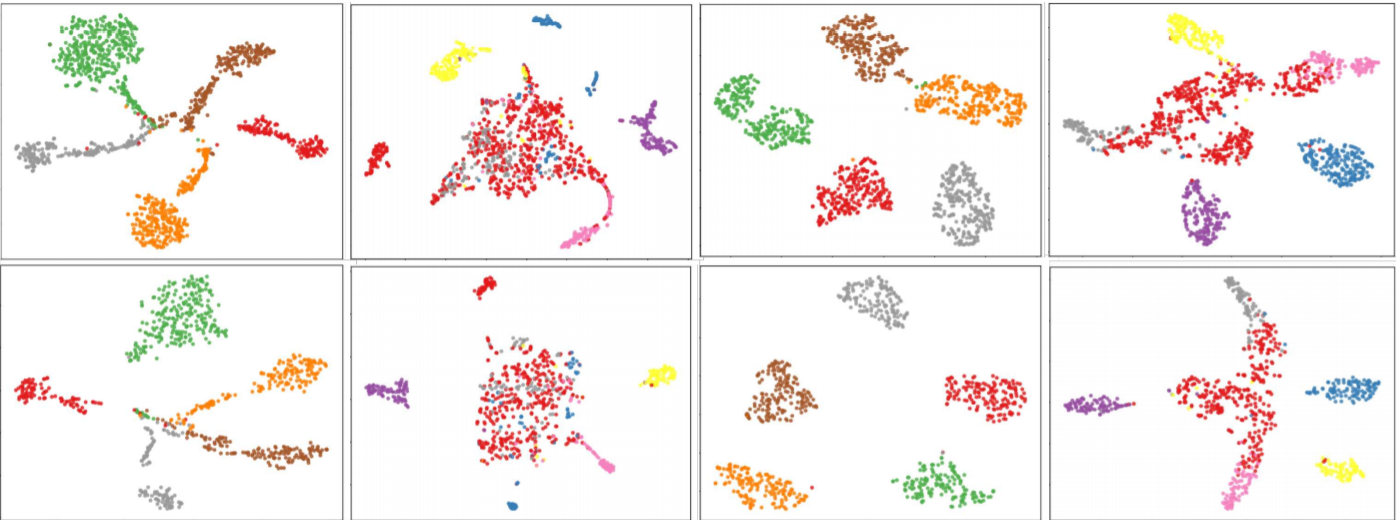
第一行表示OSDA+BP的效果,第二行时作者方法的效果
左边的两幅图是 SVHN → MNIST中源域与目标域的特征分布,而右边的两幅图是 MNIST → USPS中源域与目标域的特征分布,其中目标域中红色的是未知类。可以看到SVHN → MNIST两个域的语义差异较大。
Results on Office-31 Dataset
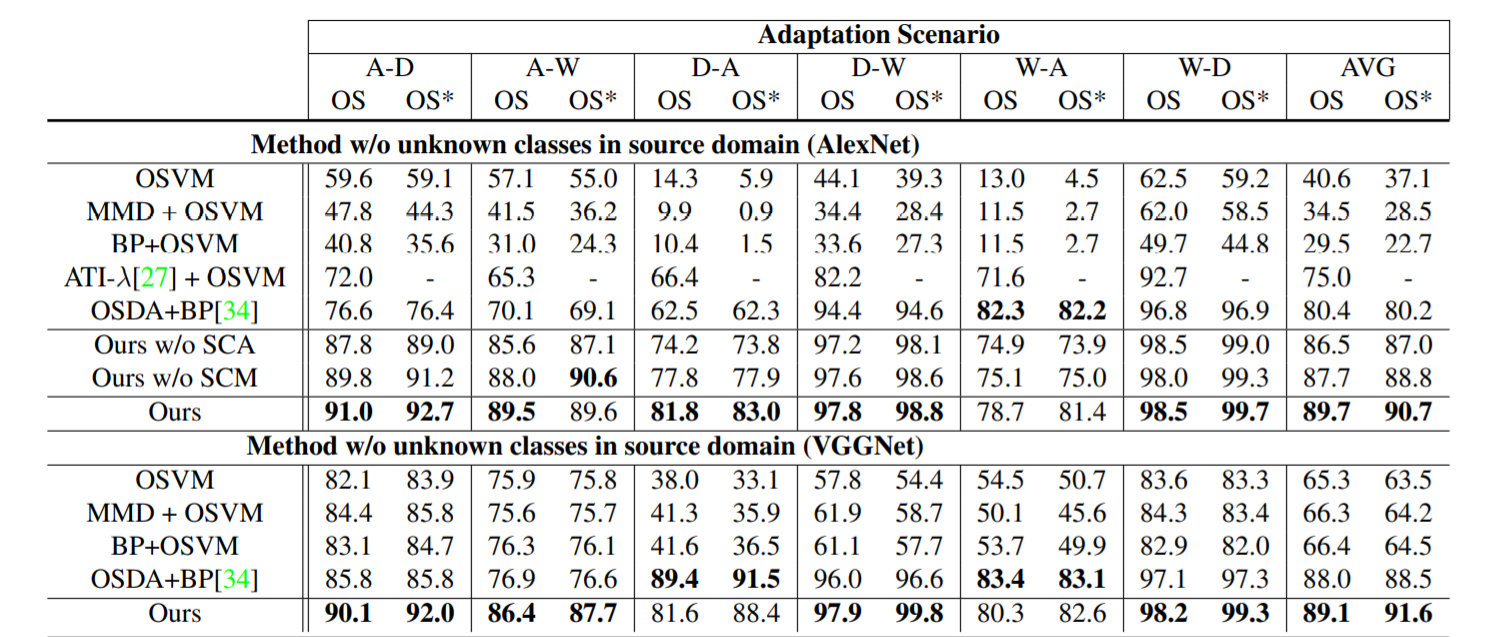
Ablation Study
逐个在模型中去除SCA、SCM,结果在digits、office31数据集中都可以看到识别的精度都有所下降,侧面证明了SCA、SCM对模型的重要性。
适应性边界的作用
边界在对比损失下是一种适应性的,而作者使用一种静态边界(用一个常数值表示)作为对比。
当为0的时候,对比项的目标只是将所有预测的目标域已知样本与源域中相应的中心对齐;
而当很大的时候,该模型倾向于惩罚所有loss较大的被预测为属于未知类的目标域样本。
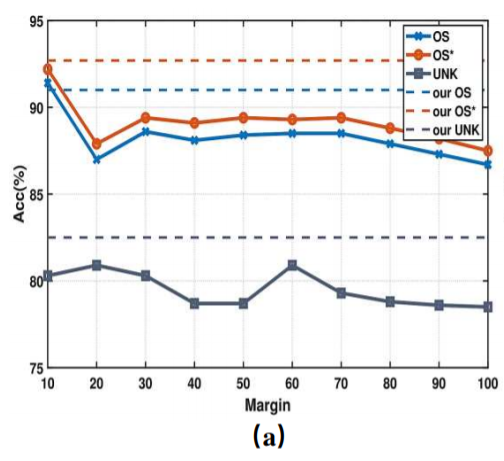
可以看到,当使用静态边界的时候,OS、OS*以及UNK都有下降的趋势,而适应性边界则没有这样的问题。
为进一步查看类别之间的距离在训练中的变化情况,作者对“Backpack”类进行查看:
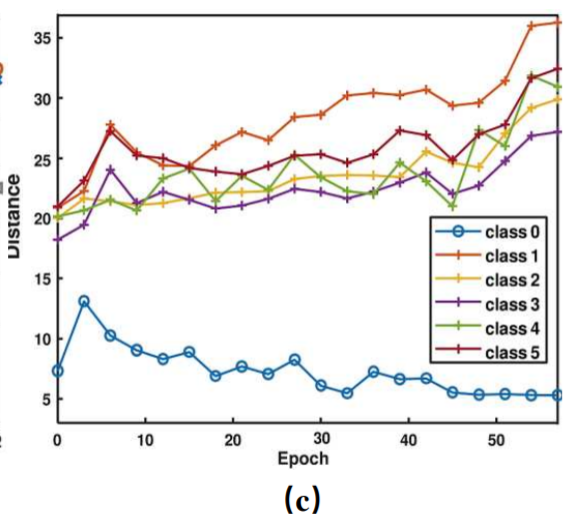
class0表示目标域中的Backpack类与源域中的该类的中心之间的距离在减小(图中的蓝线在迭代的过程中呈现下降趋势)
而class1~5则表示目标域中的Backpack类与源域中的其他类之间的中心的距离在增大(图中的其他线在迭代的过程中呈现上升的趋势)
随着跨域对齐和不同类之间的分离,每个类的邻域半径将会改变。这也解释了为什么自适应边界比静态边界产生更高的分数
对比损失重新加权的效果
通过更换不同的超参数ω来查看对Lcon的影响,通过比对证明重新加权项可以帮助模型更好地度量未知样本和源域中心之间的距离。
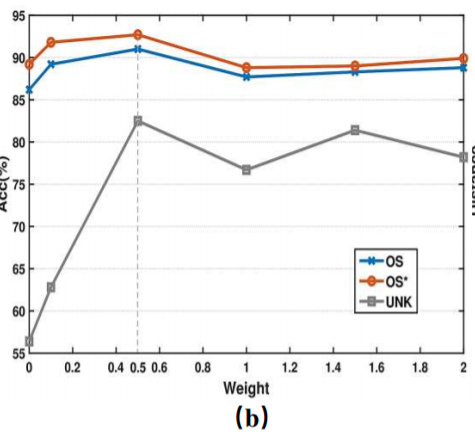
当ω为0.5的时候精度最高
未知样本比例的影响
考查在目标域中未知类不同比例的情况下,模型的鲁棒性。
在未知类占比∈ (0, 1),与BP+OSVM 和OSDA+BP对比:
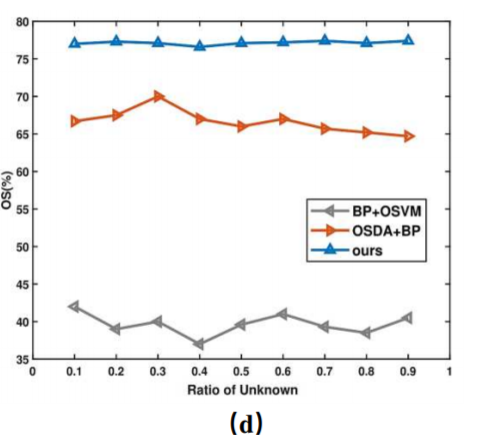
作者的模型的鲁棒性较高,在比例不断变化的过程中,效果浮动不大。
Conclusion