Separate to Adapt: Open Set Domain Adaptation via Progressive Separation论文笔记
Abstract
Domain adaptation问题在利用源域的标注数据为未标记的目标域学习准确的分类器方面已经有较大成功,但是Open Set Domain Adaptation问题中的目标域中存在未知类,而未知类所占的比例对解决问题的方案的性能影响很大。在源域与目标域对齐的时候,如果不将目标域中的未知类排除,会造成已知类与未知类的不匹配而形成负迁移。
本文提出分离适配(Separate to Adapt (STA)),一种端到端的开集域适配方法。这种方法采用由粗到细的加权机制,逐步分离未知类和已知类的样本,同时加权它们对特征分布对齐的影响。
经过验证,该方法适用于目标域的各种开放类型且效果很好。
Introduction
背景
目前计算机视觉方面的提升大多数是得益于大量带注释的训练数据,而在实际的运用中这样的数据并不多。而不同领域的数据又来自不同的分布。领域差距可能导致模型在目标领域做出错误预测。而现有的领域适应方法无论是通过特征级还是像素级的分布匹配来弥补领域差距,其方法大都假设源域和目标域共享相同的标签,即封闭集域适应。
本文研究的背景是在开集域适应(OSDA)中,目标域拥有源域中所有的类,而且目标域中存在未知类。
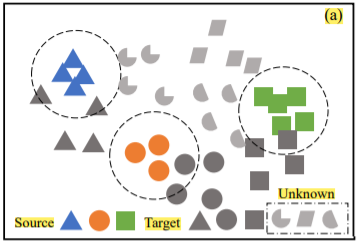
开集域适配的两个挑战
(1)减轻域间差异的影响
(2)未知类的存在可能会造成负迁移
已知处理OSDA问题的少数方法的缺陷:
迭代分配变换(Assign-and-Transform-Iteratively (ATI) ):使用一个基于距离的度量来迭代地标记未知样本
开集反向传播(Open Set Back-Propagation (OSBP) ):尝试解决源域中没有未知类的问题
两种方法都需要一些阈值超参数来区分已知类和未知类,而设置超参数还需要目标域类别的先验知识,而在现实中的开放性可能是变化比较大的,所以超参数难以选择,而且依赖于预定义超参数的方法需要大量的超参数选择工作
⭐作者的方法
文章提出分离适应( Separate to Adapt (STA)),在不同的开放程度下解决开集域适应问题。
作者使用域间对抗学习的框架,并且为源域中的分类器添加了一个类:unknown class。
目标域中的已知类与未知类的主要区别在于:目标域的已知类与源域的已知类区别仅在于分布偏移,而目标域的未知类与源域的未知类区别更大,既有域间隙,也有语义间隙。
由此,作者开发了一个由粗到细的分离管道组成的渐进分离机制。
第一步是用源数据训练多二元分类器,以估计目标域中的数据和每个源类之间的相似性。
第二步中,我们选择相似度极高和极低的数据作为已知和未知类别的数据,并用它们训练细粒度二元分类器,对所有目标域样本进行精细分离
在这两个步骤之间迭代,并使用实例权重来拒绝对抗域适应中未知类的样本
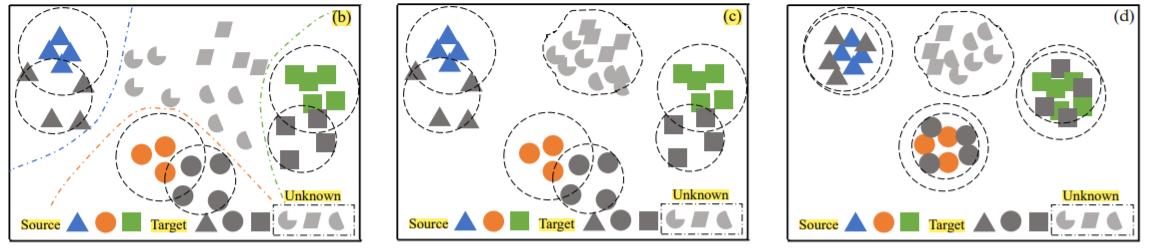
图中左边表示在进行了源数据训练多二元分类器之后,通过产生的初步权值来从目标域中区分出未知类。图中的虚线是二元分类器为每个类产生的决策边界。
图中中间是训练细粒度二元分类器来得到更精确的权重,目标域中的已知类以及未知类都已经分离开来。
图中的右边表示经过最后的分布对齐,目标域中的共享类已经域源域的相应类别对齐。
Related Work
封闭域自适应(Closed Set Domain Adaptation)
封闭集域自适应方法寻求减轻由域差异带来的性能下降。典型的方法是最小化特征分布之间的距离
- 深度自适应网络(Deep Adaptation Network (DAN) ):增加了自适应层,最小化分布的内核嵌入之间的最大平均差异(MMD)
- 中心矩差异(Central Moment Discrepancy (CMD) ):通过仅匹配一阶和二阶矩同样实现了域自适应。
- 剩余转移网络(Residual Transfer Network (RTN)):通过增加一个快捷连接和熵最小化标准来改进DAN
- 联合适应网络(Joint Adaptation Network (JAN)):匹配源域和目标域的特征和标签的联合分布。
- 领域对抗神经网络(Domain Adversarial Neural Network (DANN))、对抗性区分域适应(Adversarial Discriminative Domain Adaptation (ADDA)):使用领域鉴别器来区分两个领域,同时学习特征提取器来混淆领域对抗训练范例中的领域鉴别器
- 条件域对抗网络(Conditional Domain Adversarial Network (CDAN)):通过匹配标签和特征的联合分布来改进DANN
开集识别(Open Set Recognition)
即如何能正确的区分已知类别并拒绝其它未知类别。
- 1-vs-set模型:从边际距离描绘决策空间,开放集SVM分配概率分数以拒绝未知样本,进一步改进了紧凑的减少概率模型。
- 引入OpenMax层:利用深层神经网络进行开集识别
在开放集识别场景中,存在不属于训练数据集中的类的离群值。然而,在开放集域自适应中,两个域的共享类中的目标样本和源样本进一步遵循不同的分布,使得任务更具挑战性。
开集域自适应(Open Set Domain Adaptation)
分配和变换迭代(Assign-and-Transform-Iteratively (ATI))利用每个目标域样本的特征和每个源类别的中心之间的距离来决定目标样本属于源类别之一还是未知类别。
开集反向传播(Open Set Back-Propagation (OSBP) ):训练特征生成器来衡量目标域的样本偏离预训练的阈值而被分为未知类的概率。在对抗训练框架中训练其特征提取器和分类器。
两种方法在开集的开放度变化很大的情况下会出现问题。
作者开发的分离适配网络(Separate to Adapt (STA) )不需要在已知类和未知类之间手动选择阈值参数。
Method
Open Set Domain Adaptation
基本的符号说明
(D_s = {(X_i^s,Y_i^s)}^{n_s}_{i=1})表示源域的(n_s)个有标注的数据;(D_t = {{X_j^t}}^{n_t}_{j=1}) 表示(n_t)个无标签的数据。
(C_s)表示源域中的类别;(C_t)表示目标域中的类别,而且(C_s⊂C_t);而(C_{t/s})统一表示目标域中的未知类
源域所在的分布:p ; 目标域所在的分布:q
在标准的域适应中,q!=p ;在开集自适应中,p!=q(C_s) ,(C_s) 表示目标域中的已知类所在的分布
定义的开放度:O=1 - |(C_s)|/|(C_t)|
Separate to Adapt
开放域自适应存在浅显的两个挑战:负迁移以及已知类与未知类的分离,而这两个挑战之间也是有联系的。
首先一味地将整个目标域与源域进行匹配,而不将目标域的未知类分离,将导致预测结果在目标域效果不佳(出现负迁移),而要想解决负迁移的问题就要解决已知类与未知类的分离。
所以正确的逻辑应该是分离目标域中的已知类和未知类,只对已知类样本进行特征自适应。
STA结构
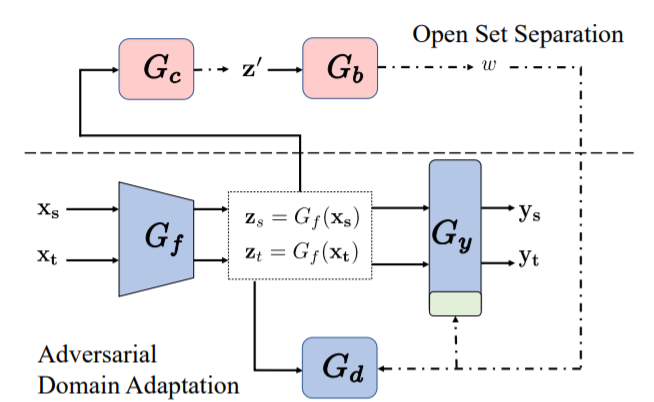
作者的网络架构由图中的虚线分为两部分:
上面的(G_c)表示多二元分类器,(G_b)表示二元分类器:生成拒绝目标域未知类的权值w。
下面的(G_f)表示特征提取器,而(G_y)表示分类器,(G_d)表示对抗域自适应。
(Z_s) (Z_t)表示提取器提取到的特征;(hat{y}_s) (hat{y}_t)表示预测的标签
Progressive Separation(渐进式分离)⭐
为了将目标域中的未知类数据从已知类中分离出来,作者设计了一个由粗到细的过滤措施。作者使用多二元分类器来衡量目标域的样本域源域中的类相似性。每一个二元的分类器都是只由源域的数据训练的。
所有分类器的loss表示为:
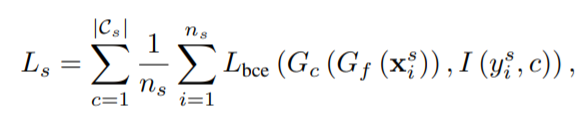
(L_{bce})表示二值交叉熵的loss,如果(y^s_i)=c,则I((y^s_i),c)=1,(y^s_i)!=c,则I((y^s_i),c)=0
filtering strategy one
分类器(G_c)输出的为目标域样本被分类为源域中该类的概率,即可表示目标域数据与源域该类的相似性。可以预知:目标域中的未知类的概率一定比目标域的已知类概率要低,而作者使用这些概率的最大值来表示该样本对应的源域中的类别,相应的未知类的相似性就没有已知类的高。
于是作者将目标域中的所有样本的相似性进行排序,分别使用排序最高的与最低的输入(G_b)二元分类器进行训练。
优点:
- 由于只使用了相似性在极限值的数据,所以过滤相对粗糙但是拥有较高的可信度
- 无需手动调整超参数,鲁棒性强
filtering strategy two
将目标域中的所有样本的相似性分为highest((S_h)), midium lowest((S_l))三类,当(S_j>S_h)则标为已知类;当(S_j<S_l)则标为未知类。之后将判断后的已知类与未知类输入(G_b)二元分类器进行训练。
(G_b)二元分类器的loss表示为:
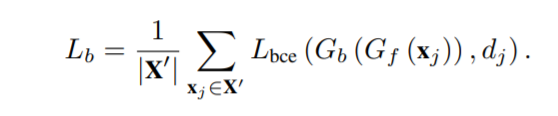
((X^‘)表示多二元分类器过滤样本集;(d_j)表示样本是已知类(0)还是未知类(1))
这样一来,通过(G_c)多二元分类器以及(G_b)二元分类器,作者实现了由粗到细的过滤,将目标域中的已知类与未知类成功分开。
Weighted Adaptation(加权适应)
在模型的对抗域适应部分,左侧定义的源域的损失为:
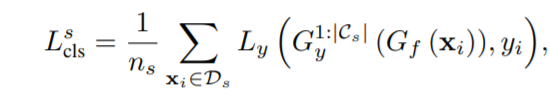
(L_y)是交叉熵的loss,而(G_y)表示添加到源域中的那一个表示为unknown class的特定分类器
(G_y^{1:|C_s|})表示将每个样本分配给已知类的概率。
在上面(G_b)的过滤后,作者并没有将(G_b)分类的输出作为最后结果,而是作为一个权值wj,使用wj来定义共享标签空间Cs中特征分布的对抗性适应的加权损失
于是运用该权值为(G_d)定义loss:
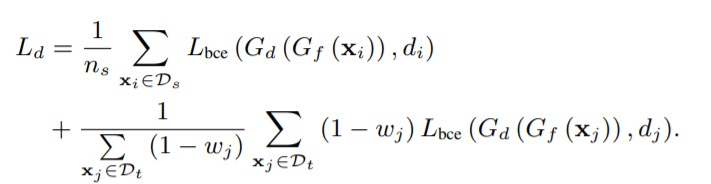
另外还需要在目标域中选取未知类的样本,以训练(G_f)获得额外的unknown类。基于度量已知类和未知类分离度的权重wj,判别unknown类的加权损失定义为:
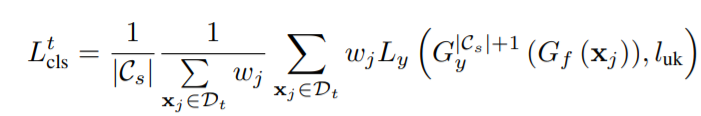
其中(l_{uk})表示为unknown类,而(G_y^{|C_s|+1})表示目标域的样本为分类为未知类的概率。
进一步在已知的目标域类上加入熵最小化损失(L_e),以保证决策边界包裹目标域中的低密度区域
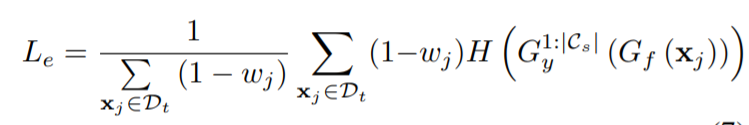
作者只将目标样本预测为已知类的进行熵最小化,所以使用了wj作为权重。
Training Procedure
known/unknown separation step
- 首先开始训练特征提取器(G_f)以及对源域进行分类的分类器(G_y),而多二元分类器是目标域样本与源域所有类别进行一对多的训练。
- 之后进一步选择目标域中相似性高的、低的输入细粒度(G_b)二元分类器进行训练。
(G_f)输出的参数:(θ_f) (G_y)输出的参数:(θ_y) (G_b)输出的参数:(θ_b) (G_c^{|C_s|})输出的参数:(θ_c|^{|C_s|}_{c=1})
最优的参数(hat{θ}_f) (hat{θ}_y) (hat{θ}_b) (hat{θ}_c|^{|C_s|_{c=1}})的选择是:
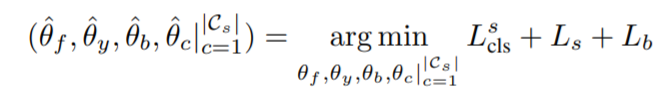
weighted adversarial adaptation step
实现对抗性自适应,使目标域中已知类的特征分布与源域保持一致,并利用未知类中的数据为额外类训练Gy
(θ_d)表示(G_d)的参数:
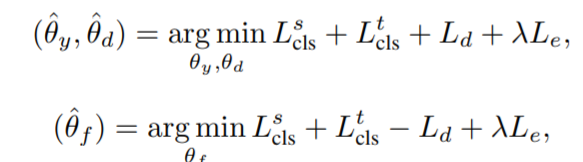
(λ是一个用于权衡熵损失的超参数)
利用分离适配(STA)模型,可以有效分离目标域中已知类和未知类的数据。
步骤1拒绝异常值以避免在步骤2中分散未知类的注意力,而步骤2执行对抗性调整以使步骤1中的拒绝管道更准确。
由于在整个过程中不需要手动选择阈值超参数,所以在实际场景中,当开放度O变化时,我们可以避免痛苦的调整。
Experiments
Setup
数据集
Office-31:Amazon来自商场的2817张办公室用品图片;webcam795张低分辨率的图片与DSLR498张高分辨率的图片。(各个域间共享31个分类)
Office-Home:通过网络爬取,其中包括4个域,Artistic (Ar), Clipart (Cl), Product (Pr) and Real-World (Rw)。每个域包含来自65个类别的图像,前25个类设置为源域域目标域的共享类,而剩下的属于未知类。4个域两两互换顺序作为源域域目标域,共12个任务,由于未知类的个数比已知类多,所以该数据集的域间差异较大,难度也较大。
VisDA-2017:拥有两个域,其中一个拥有152397张合成的2D图像,另外一个包括55388张真实的图片,两个域拥有12个共享类。
Digits:拥有三个标准的数据集:MNIST , USPS and SVHN.作者构建了三个任务:SVHN → MNIST, MNIST → USPS 和USPS → MNIST.
Caltech-ImageNet:由ImageNet-1K与Caltech-256 datasets构建。已知类设置为84个类,而未知类从0~916变化区测试不同开放度中模型的鲁棒性。
baseline
Open Set SVM (OSVM) :OSVM是一种基于支持向量机的方法,对每个类使用阈值来识别样本和剔除异常值
MMD+OSVM 、DANN+OSVM:是OSVM的两个变体,包含最大平均差异OSVM中的域对抗网络
OpenMax :是一种深开放集识别方法,其模块设计用于异常值剔除
ATI-λ:通过将目标域中的图像分配给已知类别,将源域的特征空间映射到目标域(在作者设置中,没有特定于源代码的类。因此通过交叉验证手动选择ATI-λ的超参数λ)
OSBP:是最新的一种开放集域自适应方法,通过对抗性分类器来处理未知类的样本,达到了最先进的性能
对于闭集方法,我们使用置信阈值来判断样本是否来自未知类。在我们的实验中,我们运行每种方法三次,并报告平均精度
说明
OS:所有类的标准化精度,包括unknown 类
OS*:仅在已知类上的标准化精度
all:所有实例的精度(不包括类的平均精度)
UNK:未知样本的精度。
对比实验
- 使用Digits 与VisDA-2017 数据集,在OSBP方法上进行实验作为比较。
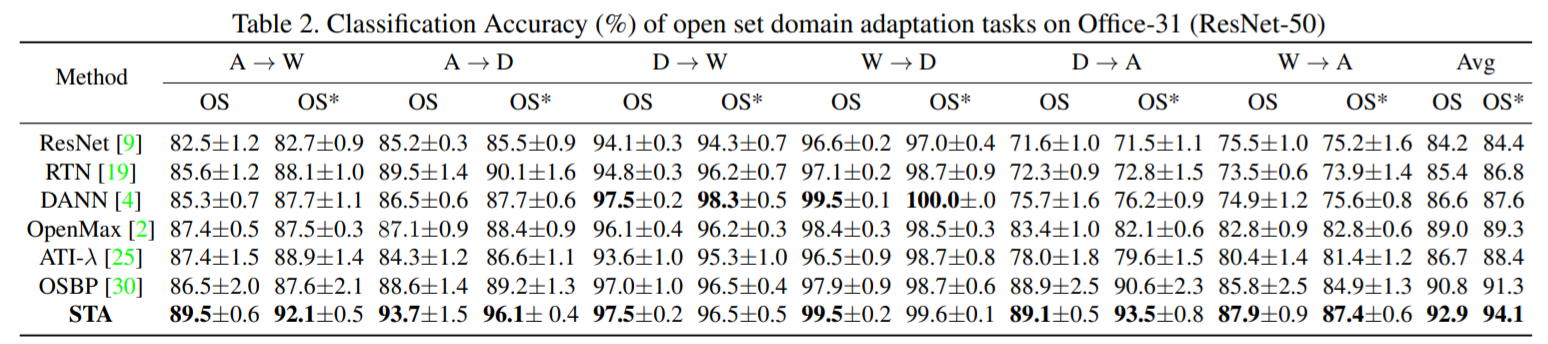
- 在所有的对比方法上用Office-31数据集做对比,使用resnet50网络作为主干网络
- 在Office-Home 与Caltech-ImageNet数据集上使用resnet50网络研究OS的精度。
对于非数字的数据集,作者使用在ImageNet上预训练的模型VGGNet 与 ResNet50进行训练。
对于数字数据集,作者使用了LeNet网络模型。
对抗域的网络域DANN 是一样的,从零开始训练的所有层的学习率是预先训练层的10倍。
Results
STA在digits数据集上的表现优异,而且在SVHN → MNIST情况中域间差异是比较大的,但是STA比OSBP效果好很多。
STA在VisDA-2017数据集中在大部分的类别的识别中得分较高,表示STA在大尺寸的图片以及域间差异较大(合成图片与真实图片)的数据集上表现较好。

在office31数据集上STA基本在每个类上都得到了最高的分数,而我们可以看到一些在封闭集经常使用的方法在这里甚至还不如直接使用resnet网络的效果好,原因就是在目标域的未知类较多的时候,此时的未知类不能忽略,否则就会发生负迁移。
在Office-Home数据集上,STA同样基本在每个类上都得到了最高的分数,而一些在封闭集经常使用的方法在这里依然还不如直接使用resnet网络的效果好,STA算法在分布匹配前分离未知类样本,对较大的域间隔和标签空间差异具有较强的鲁棒性。
Analysis
Ablation Study
1.STA优于STA w/o w(缺少对抗域训练的目标域样本的权重→对已知类和未知类的样本进行加权分离是必要的
2.STA优于STA w/o c(缺少多二元分类器中的softmax分类层)→多二元分类器可以产生更好的相似度,独立地度量目标样本与每个源类之间的关系
3.STA优于STA w/o b(缺少二元分类器(G_b))→二元分类器可以根据多个二元分类器的结果来细化未知类和已知类样本之间的分离
4.STA优于STA w/o j(缺少Training Procedure中的两个steps的迭代)→联合分离和适应的有效性

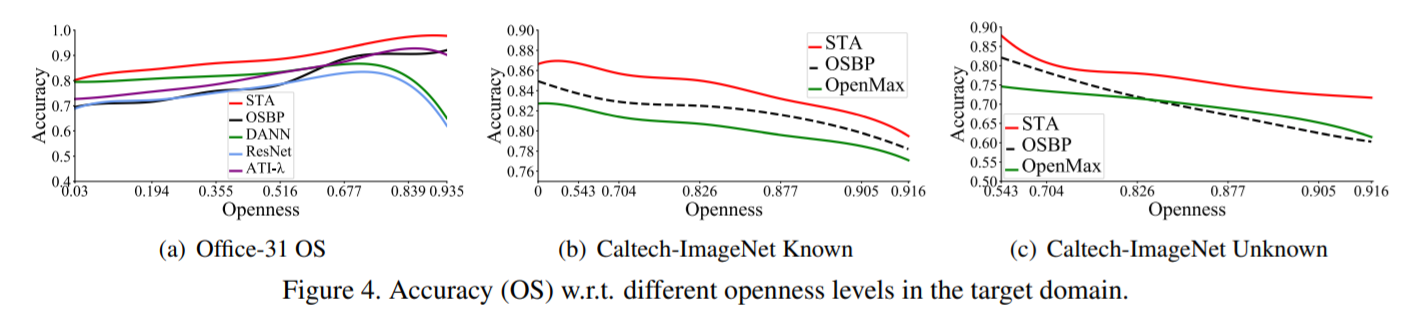
Openness
为了验证STA在不同程度的开放度下的鲁棒性,作者在office31数据集以及Caltech-ImageNet数据集上,让开放度:O=1 - |(C_s)|/|(C_t)|从0~1变化。
结果显示传统的OSDA方法在开放度于0.5左右的表现较好,当开放性接近0或1时,性能会急剧下降,因为这些方法容易混淆已知类和未知类。而 ATI-λ于OSBP虽然表现较好,但在训练之前需要先验知识,这种方法在显示世界中是不太可行的。
而STA在开放度的变化中表现的比较稳定,而且当开放度为0的时候,STA的得分比DANN好,表示该噪声分离机制可以在已知的样本中均匀地输出。
Weight Quality
作者在任务A → W以及VisDA-2017数据集上进行了有关(G_b)二元分类器输出的权重w大小与相应目标域的分类情况的变化:当源域与目标域的数据你叫相似时,w接近于1,相反则是0.

Feature Visualization
作者在Amazon → DSLR任务中展示了 ResNet, DANN, OSBP 与STA的最后一层的特征数据。
其中(a)(b)未知类特征与一些已知类的特征已经混合在一起,表示ResNet 与DANN并不能很好的区分已知类与未知类。
(c)目标域的已知类并没有很好的分开,因为OSBP在不稳定的源域与目标域的关系中表现不是很好。
(d)STA精确地将目标域的样本与源域对齐,并且分离目标域中的未知类。

(绿色的为源域的特征,蓝色的为目标域特征,红色的为未知类特征)
Conclusions
本文提出了一种新的分离适配(STA)模型,解决了开放集域自适应中的关键挑战,即开放性。该模型以递进机制清晰地分离未知类和已知类的样本,并在源域和目标域之间匹配已知类样本的特征。通过在不同的基准数据集上的验证,该模型能够在不同的领域差异和不相交的类下实现开放性健壮的开放集域适应。