https://blog.csdn.net/roger_royer/article/details/78790050
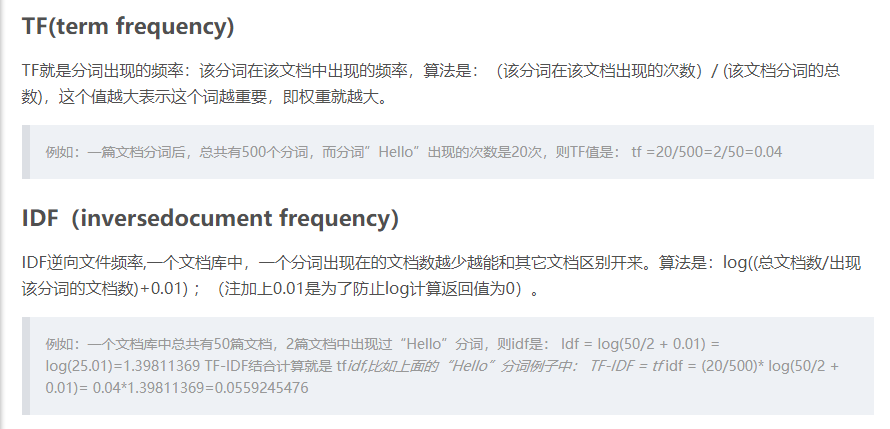
分母+1是为了防止该词语在语料库中不存在,即分母为0,
倒文档频率又称为逆文档频率,它是文档频率的倒数,主要用于降低所有文档中一些常见却对文档影响不大的词语的作用。
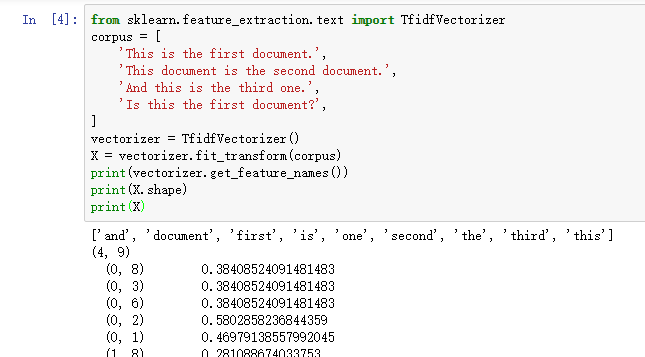
结果分析:
article属性中包含相同的字,即有重复数字。
TfidfVectorizer.fit_transform 输出类型为 ‘scipy.sparse.csr.csr_matrix’
可通过 ‘.A’ 将 ‘scipy.sparse.csr.csr_matrix’ 转化为 ‘ndarray’ 类型
最后地输出即为每个样本的 tf-idf 特征值
tf-idf与gensim生成的词向量有什么关系?
关于tf-idf,这篇介绍的较为详细:http://www.cnblogs.com/biyeymyhjob/archive/2012/07/17/2595249.html
https://www.jianshu.com/p/d4433aa2705d
tf-idf算法是弥补了Word2Vec的算法的缺陷
利用jieba对文本进行分词,利用tf-idf算法来获取关键词,利用gensim来得到文本相似度。
这个模型可以达到对文本进行分类的效果。
前沿内容:对视频,与语音中的内容转换成文字,从而对敏感词进行处理,要是敏感词超过某一限度后,就可限制视频,语音等。
https://www.jianshu.com/p/4bc7fbdafdeb


1.CountVectorizer
CountVectorizer类会将文本中的词语转换为词频矩阵,例如矩阵中包含一个元素a[i][j],它表示j词在i篇文档中出现的频次。它通过fit_transform函数计算各个词语出现的次数,通过get_feature_names()可获取词袋中所有文本的关键字(英语是按字母顺序排列的),通过toarray()可看到词频矩阵的结果。
从结果可以看出,总共出现了三个词:
['aaa', 'bbb', 'ccc']
同时在输出每个句子中包含特征词的个数。例如,第一句“aaa ccc aaa aaa”,它对应的词频为[3, 0, 1],即'aaa'出现了3次,'bbb'出现了0次,'ccc'出现了1次。
2.TfidfTransformer
TfidfTransformer用于统计vectorizer中每个词语的TF-IDF值。
具体计算过程可以参考sklearn的官方文档
http://scikit-learn.org/stable/modules/feature_extraction.html#text-feature-extraction
中的4.2.3.4部分。
sklearn的计算过程有两点要注意:
一是sklean计算对数log时,底数是e,不是10
二是参数smooth_idf默认值为True,若改为False,即
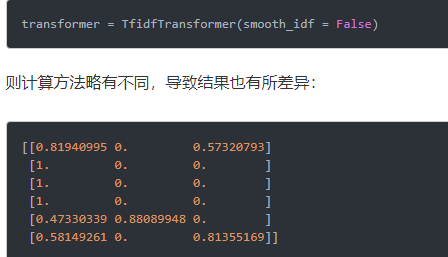
原理+数学推导:
https://blog.csdn.net/Oscar6280868/article/details/80884470
https://blog.csdn.net/silence2015/article/details/61631800


假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现”中国”、”蜜蜂”、”养殖”这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,”蜜蜂”和”养殖”的重要程度要大于”中国”,也就是说,在关键词排序上面,”蜜蜂”和”养殖”应该排在”中国”的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个”重要性”权重。最常见的词(”的”、”是”、”在”)给予最小的权重,较常见的词(”中国”)给予较小的权重,较少见的词(”蜜蜂”、”养殖”)给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了”词频”(TF)和”逆文档频率”(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词(”中国”、”蜜蜂”、”养殖”)的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
---------------------
作者:Little Programmer
来源:CSDN
原文:https://blog.csdn.net/qq_20989105/article/details/82685162
版权声明:本文为博主原创文章,转载请附上博文链接!
《数学之美》---https://www.cnblogs.com/weibaar/p/5297518.html
IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。(另一说:IDF反文档频率(Inverse Document Frequency)是指果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。)但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处.
http://www.cnblogs.com/biyeymyhjob/archive/2012/07/17/2595249.html