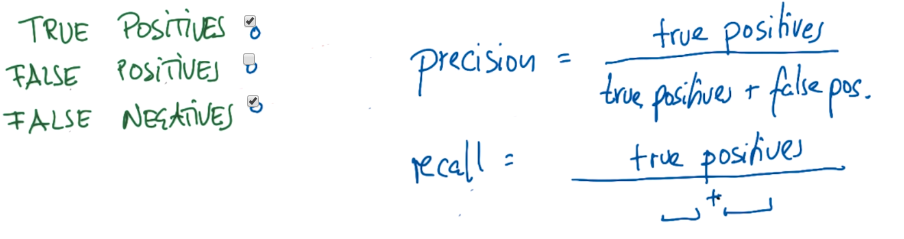选择合适的指标
在构建机器学习模型时,我们首先要选择性能指标,然后测试模型的表现如何。相关的指标有多个,具体取决于我们要尝试解决的问题。
在可以选择性能指标之前,首先务必要认识到,机器学习研究的是如何学习根据数据进行预测。对于本课程和后续的“监督式机器学习”课程,我们将重点关注那些创建分类或创建预测回归类型的已标记数据。
此外,在测试模型时,也务必要将数据集分解为训练数据和测试数据。如果不区分训练数据集和测试数据集,则在评估模型时会遇到问题,因为它已经看到了所有数据。我们需要的是独立的数据集,以确认模型可以很好地泛化,而不只是泛化到训练样本。在下一课中,我们将探讨模型误差的一些常见来源,并介绍如何正确分解本课程的“数据建模和验证”部分中的数据集。

分类指标与回归指标
在分类中,我们想了解模型隔多久正确或不正确地识别新样本一次。而在回归中,我们可能更关注模型的预测值与真正值之间差多少。
在本节课的余下部分,我们会探讨几个性能指标。对于分类,我们会探讨准确率、精确率、召回率和 F 分数。对于回归,我们会探讨平均绝对误差和均方误差。



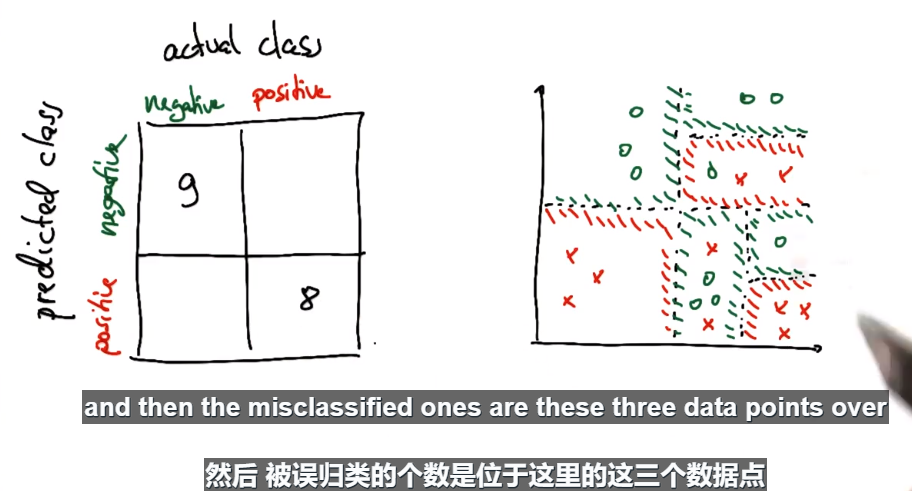
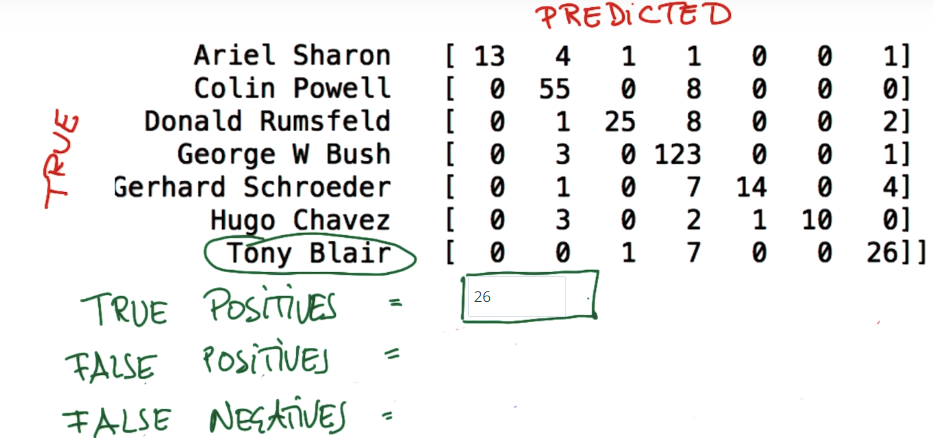
准确率实际上是所有被正确标示的数据点除以所有的数据点。如果你是在看特定类的表现,我们需要看召回率(recall),这在后面的课程中会讲到。

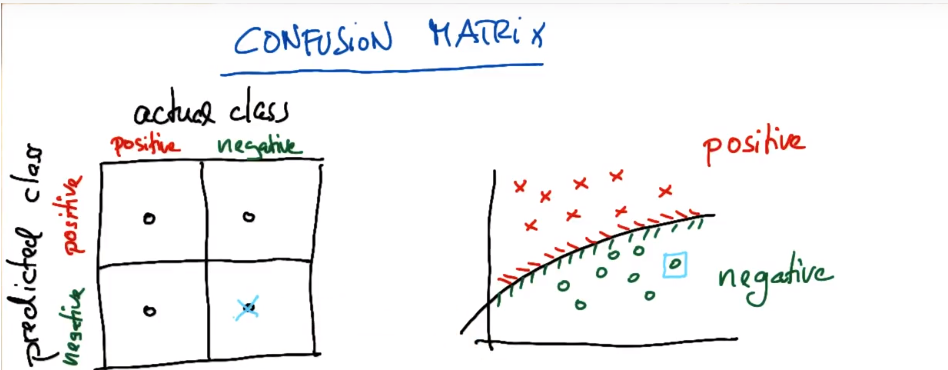

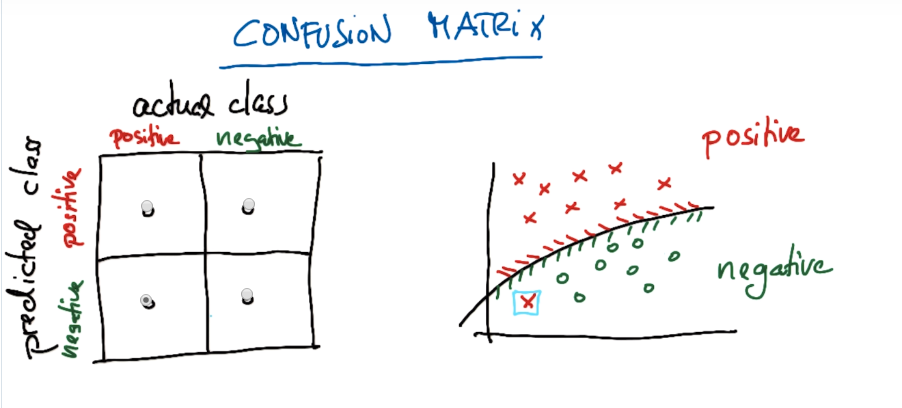
真阳性。真实是positive而被预测的是negtive。

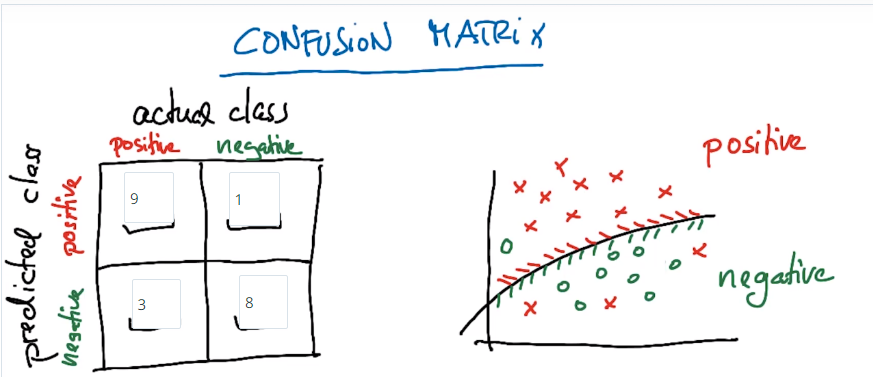

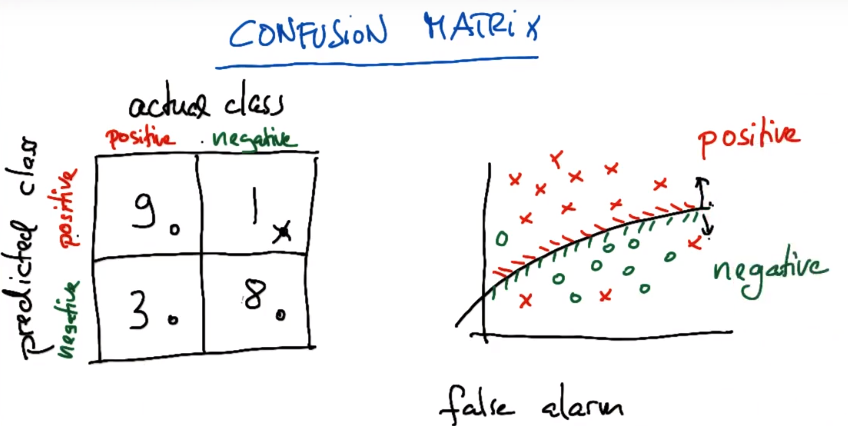
可通过调节参数来使曲线偏移。