这里只选取视频中的部分,详细资料还是去Datacastle下载看吧
数据清理的一些内容:

格式转换:
比如Excel和数据库中关于时间的记录;它是字符串的格式来进行保存的,如果想对时间进行一些运算的话,就必须利用Python里的一些包。
缺失数据:
可以说是数据清理的最重要的一个问题。
那么,如何应对数据缺失问题呢?

利用平均值、最常出现的值进行填充。(这是非常大的一个研究的方向)
异常数据:
出现不符合常识的数值
标准化:

数据清理实践
需要的包:
pandas:pip install pandas
seaborn:pip install seaborn


介绍了:
user.describe
user.shape
user.loc等待方法
数据清理:
to_datetime方法转换成日期类型

日期相减:


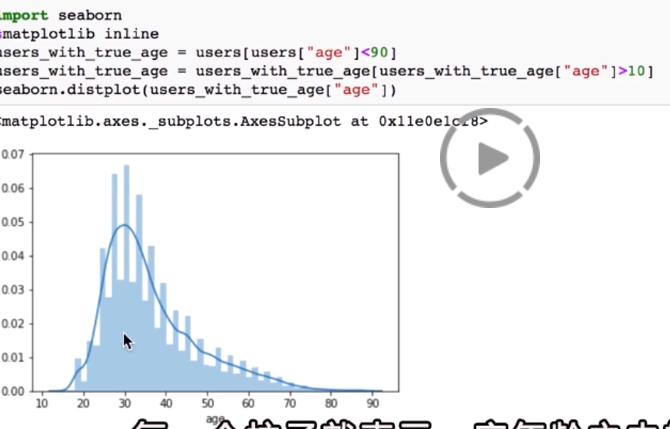
处理age异常:
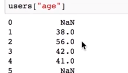
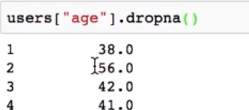
利用dropna()方法去掉NaN
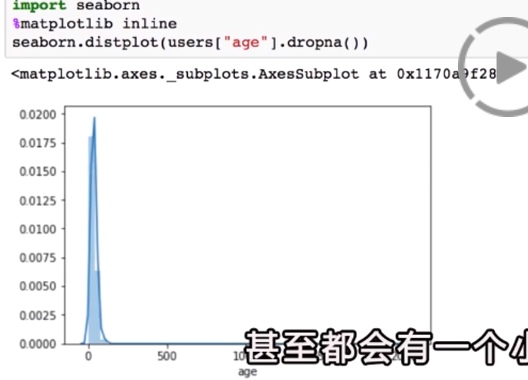
绘制平均值的图:

只取年龄<90岁的人
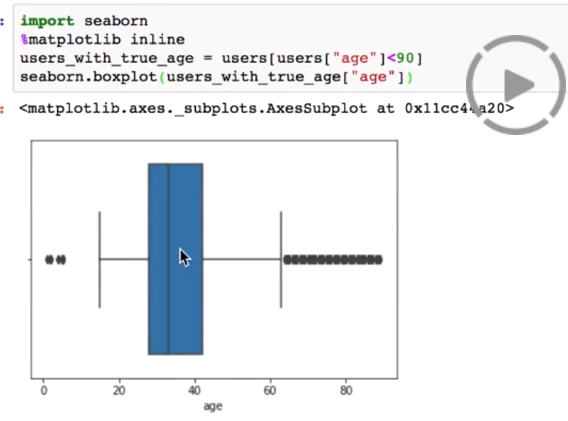
由于很多都<10岁,不符合实际。再取年龄>10岁的

柱状图